


进程,线程,协程是开发和运维中常常遇到的概念,本文将介绍这三个概念
进程
概念
进程(process)是操作系统对一个正在运行的程序的一种抽象,进程是资源分配的最小单位。
进程一般由程序、数据集合和进程控制块三部分组成。
程序
程序用于描述进程要完成的功能,是控制进程执行的指令集
数据集合
数据集合是程序在执行时所需要的数据和工作区,独占内存空间
进程控制块
Program Control Block,简称PCB,包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程具有的特征
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进程一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序、数据和进程控制块三部分组成。
进程间切换
在计算机中,其计算核心是 CPU,负责所有计算相关的工作和资源。单个 CPU 一次只能运行一个任务。如果一个进程跑着,就把唯一一个 CPU 给完全占住,那是非常不合理的。
如果总是在运行一个进程上的任务,就会出现一个现象。就是任务不一定总是在执行'计算型' 的任务,会有很大可能是在执行网络调用,阻塞了,CPU 岂不就浪费了?
这又出现了多进程,多个 CPU,多个进程。多进程就是指计算机系统可以同时执行多个进程,从一个进程到另外一个进程的转换是由操作系统内核管理的,一般是同时运行多个软件。
这就产生了进程的内核态,用户态,如下图
多进程的缺点
进程间的信息难以共享数据,父子进程并未共享内存,需要通过进程间通信(IPC),在进程间进行信息交换,性能开销较大。
创建进程的性能开销较大。
Python 多进程示例
import multiprocessing
import os
def square(n):
"""计算数字的平方,并打印结果"""
print(f"进程ID: {os.getpid()}, 数字: {n}, 平方: {n*n}")
if __name__ == "__main__":
# 创建一个进程池
pool = multiprocessing.Pool(processes=4)
# 要计算平方的数字列表
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用进程池并行执行任务
pool.map(square, numbers)
# 关闭进程池并等待所有任务完成
pool.close()
pool.join()
print("所有进程完成任务")
线程
多进程的缺点使得人们解决问题的目光放在了进程内部
概念
一个进程可以由多个称为线程(thread)的执行单元组成。每个线程都运行在进程的上下文中,共享着同样的代码和全局数据。
多个进程,就可以有更多的线程。多线程比多进程之间更容易共享数据,在上下文切换中线程一般比进程更高效。
线程的有点
线程之间能够非常方便、快速地共享数据。 只需将数据复制到进程中的共享区域就可以了,但需要注意避免多个线程修改同一份内存
创建线程比创建进程要快 10 倍甚至更多。 线程都是同一个进程下自家的孩子,像是内存页、页表等就不需要了。
任务调度
有资源共享的存在,就存在并发下的调度和锁机制
大部分操作系统(如Windows、Linux)的任务调度是采用时间片轮转的抢占式调度方式。
在一个进程中,当一个线程任务执行几毫秒后,会由操作系统的内核(负责管理各个任务)进行调度,通过硬件的计数器中断处理器,让该线程强制暂停并将该线程的寄存器放入内存中
通过查看线程列表决定接下来执行哪一个线程,并从内存中恢复该线程的寄存器
最后恢复该线程的执行,从而去执行下一个任务。 上述过程中,任务执行的那一小段时间叫做时间片,任务正在执行时的状态叫运行状态,被暂停的线程任务状态叫做就绪状态,意为等待下一个属于它的时间片的到来。
这种方式保证了每个线程轮流执行,由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在“同时进行”,这也就是我们所说的并发(别觉得并发有多高深,它的实现很复杂,但它的概念很简单,就是一句话:多个任务同时执行)。
线程和进程都是一种抽象的概念,线程是一种比进程更小的抽象,线程和进程都可用于实现并发。 在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。它相当于一个进程里只有一个线程,进程本身就是线程。所以线程有时被称为轻量级进程(Lightweight Process,LWP)。
多线程与多核
上面提到的时间片轮转的调度方式说一个任务执行一小段时间后强制暂停去执行下一个任务,每个任务轮流执行。很多操作系统的书都说“同一时间点只有一个任务在执行”。那有人可能就要问双核处理器呢?难道两个核不是同时运行吗?
