

虚拟内存辅助缓冲管理
本文翻译自论文,作者:Viktor Leis/Adnan Alhomssi/Tobias Ziegler/Yannick Loeck/Christian Dietrich
为了方便学习和理解,在译文中加入了注释(NOTE)部分,这部分不属于原文,难免有错,欢迎指正。
摘要
大多数数据库管理系统在主内存缓冲池中缓存来自存储的页面。为此,它们要么依赖于将页面标识符转换为指针的哈希表,要么依赖于避免这种转换的指针转换技术。在这项工作中,我们提出了vmcache,一种利用硬件支持的虚拟内存来将页面标识符转换为虚拟内存地址的缓冲管理器设计。与现有的基于mmap的方法相比,数据库管理系统保留了对页面缺页和驱逐的控制。我们的设计可移植到现代操作系统,支持任意图数据,允许可变大小的页面,并且易于实现。
依赖虚拟内存的一个缺点是,在使用快速存储设备时,操作系统现有的操作页面表的基本机制可能成为性能瓶颈。因此,作为第二个贡献,我们提出了exmap,它在Linux上实现了可扩展的页面表操作。vmcache和exmap共同提供了在多核CPU和快速存储设备上灵活、高效且可扩展的缓冲管理。
CCS CONCEPTS Information systems → Data management systems; Record and buffer management.
Keywords Database Management Systems; Operating Systems; Caching; Buffer Management
ACM 引用格式: Viktor Leis, Adnan Alhomssi, Tobias Ziegler, Yannick Loeck 和 Christian Dietrich. 2023. 虚拟内存辅助缓冲管理:预印本已被 SIGMOD 2023 接收发表。载于 ACM 会议论文集 (Conference’17)。ACM,纽约,纽约,美国,14 页。https://doi.org/10.1145/nnnnnnn.nnnnnnn
授权允许个人或课堂使用本作品的全部或部分内容进行数字或纸质复制,前提是复制品不得用于盈利或商业利益,且必须在复制品的第一页上注明此声明和完整的引用。对于本作品中由ACM以外的其他人拥有的部分,必须尊重其版权。允许在标注出处的情况下进行摘要引用。否则,复制、重新出版、发布至服务器或重新分发到列表,均需要事先获得特定的许可和/或支付费用。请向permissions@acm.org申请权限。
Conference’17, July 2017, Washington, DC, USA © 2023 Association for Computing Machinery. ACM ISBN 978-x-xxxx-xxxx-x/YY/MM. . . $15.00 https://doi.org/10.1145/nnnnnnn.nnnnnnn
1. INTRODUCTION
DBMS与操作系统(OS)。
数据库管理系统(DBMS)和操作系统(OS)之间一直存在一种不太和谐的关系。操作系统通过虚拟化硬件访问提供进程隔离,而数据库管理系统则希望完全控制硬件以实现最佳效率。同时,操作系统提供的服务(例如,从存储中缓存页面)几乎完全符合数据库系统的需求——但由于性能和语义方面的原因,数据库管理系统经常重新实现这些功能。操作系统提供的服务与数据库系统的需求之间的不匹配问题早在四十年前就已经被提出【40】,但从那时起情况并没有太大改善。
