

Postgresql数据库维护须知
本文翻译自Everything you need to know about PostgreSQL Database Maintenance
介绍
我们经常听到“数据库维护”这个术语。那么它到底是什么呢?所有事物都需要有效的维护,包括您的数据库。定期维护有助于数据库正常运行并高效执行,以满足您的业务期望。数据库维护描述了一组旨在改进数据库的任务。这些常规任务旨在提高性能、释放磁盘空间、检查数据错误、硬件故障、更新内部统计数据以及许多其他不明显(但通常重要)的事项。
数据库维护在日常PostgreSQL操作中是一个高度被忽视的话题。虽然人们普遍认为数据库备份需要定期和基本地进行,但只有少数用户意识到额外的工作。一种主要的原因是,许多人没有深入了解SQL本身,并且无法有效地执行这些任务。
有时,数据库维护如果做得不当可能不会引起注意,但当数据库性能受到影响时,就会变成一个真正的问题。
这本白皮书将带您了解常见的Postgresql数据库维护任务。
关键要点:
Vacuum 过程 在 PostgreSQL 中,vacuum 负责清理死行或死元组的工作。这类似于对死行/元组进行碎片整理的活动,通常被称为膨胀
bloat。版本控制 PostgreSQL 通过 MVCC(多版本并发控制)维护旧元组的版本控制,以在事务中实现可见性。因此,它不会立即删除这些数据版本,而是保持这些版本,除非有人指示其删除。
auto vacuum 过程 PostgreSQL 中有一个自动 vacuum 过程,但很多时候对于特定负载,DBA 更喜欢安排这个过程以获得更好的性能。
频繁 vacuum 的重要性 如果不经常进行 vacuum,数据库性能将会下降,因为数据元组的版本会增加。事实上,经过几天/几个月后,可能会因为事务回绕而崩溃。
请注意,适当的数据库维护和定期进行 vacuum 是确保 PostgreSQL 数据库高效运行和避免性能问题的关键步骤。
关于Postgres的VACUUM
PostgreSQL相比大多数其他数据库管理系统而言,是一个低维护的数据库。尽管如此,适当地关注维护任务将极大地确保系统的愉快而高效体验。
在PostgreSQL中,类似于在行上进行的UPDATE或DELETE操作不会立即删除行的旧版本。如果您的应用程序在数据库中频繁执行许多UPDATE/DELETE操作,它可能会迅速增长,并需要定期进行维护活动。
通常,在PostgreSQL数据库中,维护活动会定期进行,称为vacuuming。其两个主要任务是删除死行和冻结事务ID。
vacuum过程提供了两种模式来删除死行:一种是VACUUM,另一种是VACUUM FULL。