其实同一时间点只有一个任务在执行这句话是不准确的,至少它是不全面的。那多核处理器的情况下,线程是怎样执行呢?这就需要了解内核线程。
内核线程
多核(心)处理器是指在一个处理器上集成多个运算核心从而提高计算能力,也就是有多个真正并行计算的处理核心,每一个处理核心对应一个内核线程。
内核线程(Kernel Thread,KLT)就是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操作调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。一般一个处理核心对应一个内核线程,比如单核处理器对应一个内核线程,双核处理器对应两个内核线程,四核处理器对应四个内核线程。
现在的电脑一般是双核四线程、四核八线程,是采用超线程技术将一个物理处理核心模拟成两个逻辑处理核心,对应两个内核线程,所以在操作系统中看到的CPU数量是实际物理CPU数量的两倍,如你的电脑是双核四线程,打开“任务管理器\性能”可以看到4个CPU的监视器,四核八线程可以看到8个CPU的监视器。
超线程技术就是利用特殊的硬件指令,把一个物理芯片模拟成两个逻辑处理核心,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。这种超线程技术(如双核四线程)由处理器硬件的决定,同时也需要操作系统的支持才能在计算机中表现出来。
程序一般不会直接去使用内核线程,而是去使用内核线程的一种高级接口——轻量级进程(Lightweight Process,LWP),轻量级进程就是我们通常意义上所讲的线程,也被叫做用户线程。由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。用户线程与内核线程的对应关系有三种模型:一对一模型、多对一模型、多对多模型。
线程的生命周期
当线程的数量小于处理器的数量时,线程的并发是真正的并发,不同的线程运行在不同的处理器上。但当线程的数量大于处理器的数量时,线程的并发会受到一些阻碍,此时并不是真正的并发,因为此时至少有一个处理器会运行多个线程。
在单个处理器运行多个线程时,并发是一种模拟出来的状态。操作系统采用时间片轮转的方式轮流执行每一个线程。现在,几乎所有的现代操作系统采用的都是时间片轮转的抢占式调度方式.
早期进程的生命周期
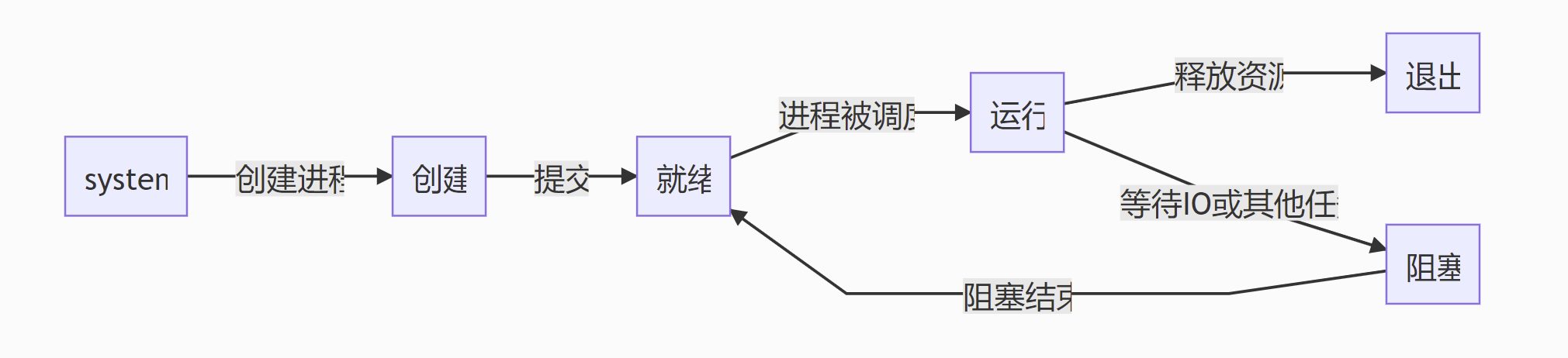
进程有五种状态,创建、就绪、运行、阻塞(等待)、退出。 早期的进程相当于现在的只有单个线程的进程。
创建
进程正在创建,还不能运行。操作系统在创建进程时要进行的工作包括分配和建立进程控制块表项、建立资源表格并分配资源、加载程序并建立地址空间;就绪
