B树索引
B树索引作为数据库内最常用,也是最重要的索引,在查询优化,大表治理等工作中,都需要了解其机制和原理。
树型数据结构概述
本章节参考 Introduction to Tree Data Structure
- 如果你对树型数据结构由足够的基础知识,可以跳过本章节。
为了高效使用数据,计算机在组织和存储数据时,必须使用某种数据结构来实现。比如常见的stack,link list,queue
一样的,树型数据结构也是一种数据结构。它由中心节点central node,结构节点structural nodes和子节点sub nodes组成。
另外一个说法是,树型结构由根root,分支branches,和彼此连接的叶子leaves组合而成
树是非线性non-linear的数据结构,树是一个层次化的数据结构,由一组节点组成,每个节点存储一个值。一组对节点的引用子节点
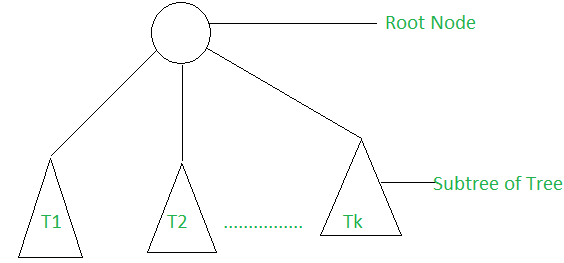
递归定义: 一棵树由一个根和零个或更多的子树 t 1,t 2,... ,Tk 组成,这样从树的根到每个子树的根都有一个边。
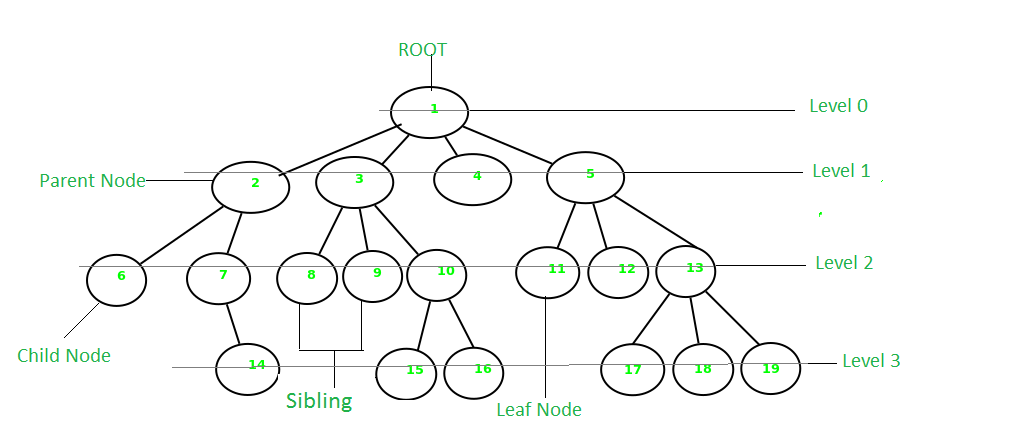
树型数据结构的基本术语
-
Parent Node
父节点。节点的前置节点称为该节点的父节点
-
Child Node
子节点。作为节点直接后续节点的节点称为该节点的子节点
-
Root Node
根节点。非空树必须恰好包含一个根节点和一条从根到树的所有其他节点的路径
-
Degree of a Node
节点的度。
连接到该节点的子树的总数量称为该节点的度数。叶节点
leaf node的度必须是0树的度是树中所有节点中拥有最大度数的节点的度。(有点绕口~)
-
Leaf Node or External Node
没有任何子节点的节点称为
叶节点 -
Ancestor of a Node
先辈节点。该节点到根的路径上的任何前置节点都称为该节点的先辈
-
Descendant
后代节点。从叶节点到该节点的路径上的任何后继节点
-
Sibling
兄弟节点。同一个父节点的子节点称为兄弟节点
-
Depth of a node
节点深度。从根到节点的边数。叫做节点的深度
-
Height of a node
节点高度。从该节点到叶子的最长路径上的边数,叫做节点高度
-
Height of a tree
树的高度。树的高度是
根节点的高度,即从根到最深节点的边数。 -
Level of a node
节点层级。从根节点到该节点的路径上的边数.根节点的层级是0
-
Internal node
内部节点。至少有一个子节点的节点称为内部节点
-
Neighbour of a Node
相邻节点。该节点的父节点或子节点称为该节点的相邻节点。
-
Subtree
子树。树的任何节点及其后代
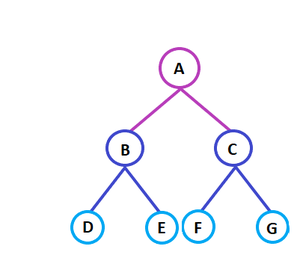
以下图为例:
此例中,
- A是根节点
- B是D和E的父节点
- D和E是兄弟节点
- D,E,F是叶子节点
- A和B是E的先辈节点
树型结构的数据类型
-
普通树
普通的树型数据结构对节点数没有限制。这意味着父节点可以有任意数量的子节点。
-
二叉树
二叉树的一个节点最多可以有两个子节点。
-
平衡树
如果
左子树和右子树的树高相等或最多相差1,则该树称为平衡树数据结构。 -
二叉查找树
顾名思义,二叉搜索树用于各种搜索和排序算法。这些例子包括 ``AVL 树
和红黑树`。它是一种非线性的数据结构。
结果表明,左节点的值小于其父节点,而右节点的值大于其父节点。
