Hash索引
- 注意:下文中的散列和哈希是一个意思,只不过哈希这种称呼更多的用于计算机这块,散列则是用于数学和密码学。
什么是hash
日常生活中,我们经常听说过哈希,哈希函数,一致性哈希算法,哈希表,哈希环。那么,哈希到底是个什么东西呢?
first of all,就像我们的helloworld举例中喜欢用到bacon,foo等一样,Hash这个词开始也不是技术用语,而是一种食物.
根据wiktionary的解释,hash有以下意思

ok,那么和哈希菜一样,hash这种技术至少有一个共同点,那就是琐碎而纷乱,你无法从碎肉和土豆块中一眼看出,原来的肉是方的,或者土豆是圆的。
哈希函数,又称散列函数Hash function,是一种从任何一种数据中创建小的数字“指纹”的方法。
散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。
该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹
散列函数具有以下特性:
-
所有散列函数都有如下一个基本特性。
如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
-
散列函数的输入和输出不是唯一对应关系的
如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为
散列碰撞或者哈希碰撞。Hash collision。 -
在密码学中,散列函数必须具有不可逆性。
散列主要有以下应用
- 保护资料
- 确保传递真实信息
- 散列表
- 错误矫正
- 语音识别
常见的散列函数算法
| 算法名称 | 输出大小(bits) | 内部大小 | 区块大小 | 长度大小 | 字符尺寸 | 碰撞情形 |
|---|---|---|---|---|---|---|
| HAVAL | 256/224/192/160/128 | 256 | 1024 | 64 | 32 | 是 |
| MD2 | 128 | 384 | 128 | No | 8 | 大多数 |
| MD4 | 128 | 128 | 512 | 64 | 32 | 是 |
| MD5 | 128 | 128 | 512 | 64 | 32 | 是 |
| PANAMA | 256 | 8736 | 256 | 否 | 32 | 是 |
| RadioGatún | 任意长度 | 58字 | 3字 | 否 | 1-64 | 否 |
| RIPEMD | 128 | 128 | 512 | 64 | 32 | 是 |
| RIPEMD-128/256 | 128/256 | 128/256 | 512 | 64 | 32 | 否 |