VACUUM操作负责删除表文件每页的死行,并且其他事务可以在此过程运行时读取表。
另一方面,Full VACUUM删除死行并整理整个文件的活动行,同时,任何DDL、DML和Select等其他事务在Full VACUUM运行时都无法访问这些表。
定期进行vacuum操作对于保持数据库的高效运行和避免性能问题至关重要。
VACUUM
Vacuum用于恢复表中被“死元组”占用的空间。当记录被删除或更新(即先删除后插入)时,会创建一个死元组。PostgreSQL不会物理删除表中的旧行,而是给行加上一个“标记”,以便查询不会返回该行。当vacuum过程运行时,被这些死元组占用的空间可以被其他元组重新使用。
vacuum处理为指定表或数据库中的所有表执行以下任务:
从指定表中获取每个表。
获取表的“ShareUpdateExclusiveLock”锁。此锁允许其他事务读取。
扫描所有页面以获取所有死元组,并在必要时冻结旧元组。
删除指向相应死元组的索引元组(如果存在)。
对每页执行以下任务,步骤(6)和(7)。
删除死元组并整理页面上的活动元组。
更新目标表的相应FSM和VM。
清理内建函数中的索引。
如果最后一页没有元组,则截断最后一页。
更新与vacuum处理相关的统计信息和系统目录。
释放“ShareUpdateExclusiveLock”锁。
更新与vacuum处理相关的统计信息和系统目录。
如果可能,删除clog中的不必要文件和页面。
有两个新术语需要了解:自由空间图(FSM)和可见性图(VM)。下面是这些术语的简要解释:
自由空间图
Free Space Map(FSM):在PostgreSQL中,每个表和索引都有一个FSM来跟踪可用空间。它将所有自由空间相关信息与主关系一起存储,该关系以文件号加后缀_fsm开头。可见性图
Visibility Map(VM):可见性图将每个表和索引与页面关联起来,以跟踪哪些页面仅包含对所有活动事务可见的元组。它将这些信息与主关系分开存储,且以文件号加后缀_vm开头。
定期进行vacuum操作对于维护数据库的高效运行和优化性能至关重要。
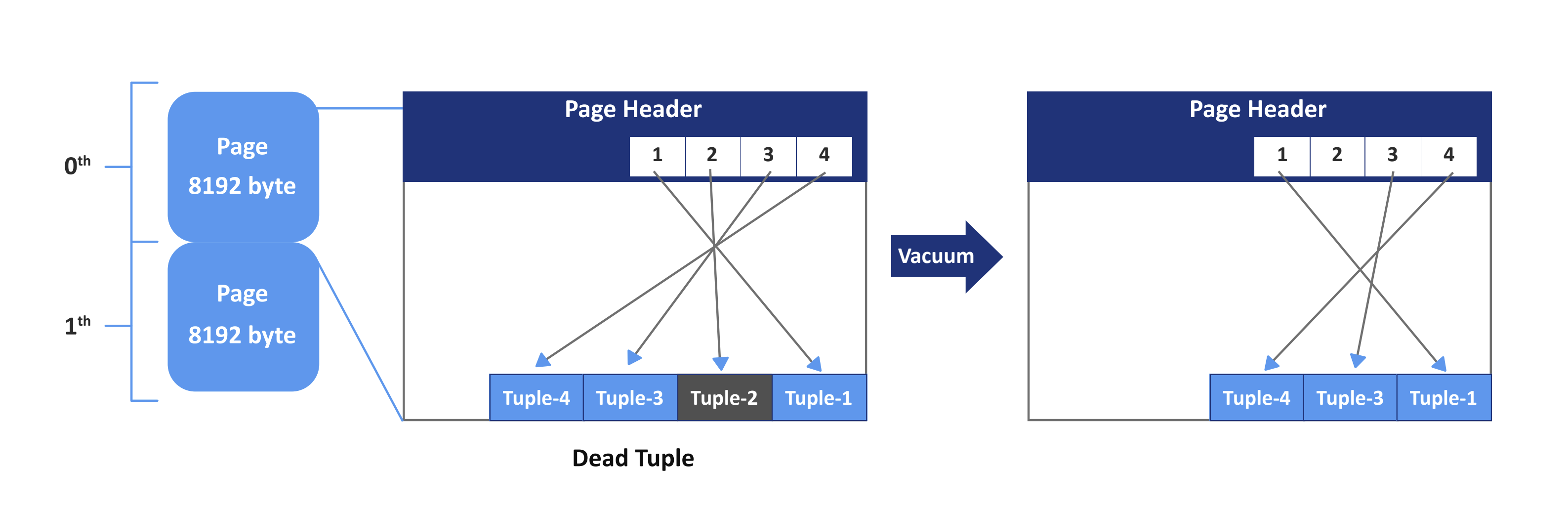
例如,如上图所示,一个表有两个页面。让我们集中在第0页,即第一页。这个页面有四个元组。元组2是一个死元组。在这种情况下,PostgreSQL会删除元组2并重新排列剩余的元组以修复碎片/膨胀,然后更新该页面的FSM和VM。PostgreSQL会继续这个过程直到最后一页。