操作系统控制的缓存。
操作系统相对于数据库管理系统(DBMS)的一个大优势在于,它运行在内核模式中,因此可以访问特权指令。特别是,操作系统可以直接控制虚拟内存页表,因此可以执行用户空间进程无法完成的操作。例如,操作系统通过处理器的虚拟内存和内存管理单元(MMU)实现透明的页面缓存,并通过mmap系统调用将存储映射到虚拟内存中来公开这一功能。
使用mmap时,由于转换后备缓冲区(TLB)的存在,内存中的操作(缓存命中)速度很快。然而,正如Crotty等人【13】最近讨论的那样,mmap通常并不适合数据库系统。mmap的两个主要问题是:
DBMS失去了对缺页和驱逐的控制权
Linux中的虚拟内存实现对于现代NVMe
Non-Volatile Memory ExpressSSD来说太慢【13】。表1
Table 1总结了mmap的属性和替代的缓冲管理器设计。
Table 1: Conceptual comparison of buffer manager designs
mmap [13] | tradi. [15] | pointer swiz. [16, 23] | Umbra [33] | vmcache Sec. 3 | +exmap Sec. 4 | |
|---|---|---|---|---|---|---|
transl. control | page tbl. OS | hash tbl. DBMS | invasive DBMS | invasive DBMS | page tbl. DBMS | page tbl. DBMS |
var. size | easy | hard | hard | med. (*) | easy | easy |
graphs | yes | yes | no | no | yes | yes |
implem. | med. (**) | easy | hard | hard | easy | easy |
in-mem. | fast | slow | fast | fast | fast | fast |
out-mem. | slow | fast | fast | fast | med. | fast |
(*) only powers of 2 33
(**) read-only easy, transactions hard 13
Note
转换后备缓冲区(Translation Lookaside Buffer,TLB)是现代计算机系统中的一个专用缓存,用于加速虚拟内存地址到物理内存地址的转换。TLB 在 CPU 中起着关键作用,它通过存储最近使用的页面表项来减少地址转换所需的时间,从而提高系统性能.
TLB的工作原理
在使用虚拟内存的计算机系统中,操作系统和硬件通常将虚拟地址转换为物理地址。这个转换过程依赖于一个称为页表(Page Table)的数据结构。每次CPU需要访问内存时,它必须通过查阅页表来确定虚拟地址对应的物理地址。这种查阅过程涉及多级查找,可能导致较高的访问延迟。
为了减少这种延迟,TLB 被引入作为一个缓存,它存储最近使用的虚拟地址到物理地址的映射。具体来说:
TLB命中(TLB Hit):如果TLB中已经存在所需的虚拟地址的映射,CPU可以直接从TLB获取物理地址,这比访问页表快得多。
TLB未命中(TLB Miss):如果TLB中没有所需的映射,则必须访问页表来查找对应的物理地址。这种情况下,找到的映射会被存储到TLB中,以便下次使用。
TLB的结构
容量和关联度:
容量:TLB的大小通常较小,可能只包含几十到几百个条目。每个条目对应一个虚拟页面到物理页面的映射。
关联度(Associativity):TLB通常是一个高关联度的缓存,可能是完全关联或部分关联。这意味着每个虚拟页面可以映射到多个物理页面,增加了命中的可能性。
分级TLB:
现代CPU通常使用多级TLB结构。例如,一级TLB(L1 TLB)速度最快但容量最小,二级TLB(L2 TLB)容量更大但访问速度较慢。这种分级结构有助于平衡命中率和访问速度。
指令TLB和数据TLB:
TLB可以进一步分为指令TLB(iTLB)和数据TLB(dTLB),分别用于缓存指令地址和数据地址的映射。这种分离有助于提高处理器的并行处理能力。
TLB的刷新与失效
TLB刷新(TLB Flush):
当操作系统更改页表时,必须刷新TLB。这可以是完全刷新,清除所有条目,也可以是部分刷新,清除特定页面的条目。
TLB失效(TLB Invalidation):
操作系统通常会选择性地使特定的TLB条目失效。这种操作通常在页面映射被修改或页面被释放时发生。
TLB射击(TLB Shootdown):
在多核处理器中,当一个核心需要刷新另一个核心的TLB时,会触发TLB射击。操作系统通过发送一个跨处理器中断(IPI)来通知其他核心刷新它们的TLB。这种操作可能会引起性能瓶颈,尤其是在频繁的内存管理操作中。
DBMS控制的缓存。
为了获得完全的控制,大多数数据库管理系统(DBMS)因此避免使用基于文件的mmap,而是在用户空间中实现显式的缓冲管理。传统上,这通常通过使用哈希表来完成,哈希表包含当前缓存中的所有页面【15】。最近的、更高效的缓冲管理器设计依赖于指针转换技术【16, 23, 33】。这两种方法都有其缺点:前者存在非平凡的哈希表转换开销,而后者则实现起来更加困难,并且不支持循环页面引用(例如,图数据)。本研究提出了利用硬件支持的虚拟内存作为缓冲管理的基本构建块,以避免在性能或功能性上的妥协。
贡献1:vmcache。
本文的第一个贡献是vmcache,这是一种新颖的缓冲池设计,依赖于虚拟内存,但与基于文件支持的mmap解决方案不同,它在数据库管理系统(DBMS)内保留了对缺页和驱逐的控制。其核心思想是将存储设备映射到匿名(而非文件支持的)虚拟内存中,并使用MADV_DONTNEED提示来显式控制驱逐。这使得可以通过TLB支持的转换实现快速的内存中页面访问,而无需将控制权交给操作系统。基于页表的转换还允许vmcache支持任意的图数据和可变大小的页面。
贡献2:exmap。
虽然vmcache在内存中的性能非常出色,但每次缺页和驱逐都涉及操作页表。不幸的是,现有的操作系统页表操作原语在高性能的NVMe SSD上表现出可扩展性问题【13】。因此,作为第二个贡献,我们提出了exmap,这是一种用于高效操作虚拟内存映射的操作系统扩展。exmap作为Linux内核模块实现,是数据库管理系统(DBMS)与操作系统(OS)协同设计的一个实例。通过提供新的操作系统级抽象,我们简化并加速了数据处理系统。总体而言,如表1所示,将exmap与vmcache结合使用,结果不仅在内存和外存操作中速度快,还提供了重要的功能性。