| RIPEMD-160/320 | 160/320 | 160/320 | 512 | 64 | 32 | 否 |
| SHA-0 | 160 | 160 | 512 | 64 | 32 | 是 |
| SHA-1 | 160 | 160 | 512 | 64 | 32 | 有缺陷 |
| SHA-256/224 | 256/224 | 256 | 512 | 64 | 32 | 否 |
| SHA-512/384 | 512/384 | 512 | 1024 | 128 | 64 | 否 |
| Tiger(2)-192/160/128 | 192/160/128 | 192 | 512 | 64 | 64 | 否 |
| WHIRLPOOL | 512 | 512 | 512 | 256 | 8 | 否 |
哈希算法比较多,而且各自的实现方法大相径庭,这里不做具体介绍。
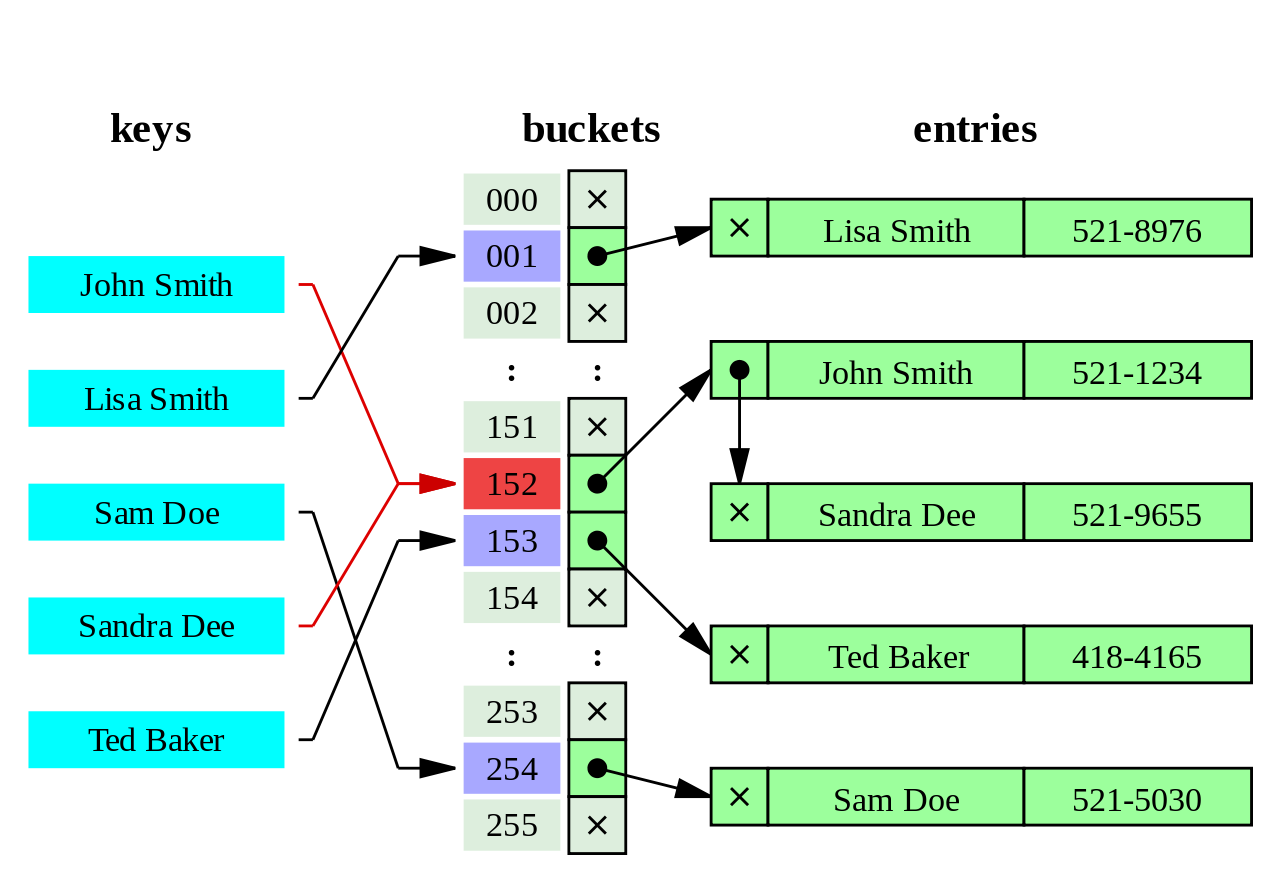
散列表
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
数组Arrary的特点是寻址容易,插入和删除比较麻烦
链表link list的特点是插入删除容易,寻址比较麻烦。
散列表hash table结合上述两者有点。哈希表有许多种不同的实现方式,这里介绍最为常见的一种,拉链法
拉链法
拉链法可以看作是带数组的链表。如下图
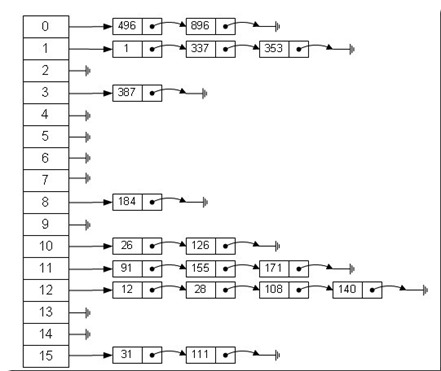
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。
我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
-
除法散列法
最直观的一种,上图使用的就是这种办法
Index = Value % 16求模
mod的本质是除法,所以这种办法叫除法散列法 -
平方散列
求index是非常频繁的操作,而乘法的运算要比除法来得省时
所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28向右移动,相当于将二进制首部向右移动,所以是变小的操作
反之向左,是变大的位操作。
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。
-
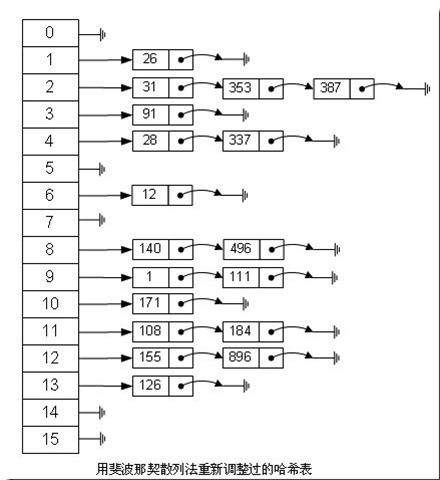
斐波那契额数列
fibonacci散列法平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?