时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;运行
此线程正在执行,正在占用时间片;阻塞(等待)
也叫等待状态,等待某一事件(如IO或另一个线程)执行完;退出
进程已结束,所以也称结束状态,释放操作系统分配的资源。
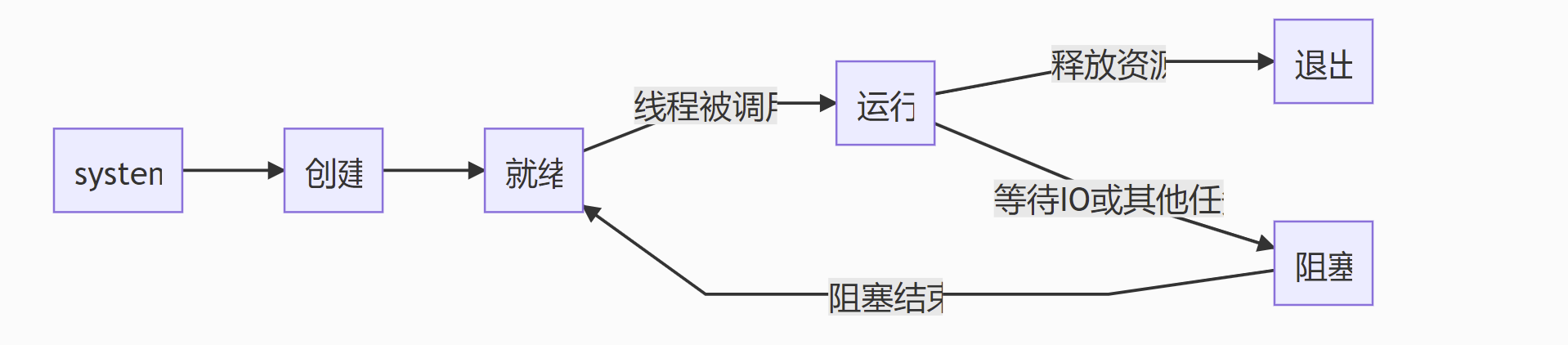
线程生命周期
创建:
一个新的线程被创建,等待该线程被调用执行;就绪:
时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;运行:
此线程正在执行,正在占用时间片;阻塞:
也叫等待状态,等待某一事件(如IO或另一个线程)执行完;退出:
一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
python中的全局锁
尽管Python完全支持多线程编程, 但是解释器的C语言实现部分在完全并行执行时并不是线程安全的。 实际上,解释器被一个全局解释器锁保护着,它确保任何时候都只有一个Python线程执行。 GIL最大的问题就是Python的多线程程序并不能利用多核CPU的优势 (比如一个使用了多个线程的计算密集型程序只会在一个单CPU上面运行)。
在讨论普通的GIL之前,有一点要强调的是GIL只会影响到那些严重依赖CPU的程序(比如计算型的)。 如果你的程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适, 因为它们大部分时间都在等待。实际上,你完全可以放心的创建几千个Python线程, 现代操作系统运行这么多线程没有任何压力,没啥可担心的。
还有一点要注意的是,线程不是专门用来优化性能的。 一个CPU依赖型程序可能会使用线程来管理一个图形用户界面、一个网络连接或其他服务。 这时候,GIL会产生一些问题,因为如果一个线程长期持有GIL的话会导致其他非CPU型线程一直等待。 事实上,一个写的不好的C语言扩展会导致这个问题更加严重, 尽管代码的计算部分会比之前运行的更快些。
python多线程示例
多进程代替多线程。
使用 multiprocessing 模块来创建一个进程池, 并像协同处理器一样的使用它
# Performs a large calculation (CPU bound)
def some_work(args):
...
return result
# A thread that calls the above function
def some_thread():
while True:
...
r = some_work(args)
...