这也是本文要在下文中着重讲述的树类型。
树型结构的属性
- 对于 n 个节点,树的边等于(n-1)
- 树型结构中的箭头表示路径。每条边连接两个节点。
- 树图的任意两个节点或顶点正好由一条边连接
- 节点的深度定义为从根节点到节点 a 的路径长度。节点“ a”的高度是从节点“ a”到给定树的叶节点的最长路径。
树型数据结构的应用
-
Spanning trees
生成树算法
在图论的数学领域中,如果连通图G的一个子图是一棵包含G的所有顶点的树,则该子图称为G的生成树(SpanningTree)
- 若G是强连通的有向图,则从其中任一顶点v出发,都可以访问遍G中的所有顶点,从而得到以v为根的生成树。
- 若G是有根的有向图,设根为v,则从根v出发可以完成对G的遍历,得到G的以v为根的生成树。
- 若G是非连通的无向图,则要若干次从外部调用DFS(或BFS)算法,才能完成对G的遍历。每一次外部调用,只能访问到G的一个连通分量的顶点集,这些顶点和遍历时所经过的边构成了该连通分量的一棵DFS(或BPS)生成树。G的各个连通分量的DFS(或BFS)生成树组成了G的DFS(或BFS)生成森林。
- 若G是非强连通的有向图,且源点又不是有向图的根,则遍历时一般也只能得到该有向图的生成森林。
网络G表示n各城市之间的通信线路网线路(其中顶点表示城市,边表示两个城市之间的通信线路,边上的权值表示线路的长度或造价。可通过求该网络的最小生成树达到求解通信线路或总代价最小的最佳方案。(电力网络这种强连接的拓扑,更适合这种算法)
-
Binary Search Tree
二叉搜索树
它是一种帮助维护排序后的数据流的树型数据结构。(本文讲述的对象)
-
Storing hierarchical data
存储分层数据
树型数据结构用于存储层次化数据,即按顺序排列的数据。
-
Syntax tree
语法树
语法树表示程序源代码的结构,它在编译器中使用。
-
Trie
单词字典树
这是一种快速有效的动态拼写检查方法。它还用于从集合中定位特定的键。
前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
-
Heap
堆
它也是一个树型数据结构,可以用数组的形式表示。它用于实现优先级队列。
树堆(英语:Treap),是有一个随机附加域满足堆的性质的二叉搜索树,其结构相当于以随机数据插入的二叉搜索树。相对于其他的平衡二叉搜索树,Treap的特点是实现简单,且能基本实现随机平衡的结构。
B树是什么以及它是如何运作的
经过第一部分的介绍,大家已经对树这种数据结构有了初步认识。那么下面可以我们就进入正题,介绍本文中非常重要,非常核心的对象,B树
这部分为了加深对B树概念的理解,将引入python对相关概念进行实现。
什么是B树
B树首先是一种数据结构,它将数据存放于节点之中,并且按照顺序排序。如下图
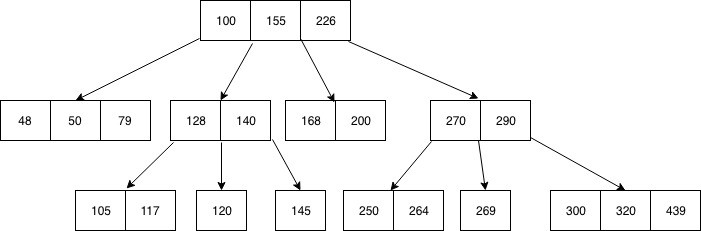
B 树存储数据,使每个节点按升序包含键。
每个键都有对另外两个子节点的引用。左侧子节点键小于当前键,右侧子节点键大于当前键。
如果一个节点有n个键,那么它可以有最大的n + 1子节点。
数据库中为什么要使用索引
现在假设,需要在文件中存储一个数字列表。需要在这个列表中搜索一个指定的数字。
最简单的办法是在数组Array中存储数据,并且在新值出现的时候,追加值。
但是,如果需要检查数组中是否存在给定值,那么需要逐个搜索所有数组元素,并检查给定值是否存在。
如果足够幸运,您可以在第一个元素中找到给定的值。
在最坏的情况下,该值可以是数组中的最后一个元素。
针对这个问题应当如何改进呢?