从PostgreSQL 13开始,引入了并行VACUUM操作选项,这有助于并行运行索引的清理和清理操作。
请注意,并行选项仅在表中至少有两个索引时才有用。
我们将在本文后面解释冻结过程freezing process。
VACUUM FULL
VACUUM FULL:
VACUUM FULL 过程为指定表或数据库中的所有表执行以下任务:
从指定表中获取每个表。
获取表的“AccessExclusiveLock”锁。此锁不允许其他事务进行读写操作。
创建一个大小为8 KB的新表文件。
PostgreSQL 仅将旧表文件中的活动元组复制到新表中。
删除旧表文件。
重建所有索引。
更新统计信息和系统目录。
释放“AccessExclusiveLock”锁。
如果可能,删除不必要的clog文件和页面。
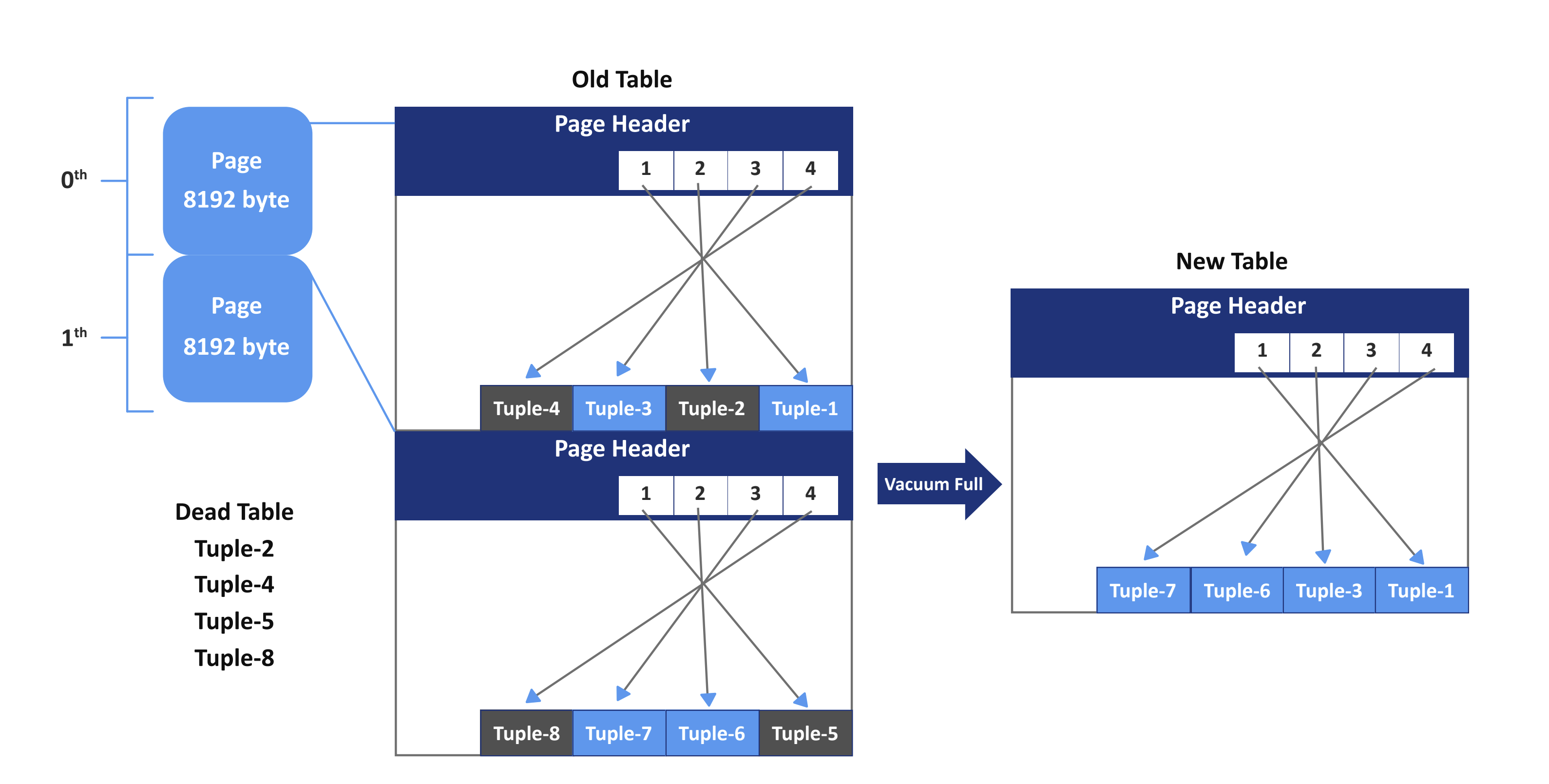
例如,如上图所示,一个表有两个页面。第0页有四个元组,元组2和元组4是死元组。第1页也有四个元组,元组5和元组8是死元组。当我们执行VACUUM FULL命令时,PostgreSQL开始删除死元组,首先获取该表的“AccessExclusiveLock”锁,并创建一个大小为8 KB的新表文件。然后,PostgreSQL仅将旧表文件中的活动元组复制到新表中,复制完所有活动元组后,PostgreSQL删除旧文件,重建所有相关的表索引,更新相关的统计信息和系统目录。
请注意,由于“AccessExclusiveLock”的存在,在Full VACUUM运行时,任何人都无法访问该表。此外,此方法还需要额外的磁盘空间,因为它会写入表的新副本,并且在操作完成之前不会释放旧副本。磁盘空间需要是表大小的两倍。VACUUM FULL有助于将表中的空闲空间回收至磁盘。
现在,你可能会想到一个问题:如果磁盘空间即将满,并且无法迅速增加大小,我们该如何处理这种情况?在这种情况下,我建议以下方法:
方法1:
最好从可以轻松容纳可用磁盘空间的小表开始。因此,逐渐地你会获得更多的空闲磁盘空间,然后很有可能会获得足够的磁盘空间来容纳那些由于磁盘空间不足和表大小过大而最初不适合进行VACUUM FULL的表。
方法2:
对于VACUUM FULL,删除要执行VACUUM FULL的表的所有索引,然后执行VACUUM FULL。操作成功完成后,再重新创建该表上所有删除的索引。如果上述两种方法都不可行,那么在这种情况下,你必须增加磁盘空间,这是唯一可行的选择。
现在,让我们了解Vacuum Freeze的概念,但在此之前,我们应该了解PostgreSQL中的事务ID回绕问题。
什么是PostgreSQL中的事务ID回绕问题?