修改代码,使用进程池:
# Processing pool (see below for initiazation)
pool = None
# Performs a large calculation (CPU bound)
def some_work(args):
...
return result
# A thread that calls the above function
def some_thread():
while True:
...
r = pool.apply(some_work, (args))
...
# Initiaze the pool
if __name__ == '__main__':
import multiprocessing
pool = multiprocessing.Pool()另外一个解决GIL的策略是使用C扩展编程技术。 主要思想是将计算密集型任务转移给C,跟Python独立,在工作的时候在C代码中释放GIL。 这可以通过在C代码中插入下面这样的特殊宏来完成:
#include "Python.h"
...
PyObject *pyfunc(PyObject *self, PyObject *args) {
...
Py_BEGIN_ALLOW_THREADS
// Threaded C code
...
Py_END_ALLOW_THREADS
...
}多线程示例
import time
def countdown(n):
while n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
# Create and launch a thread
from threading import Thread
t = Thread(target=countdown, args=(10,))
t.start()判断线程释放已经启动
from threading import Thread, Event
import time
# Code to execute in an independent thread
def countdown(n, started_evt):
print('countdown starting')
started_evt.set()
while n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
# Create the event object that will be used to signal startup
started_evt = Event()
# Launch the thread and pass the startup event
print('Launching countdown')
t = Thread(target=countdown, args=(10,started_evt))
t.start()
# Wait for the thread to start
started_evt.wait()
print('countdown is running')协程
概念
协程(Coroutine/fiber)是用户态的线程。通常创建协程时,会从进程的堆中分配一段内存作为协程的栈。
线程的栈有 8 MB,而协程栈的大小通常只有 KB,而 Go 语言的协程更夸张,只有 2-4KB,非常的轻巧。
协程的优势
节省 CPU:避免系统内核级的线程频繁切换,造成的 CPU 资源浪费。好钢用在刀刃上。而协程是用户态的线程,用户可以自行控制协程的创建于销毁,极大程度避免了系统级线程上下文切换造成的资源浪费。
节约内存:在 64 位的Linux中,一个线程需要分配 8MB 栈内存和 64MB 堆内存,系统内存的制约导致我们无法开启更多线程实现高并发。而在协程编程模式下,可以轻松有十几万协程,这是线程无法比拟的。
稳定性:前面提到线程之间通过内存来共享数据,这也导致了一个问题,任何一个线程出错时,进程中的所有线程都会跟着一起崩溃。
开发效率:使用协程在开发程序之中,可以很方便的将一些耗时的IO操作异步化,例如写文件、耗时 IO 请求等。
线程和协程的区别
比较项 | 线程 | 进程 |
|---|---|---|
占用资源 | 初始单位为1MB,固定不可变 | 初始一般为 2KB,可随需要而增大 |
调度所属 | 由 OS 的内核完成 | 由用户完成 |
切换开销 | 涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP...等寄存器的刷新等 | 只有三个寄存器的值修改 - PC / SP / DX. |
性能问题 | 资源占用太高,频繁创建销毁会带来严重的性能问题 | 资源占用小,不会带来严重的性能问题 |
数据同步 | 需要用锁等机制确保数据的一直性和可见性 | 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 |
本文参考:
一文读懂什么是进程、线程、协程 Go 面试官:什么是协程,协程和线程的区别和联系?
推荐阅读: 进程与线程的一个简单解释