最简单的一种解决方案是对数组进行排序,并且进行二分查找binary search。
无论何时向数组中插入一个值,它都应该保持整个数组的顺序。
从数组中间选择一个值开始搜索。然后比较选定值和搜索值。
如果选中的值大于搜索值,请忽略数组的左侧,并在右侧搜索该值,反之亦然。
二分查找算法的示例

上图中,我们打算在Arrary({3,6,8,11,15,18})这个数组中查找15这个数字,它们已经按照排序顺序排列。
如果你做一次普通的搜索,那么它将花费5个单位的时间来搜索,因为元素在第5个位置。
但是使用二分查找,只需要3次搜索。
对数组中所有元素进行二分查找,如下图
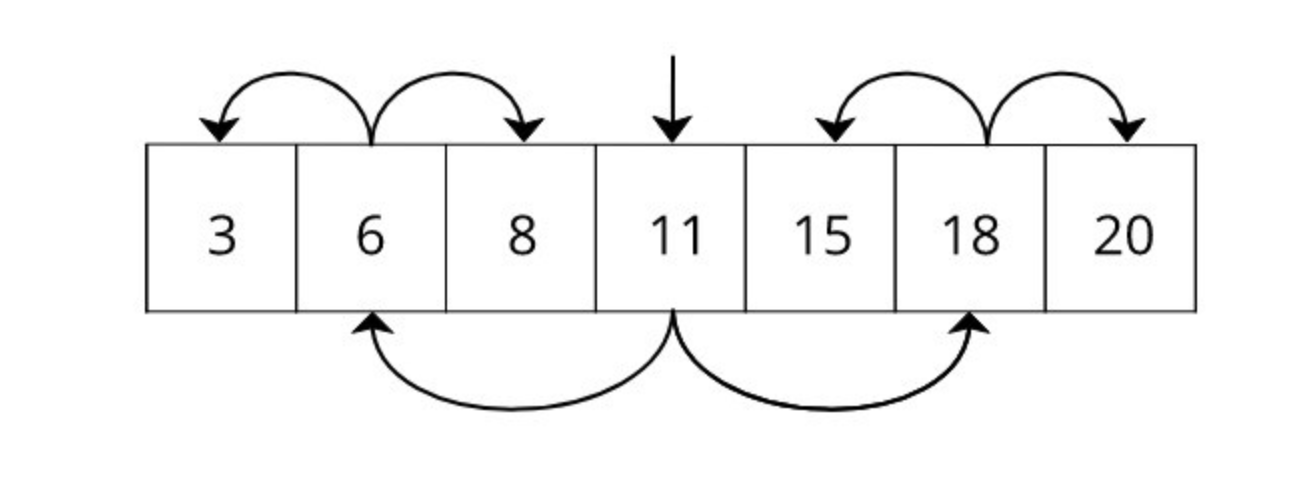
看起来非常眼熟,嗯,它是一棵二叉树。这是 b 树的最简单形式。
对于二叉树,我们可以使用指针来代替将数据保存在有序数组中。
数学上,我们可以证明二叉树的最坏情况搜索时间是O(log(n))
二叉树的概念可以扩展为一种更广义的形式,即B树