在PostgreSQL中,事务控制机制为每个在数据库中修改的行分配一个事务ID(Txid);这些ID控制该行对其他并发事务的可见性。多版本并发控制(MVCC)依赖于两个事务的Txid来确定哪个事务首先出现。在PostgreSQL中,Txid仅为32位整数,这意味着它们只有232个,或者说大约四十亿个可能的Txid。诚然,四十亿听起来很多,但高负载可以在几天或几周内达到四十亿个事务。
现在,一个即时的问题是,当PostgreSQL达到四十亿个事务时会发生什么?
答案是PostgreSQL按顺序从循环中分配Txids。循环回到零并且看起来像0, 1, 2,..., 232-1, 0, 1,...。为了确定两个Txids中哪个更旧,根据这个逻辑,Postgres必须确保当前使用的所有Txids在彼此的范围231内。这样,所有使用中的Txids将形成一致的排序。
PostgreSQL还确保仅允许有效范围内的Txids通过定期删除所有旧的Txids来使用。如果不定期清除旧的Txids,那么就会有一个比最新的Txid更新的新的Txid并且同时出现在比最旧的Txid更早的位置;这就是所谓的事务回绕。
在这种情况下,PostgreSQL将终止正常操作以防止数据损坏并停止接受新的事务请求,这会导致停机。
要自动清除旧的Txids,PostgreSQL使用一种特殊的vacuum。Autovacuum为该进程添加了一个“防止回绕”的消息。
请注意,如果在您的环境中看到此消息,即使在postgresql.conf或postgresql.auto.conf文件中设置了autovacuum=off,您也无法停止autovacuum进程。
VACUUM FREEZE
现在我们回到原来的主题,即Vacuum Freeze。Autovacuum过程负责冻结表事务ID并用冻结的Txid替换它,以避免PostgreSQL中的事务ID回绕问题。简单来说,我们可以说冻结的Txid始终处于活动和可见状态。
作为一种主动措施,DBA需要监控表,以确保Txid不会因为大表而耗尽,在这些大表中,autovacuum过程无法跟上频繁访问表的vacuuming。
下面的SQL命令帮助DBA监控数据库中最旧的Txid年龄和数据库的当前设置:
SELECT datname, age(datfrozenxid), current_setting('autovacuum_freeze_max_age') FROM pg_database ORDER BY 2 DESC;如果某个特定数据库接近freeze_max_age值,则应执行以下查询以连接到该特定数据库。查询给出了具有最旧事务ID的表的列表,这些表应尽快进行vacuum freeze。