- 对于16位整数而言,这个乘数是40503
- 对于32位整数而言,这个乘数是2654435769
- 对于64位整数而言,这个乘数是11400714819323198485
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28则上面的图就变成下面的图了
什么是hash索引
理解了上面的散列表,下面讲讲哈希索引在数据库中的原理。
这里选用的数据库类型是Postgresql。当然Oracle和Sql-server也各自实现了安全可靠的Hash Index,原理大同小异。
哈希的思想是将一个小数(从0到 n-1,总共 n 个值)与任何数据类型的值相关联。这样的映射上面已经说过,被成为散列函数。
所获得的数字通常作为数组的索引,而数组中则存放对表行table rows的引用(TIDs)。这个数组的元素称为散列表存储桶hash table buckets
如果同一个索引值出现在不同的行中,则一个存储桶可以存储多个 tid。
- 通过Hash函数计算Index Key的Hash地址
- Hash地址不同的数据行指向不同的
Bucket - Hash地址相同的数据行指向相同的Bucket,如果多个数据行的Hash地址相同,都指向同一个Bucket,那么将这些数据行链接在一起,组成一个
链表。
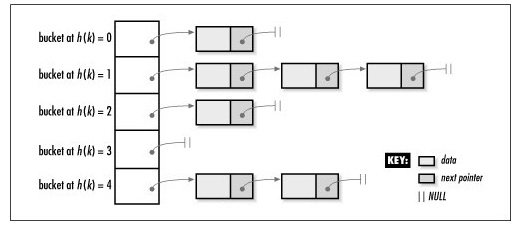
哈希函数越均匀地按桶分配源值,效果就越好。但即使是一个好的散列函数,有时也会对不同的源值产生相同的结果——这就是所谓的碰撞hash collision
因此,一个存储桶可以存储对应于不同键的 tid,因此,需要重新检查从索引获得的 tid。
事实上目前主流的数据库内实现的哈希函数,分布都服从泊松分布
如果你对Pg如何实现哈希函数感兴趣,可以参考它的原码 hashfunc.c中的 hash_any () 部分。
当有数据插入到有hash索引的字段时,需要通过哈希函数进行计算。
PostgreSQL 中的散列函数总是返回integer类型,它的范围介于$2^{32}$,约等于40亿之间。桶的大小最初等于2,然后动态增加。
桶的数量可以通过哈希代码中的位运算bit arithmetic来计算。而这就是存放我们TID的桶。
但这是不够的,因为可以将匹配不同键的 tid 放入同一个桶中。
我们该怎么办?除了 TID 之外,还可以将键的源值存储在 bucket 中,但这会大大增加索引大小。
为了节省空间,bucket 存储的不是Key,而是Key的散列码。
然而,两个不同的Keys有可能不仅进入同一个存储桶,而且具有相同的四字节哈希码。这种情况是确实存在的,而且无法避免。
因此,访问方法要求常规索引引擎通过重新检查表行中的条件来验证每个 TID (引擎可以在进行可见性检查visibility check的同时进行此检查)。
如果我们从缓冲区缓存管理器buffer cache manager的角度而不是从查询规划query planning和执行execution的角度来看索引,那么结果是所有信息和所有索引行都必须打包到页page中。这样的索引页存储在缓冲区缓存中,并以与表页完全相同的方式从缓存中逐出evicted(clock sweep 算法)。
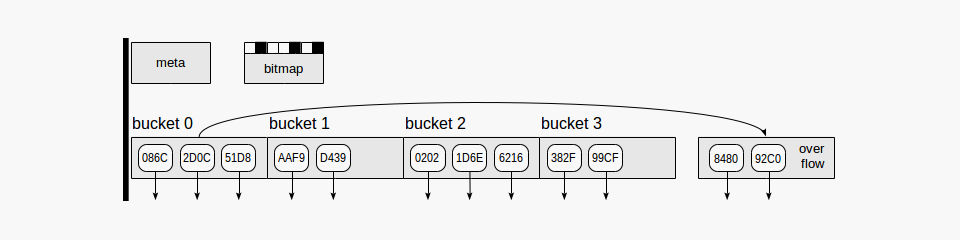
如图所示,哈希索引使用四种页(灰色矩形)。
-
Meta page
元页面-页码为零,其中包含索引内容的信息
-
Bucket pages
桶页面-索引的主页面,将数据存储为
hash code-TID对 -
Overflow pages
溢出页面--结构与桶页面相同,当一个页面不够用时使用
-
Bitmap pages
位图页面——跟踪当前清除并被其他桶拒绝的溢出页面
从索引页元素开始的向下箭头表示 tid,即对表行的引用。
之前,每次索引增加时,PostgreSQL 会立即创建两倍大小于上次创建的存储桶(也就是页)。为了避免立刻新增大量的页面,版本10使索引容量增加更加平滑。
至于溢出页面,它们会根据需要被分配,并在位图页面中被跟踪,也会根据需要被分配。
-
注意:哈希索引的大小不能减小。
如果我们删除一些索引行,那么相关的页面将不会释放回到操作系统,而只会在清空之后重新用于新数据。
减小索引大小的唯一选择是使用
REINDEX或VACUUM FULL命令重新生成索引。
最后放张图,方便梳理
hash 索引和B树索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位。而B树索引则需要从根节点到叶节点,多次IO才能完成。所以Hash索引的效率要远高于B-tree索引。
既然Hash索引这么快,为什么在数据库中创建索引,默认的是Btree 而非hash呢?
-
Hash 索引仅仅能满足
=,IN和<>查询,不能使用范围查询。由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤
-
Hash 索引无法排序操作
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,
所以数据库无法利用索引的数据来避免任何排序运算
-
Hash 索引不能利用部分索引键查询
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
-
Hash 索引在任何时候都不能避免表扫描
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
-
Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。