与对单个节点使用单个键值对Entry不同,b 树对单个节点使用一组键值对,并对每个节点的子节点进行引用
-
各种算法的时间复杂度
type insert delete lookup 未排序数组 O(1) O(n) O(n) 排序数组 O(n) O(n) O(log(n)) B树 O(log(n)) O(log(n)) O(log(n))
为了更好的理解二叉树,大家可以通过点击下方连接来进行操作。
B+ 树
B + 树是另一种用于存储数据的数据结构,它看起来几乎与 b 树相同。
B + 树的唯一区别是它将数据存储在叶节点上。
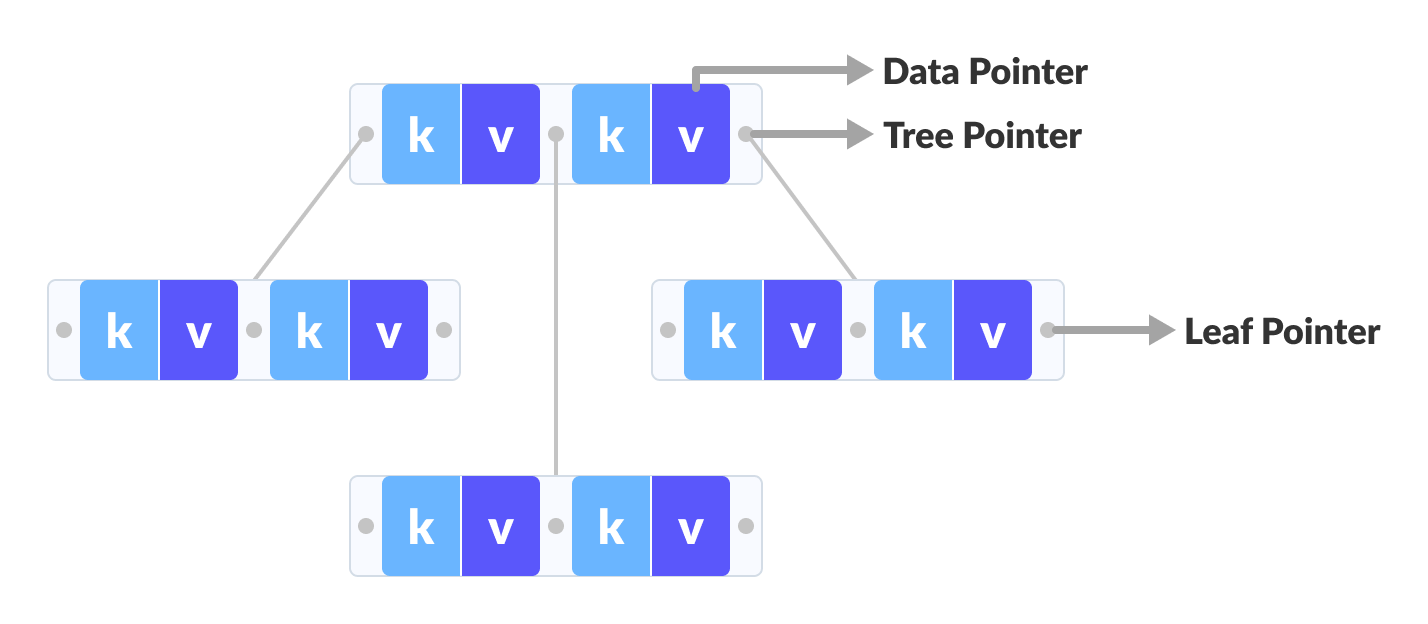
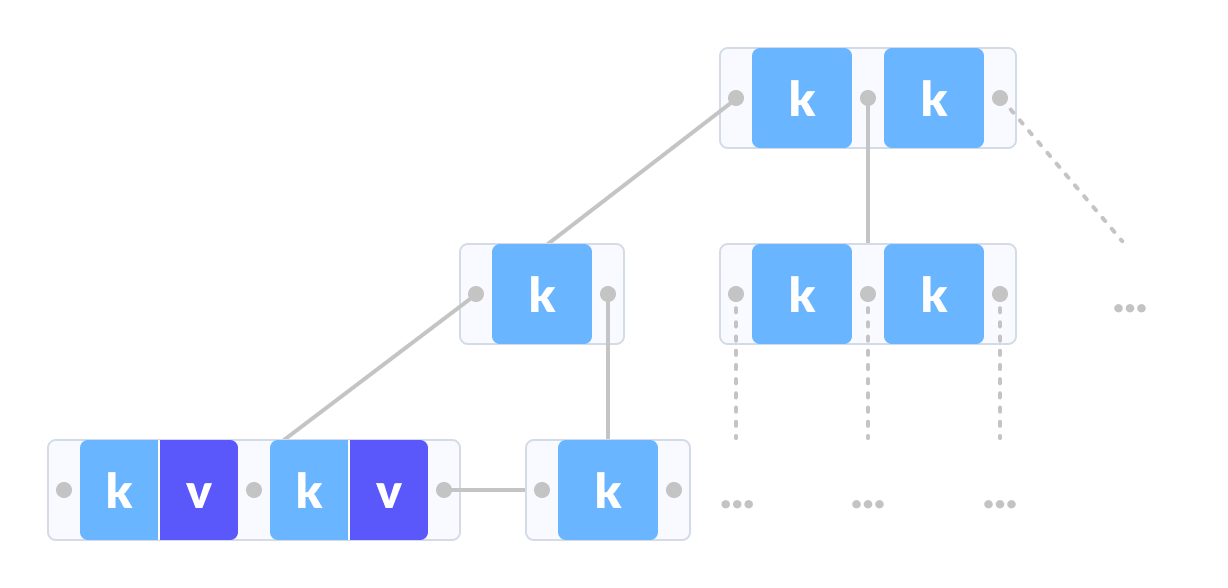
这意味着所有的非叶节点值将再次重复到叶节点中。下面是一个 b + 树的例子。
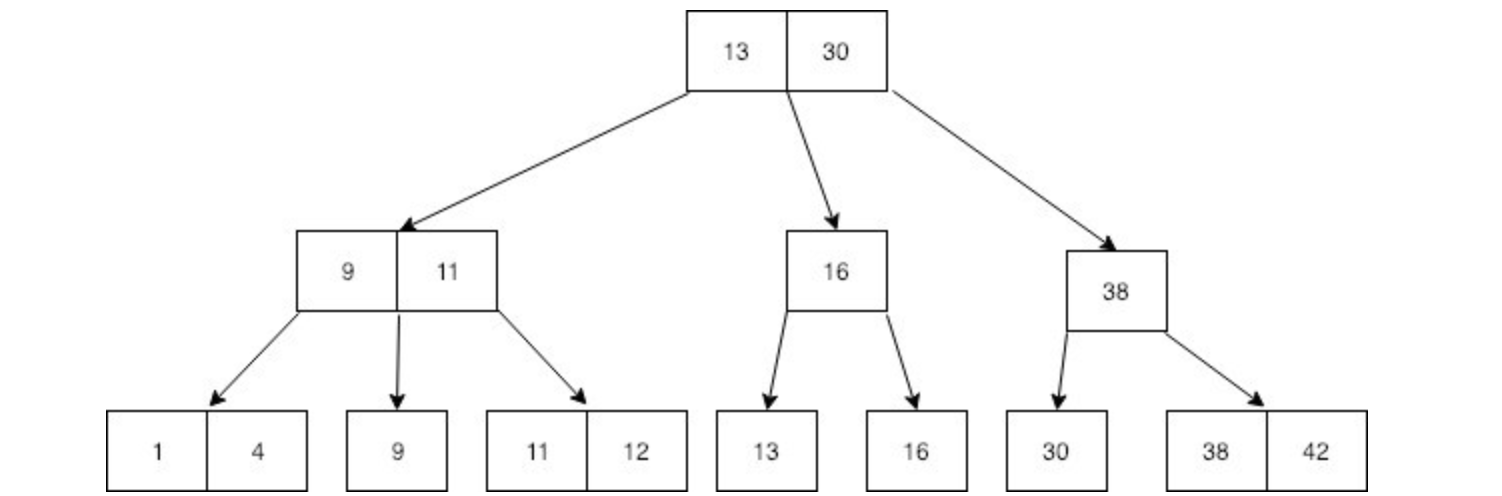

13、30、9、11、16和38个非叶节点值在叶节点中重复出现。你能看到这棵树在叶节点上的特性吗?