SELECT c.oid::regclass, age(c.relfrozenxid), pg_size_pretty(pg_total_relation_size(c.oid)) FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid WHERE relkind IN ('r', 't', 'm') AND n.nspname NOT IN ('pg_toast') ORDER BY 2 DESC;现在,如你所知,如果要在繁忙的生产环境中执行VACUUM FULL,你必须支付“AccessExclusiveLock”的长期开销。为了解决这个问题,许多企业级客户使用“pg_repack”扩展。
pg_repack
pg_repack是一个PostgreSQL扩展工具,可以执行与VACUUM FULL类似的操作,如从表和索引中删除膨胀并恢复聚簇索引的物理顺序。与VACUUM FULL不同,它在处理期间无需持有表的“AccessExclusiveLock”锁。
pg_repack过程为指定的表或数据库中的所有表执行以下任务:
删除死行并整理页面上的活动行。
重建所有索引。
更新统计信息和系统目录。
通过使用pg_repack,你可以在不影响生产环境的情况下,达到类似于VACUUM FULL的效果。
请注意,如果看到“防止回绕”的消息,即使在postgresql.conf或postgresql.auto.conf文件中设置了autovacuum=off,你也无法停止autovacuum进程。
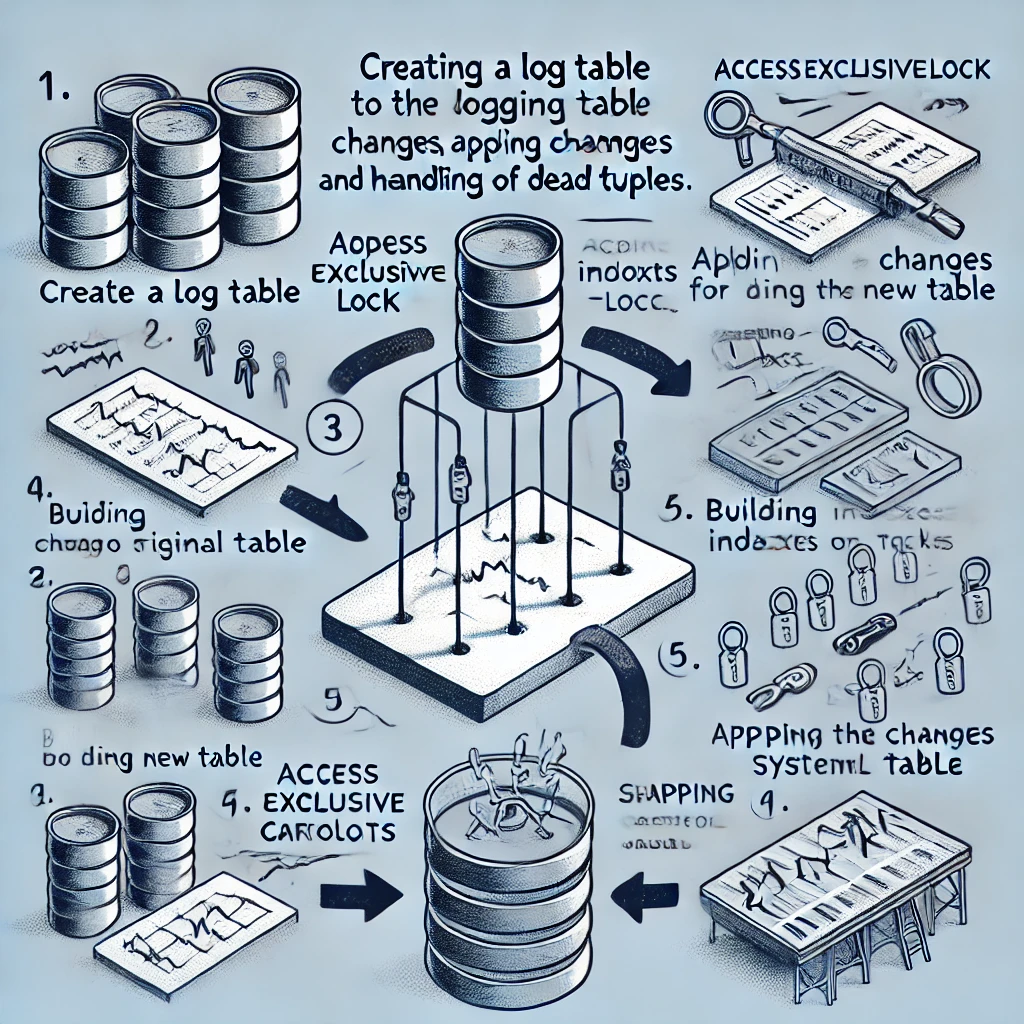
pg_repack的工作步骤:
创建日志表:记录对原始表所做的更改。
添加触发器:在原始表上添加触发器,将INSERT、UPDATE和DELETE操作记录到日志表中。
创建新表:包含旧表中的所有行。
建立索引:在新表上建立索引。
应用更改:将日志表中积累的所有更改应用到新表。
交换表:使用系统目录交换表,包括索引和TOAST表。
删除原始表:删除原始表。
pg_repack仅在初始步骤(步骤1和2)和最后的交换和删除阶段(步骤6和7)期间持有“ACCESSEXCLUSIVELOCK”锁。在其他时间,pg_repack只需要持有原始表的“ACCESSSHARELOCK”锁,这意味着SELECT、INSERT、UPDATE和DELETE操作可以照常进行。
希望本文帮助您理解vacuum的概念,并有效地规划维护活动。