是的,叶节点包括所有的值,并且所有的记录都是按照排序的顺序。
在 b + 树的专长是,你可以做相同的搜索,作为 b 树
另外,你可以遍历叶节点中的所有值。如下图
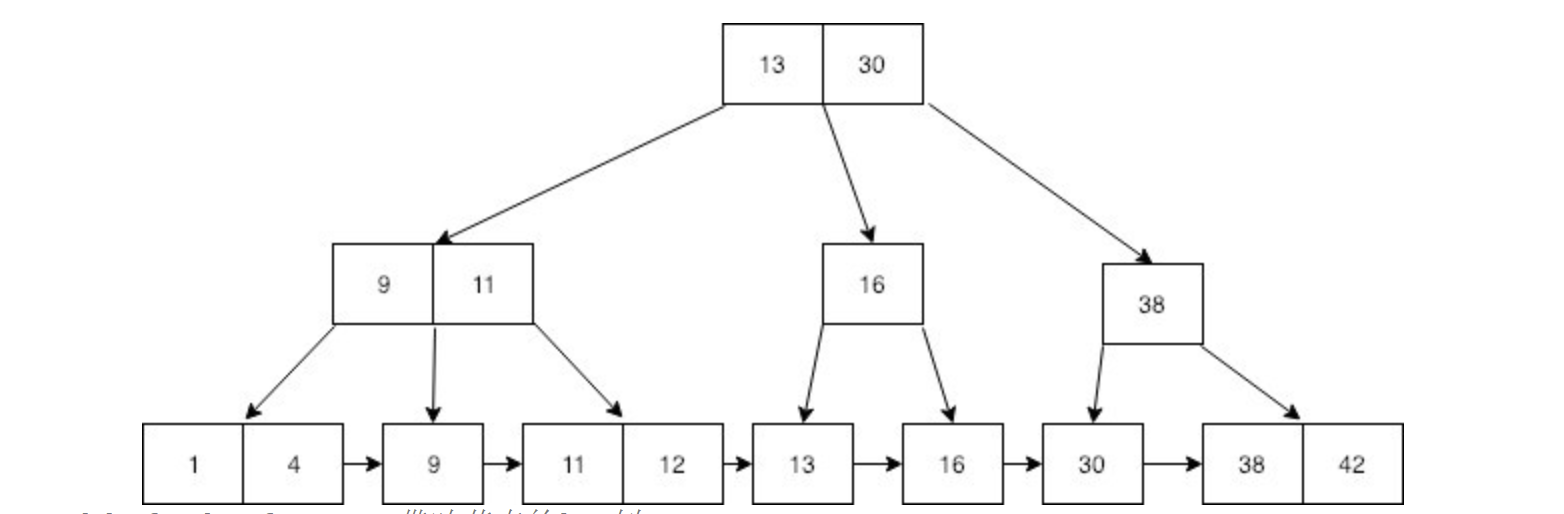
上图显示的是最大度数为2的B+树。
为了熟悉B+树的各种操作,可以点击以下连接进行操作。
数据库的索引是如何运作的
当 b 树用于数据库索引时,这种数据结构变得有点复杂,因为它不仅有一个键,而且还有一个与键相关联的值。此值是对实际数据记录的引用。
键和值一起称为负载Payload。鉴于这个原因,数据库采用的是B+树,而非B树。
下面的例子中,有三列需要存储在数据库中
| Name | Mark | Age |
|---|---|---|
| Jone | 5 | 28 |
| Alex | 32 | 45 |
| Tom | 37 | 23 |
| Ron | 87 | 13 |
| Mark | 20 | 48 |
| Bob | 89 | 32 |
- 首先,数据库为每条记录创建主键索引。并将相关行转换为字节流(一般是元组形式)。
- 然后,它将每个键存储在一个 b + 树中,并记录字节流。
- 键和记录字节流被称为负载
上例中的表,通过B+树,存储示意图如下:
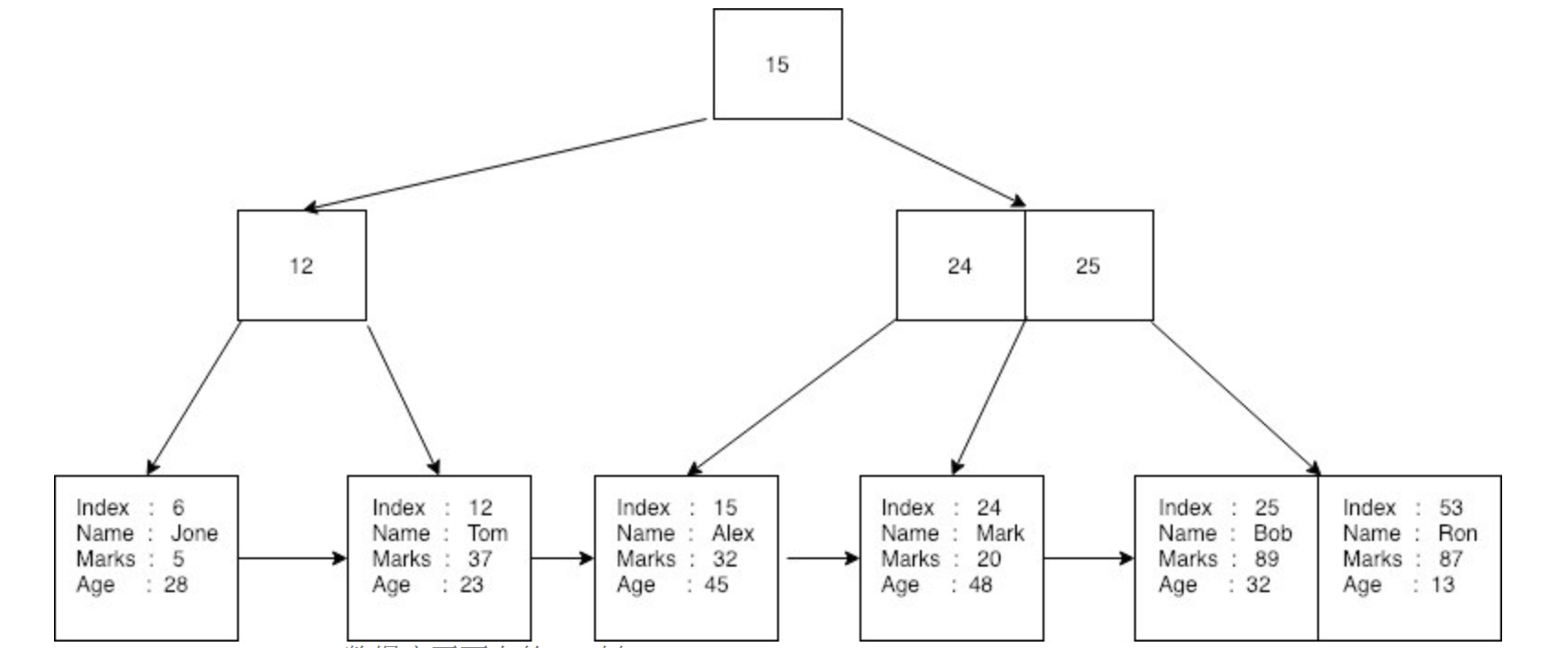
由上图可以知道,所有数据都被存放在B+树的叶子节点中。
索引用作创建 b + 树的键Key,非叶节点上不存储任何记录。
每个叶节点都有对树中下一条记录的引用。数据库可以使用索引或线性搜索进行二分查找,只需遍历叶节点即可搜索每个元素。
如果不使用索引,那么数据库将读取每条记录以查找给定的记录。
启用非主键索引时,数据库为表中的每个列创建三个 b 树,如下所示。这里的键是 b 树键用于索引。索引是对实际数据记录的引用。
如下所示。这里的键是 b 树键用于索引。索引是对实际数据记录的引用(以Name 字段为例)。
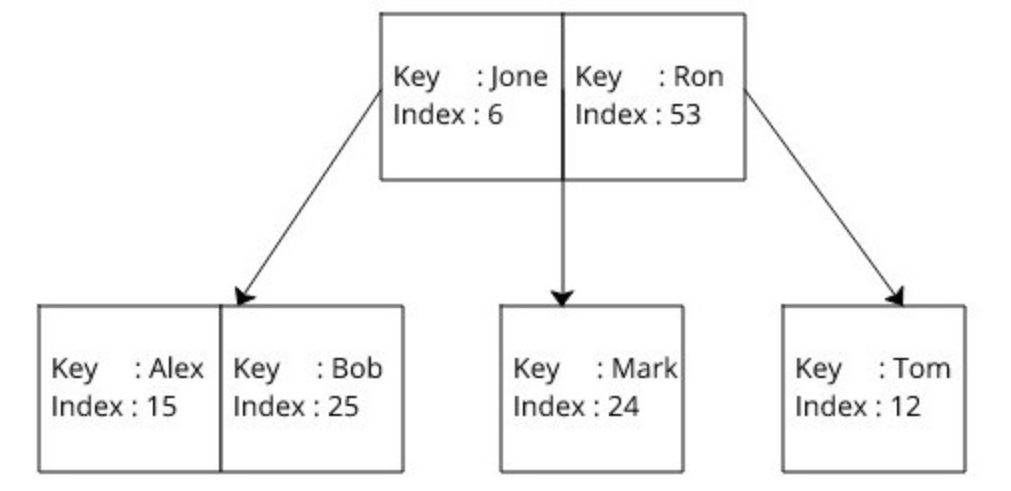
首先使用索引时,数据库在与 b 树的对应关系中搜索给定的键,并获得以O (log (n))的时间复杂度的索引。
然后,在O(log (n))时间中已经找到的索引在 b + 树中执行另一次搜索,并获取记录。
B 树和 b + 树中的每个节点都存储在 Pages 中,页面大小是固定的(
- 可在数据库配置项配置,一般是和系统缓冲区的Pages设置成相同大小即可。
- 还有
Huge Page的设置,这里篇幅有限,在后续的文章中将集中讲讲inux大页。
页面有一个唯一的编号。一个页面可以通过使用页码作为另一个页面的引用。
数据库中可以有两种类型的页面:
- 索引页面: 这些页面只存储索引和对另一个页面的引用。
- 页面存储记录: 这些页面存储的实际数据和指向叶节点页面(存储数据)的页面(父节点的Key)
结束语
数据库应该有一种存储、读取和修改数据的有效方法。
B 树提供了一种高效的数据插入和读取方法。
在实际的数据库实现中,数据库同时使用 b 树和 b + 树来存储数据。
-
这里是许多同学容易搞错的地方,认为数据库就应该使用B+树索引,而不用B树索引。
比如联合索引
Composite Index,对于每个索引列,都存在一棵B树。
B 树用于索引,b + 树用于存储实际记录。
树除了提供二分查找功能外,还提供线性搜索搜索功能,使数据库能够更好地控制数据库中非索引值的搜索。
python语言实现B+树
最后奉上Python语法的B+树实现,有兴趣的可以看看。
# B+ tee in python
import math
# Node creation
class Node:
def __init__(self, order):
self.order = order
self.values = []
self.keys = []
self.nextKey = None
self.parent = None
self.check_leaf = False
# Insert at the leaf
def insert_at_leaf(self, leaf, value, key):
if (self.values):
temp1 = self.values
for i in range(len(temp1)):
if (value == temp1[i]):
self.keys[i].append(key)
break
elif (value < temp1[i]):
self.values = self.values[:i] + [value] + self.values[i:]
self.keys = self.keys[:i] + [[key]] + self.keys[i:]
break
elif (i + 1 == len(temp1)):
self.values.append(value)
self.keys.append([key])
break
else:
self.values = [value]
self.keys = [[key]]
# B plus tree
class BplusTree:
def __init__(self, order):
self.root = Node(order)
self.root.check_leaf = True
# Insert operation
def insert(self, value, key):
value = str(value)
old_node = self.search(value)
old_node.insert_at_leaf(old_node, value, key)
if (len(old_node.values) == old_node.order):
node1 = Node(old_node.order)
node1.check_leaf = True
node1.parent = old_node.parent
mid = int(math.ceil(old_node.order / 2)) - 1
node1.values = old_node.values[mid + 1:]
node1.keys = old_node.keys[mid + 1:]
node1.nextKey = old_node.nextKey
old_node.values = old_node.values[:mid + 1]
old_node.keys = old_node.keys[:mid + 1]
old_node.nextKey = node1
self.insert_in_parent(old_node, node1.values[0], node1)
# Search operation for different operations
def search(self, value):
current_node = self.root
while(current_node.check_leaf == False):
temp2 = current_node.values
for i in range(len(temp2)):
if (value == temp2[i]):
current_node = current_node.keys[i + 1]
break
elif (value < temp2[i]):
current_node = current_node.keys[i]
break
elif (i + 1 == len(current_node.values)):
current_node = current_node.keys[i + 1]
break
return current_node
# Find the node
def find(self, value, key):
l = self.search(value)
for i, item in enumerate(l.values):
if item == value:
if key in l.keys[i]:
return True
else:
return False
return False
# Inserting at the parent
def insert_in_parent(self, n, value, ndash):
if (self.root == n):
rootNode = Node(n.order)
rootNode.values = [value]
rootNode.keys = [n, ndash]
self.root = rootNode
n.parent = rootNode
ndash.parent = rootNode
return
parentNode = n.parent
temp3 = parentNode.keys
for i in range(len(temp3)):
if (temp3[i] == n):
parentNode.values = parentNode.values[:i] +
[value] + parentNode.values[i:]
parentNode.keys = parentNode.keys[:i +
1] + [ndash] + parentNode.keys[i + 1:]
if (len(parentNode.keys) > parentNode.order):
parentdash = Node(parentNode.order)
parentdash.parent = parentNode.parent
mid = int(math.ceil(parentNode.order / 2)) - 1
parentdash.values = parentNode.values[mid + 1:]
parentdash.keys = parentNode.keys[mid + 1:]
value_ = parentNode.values[mid]
if (mid == 0):
parentNode.values = parentNode.values[:mid + 1]
else:
parentNode.values = parentNode.values[:mid]
parentNode.keys = parentNode.keys[:mid + 1]
for j in parentNode.keys:
j.parent = parentNode
for j in parentdash.keys:
j.parent = parentdash
self.insert_in_parent(parentNode, value_, parentdash)
# Delete a node
def delete(self, value, key):
node_ = self.search(value)
temp = 0
for i, item in enumerate(node_.values):
if item == value:
temp = 1
if key in node_.keys[i]:
if len(node_.keys[i]) > 1:
node_.keys[i].pop(node_.keys[i].index(key))
elif node_ == self.root:
node_.values.pop(i)
node_.keys.pop(i)
else:
node_.keys[i].pop(node_.keys[i].index(key))
del node_.keys[i]
node_.values.pop(node_.values.index(value))
self.deleteEntry(node_, value, key)
else:
print("Value not in Key")
return
if temp == 0:
print("Value not in Tree")
return
# Delete an entry
def deleteEntry(self, node_, value, key):
if not node_.check_leaf:
for i, item in enumerate(node_.keys):
if item == key:
node_.keys.pop(i)
break
for i, item in enumerate(node_.values):
if item == value:
node_.values.pop(i)
break
if self.root == node_ and len(node_.keys) == 1:
self.root = node_.keys[0]
node_.keys[0].parent = None
del node_
return
elif (len(node_.keys) < int(math.ceil(node_.order / 2)) and node_.check_leaf == False) or (len(node_.values) < int(math.ceil((node_.order - 1) / 2)) and node_.check_leaf == True):
is_predecessor = 0
parentNode = node_.parent
PrevNode = -1
NextNode = -1
PrevK = -1
PostK = -1
for i, item in enumerate(parentNode.keys):
if item == node_:
if i > 0:
PrevNode = parentNode.keys[i - 1]
PrevK = parentNode.values[i - 1]
if i < len(parentNode.keys) - 1:
NextNode = parentNode.keys[i + 1]
PostK = parentNode.values[i]
if PrevNode == -1:
ndash = NextNode
value_ = PostK
elif NextNode == -1:
is_predecessor = 1
ndash = PrevNode
value_ = PrevK
else:
if len(node_.values) + len(NextNode.values) < node_.order:
ndash = NextNode
value_ = PostK
else:
is_predecessor = 1
ndash = PrevNode
value_ = PrevK
if len(node_.values) + len(ndash.values) < node_.order:
if is_predecessor == 0:
node_, ndash = ndash, node_
ndash.keys += node_.keys
if not node_.check_leaf:
ndash.values.append(value_)
else:
ndash.nextKey = node_.nextKey
ndash.values += node_.values
if not ndash.check_leaf:
for j in ndash.keys:
j.parent = ndash
self.deleteEntry(node_.parent, value_, node_)
del node_
else:
if is_predecessor == 1:
if not node_.check_leaf:
ndashpm = ndash.keys.pop(-1)
ndashkm_1 = ndash.values.pop(-1)
node_.keys = [ndashpm] + node_.keys
node_.values = [value_] + node_.values
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
p.values[i] = ndashkm_1
break
else:
ndashpm = ndash.keys.pop(-1)
ndashkm = ndash.values.pop(-1)
node_.keys = [ndashpm] + node_.keys
node_.values = [ndashkm] + node_.values
parentNode = node_.parent
for i, item in enumerate(p.values):
if item == value_:
parentNode.values[i] = ndashkm
break
else:
if not node_.check_leaf:
ndashp0 = ndash.keys.pop(0)
ndashk0 = ndash.values.pop(0)
node_.keys = node_.keys + [ndashp0]
node_.values = node_.values + [value_]
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
parentNode.values[i] = ndashk0
break
else:
ndashp0 = ndash.keys.pop(0)
ndashk0 = ndash.values.pop(0)
node_.keys = node_.keys + [ndashp0]
node_.values = node_.values + [ndashk0]
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
parentNode.values[i] = ndash.values[0]
break
if not ndash.check_leaf:
for j in ndash.keys:
j.parent = ndash
if not node_.check_leaf:
for j in node_.keys:
j.parent = node_
if not parentNode.check_leaf:
for j in parentNode.keys:
j.parent = parentNode
# Print the tree
def printTree(tree):
lst = [tree.root]
level = [0]
leaf = None
flag = 0
lev_leaf = 0
node1 = Node(str(level[0]) + str(tree.root.values))
while (len(lst) != 0):
x = lst.pop(0)
lev = level.pop(0)
if (x.check_leaf == False):
for i, item in enumerate(x.keys):
print(item.values)
else:
for i, item in enumerate(x.keys):
print(item.values)
if (flag == 0):
lev_leaf = lev
leaf = x
flag = 1
record_len = 3
bplustree = BplusTree(record_len)
bplustree.insert('5', '33')
bplustree.insert('15', '21')
bplustree.insert('25', '31')
bplustree.insert('35', '41')
bplustree.insert('45', '10')
printTree(bplustree)
if(bplustree.find('5', '34')):
print("Found")
else:
print("Not found")