2. BACKGROUND: DATABASE PAGE CACHING
缓冲管理。
大多数数据库管理系统(DBMS)从次级存储中缓存固定大小的页面(通常为4-64 KB)到主内存池中。这种缓存的基本问题是如何高效地将页面标识符(PID),即唯一确定每个页面在次级存储中的物理位置,转换为指向缓存数据内容的指针。
接下来,我们将描述已知的几种方法,包括表1中显示的六种设计。
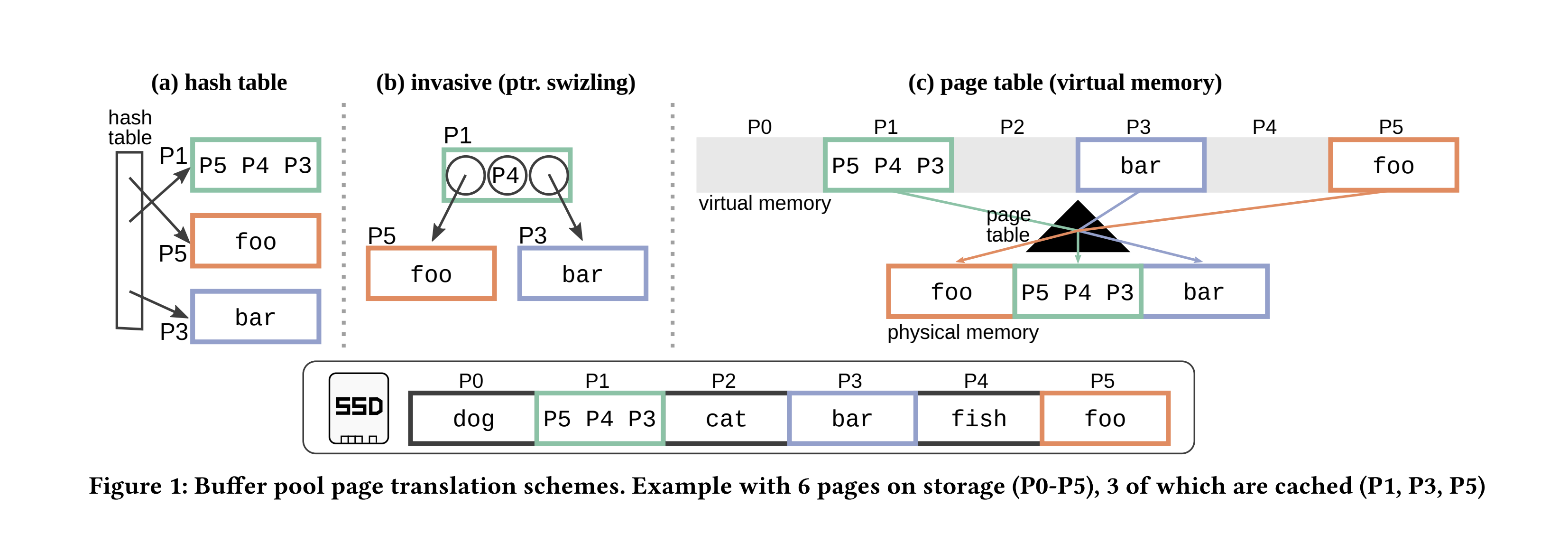
基于哈希表的转换。
图1a展示了传统的缓冲池实现方式【15】:一个哈希表通过页面标识符(PID)索引所有缓存的页面。使用PID来寻址页面,这总是涉及哈希表查找。如果未命中,则从次级存储中读取页面并将其添加到哈希表中。
这种方法简单且灵活。哈希表是缓存状态的唯一真相来源,页面可以通过PID任意地相互引用。
缺点是内存中的性能不佳,因为即使是缓存命中也必须支付哈希表查找的成本。
还要注意,存在两个翻译层次:从PID到虚拟内存指针(在DBMS层面),以及从虚拟内存指针到物理内存指针(在OS/MMU层面)。
主内存DBMS。
避免传统缓冲管理器开销的一种方式是完全放弃缓存并将所有数据保存在主内存中。虽然纯内存数据库系统可以非常快,但在过去十年中,DRAM的价格几乎没有下降【18】。另一方面,NVMe闪存SSD形式的存储变得便宜(每字节比DRAM便宜20-50倍【18】)且快速(每个SSD每秒超过100万次随机4 KB读取【4】)。这使得纯内存系统在经济上变得不吸引人【29】,并意味着现代存储引擎应该结合DRAM和SSD。挑战在于在具有高I/O吞吐量的NVMe SSD上支持非常大的数据集,并使缓存命中几乎像在主内存系统中一样快。
指针转换(侵入式翻译)。
实现缓冲管理器的一种高效技术是指针转换。这种技术最初是为面向对象的DBMS提出的【20】,但最近已应用于几个高性能存储引擎【16, 23, 33】。如图1b所示,核心思想是用虚拟内存指针替换数据结构中缓存页面的PID。因此,页面命中可以直接取消引用指针,而不必首先通过哈希表进行转换。这种方式可以理解为,指针转换通过侵入性地修改数据结构本身来摆脱显式的哈希表转换。指针转换提供了非常好的内存中性能。然而,它需要对每个缓冲管理的数据结构进行适应,并且其内部同步相当复杂。例如,为了取消指针转换,必须找到并锁定其父节点,而在每个节点上存储父节点指针在节点分裂时会带来同步挑战。另一个缺点是,基于指针转换的系统通常不支持对任何特定页面有多个传入引用。换句话说,只有树形数据结构被直接支持。图数据、B+树叶页面中的下一个指针,以及多个传入的元组引用(例如,来自辅助索引的引用)需要不优雅且有时低效的变通办法。
硬件支持的页面翻译。
传统的缓冲管理器和指针转换存在一个令人不满且看似无法避免的权衡:要么支付哈希表间接访问的性能成本,要么失去支持类似图数据的能力。与其像指针转换那样摆脱翻译,另一种实现效率的方法是通过硬件支持使PID到指针的转换高效。所有现代操作系统都使用虚拟内存,并且通过CPU的硬件支持,将虚拟地址透明地转换为物理地址。页表条目被缓存到CPU中,特别是TLB中,使得虚拟内存转换非常快。图1c展示了如何使用硬件支持的页面翻译来缓存来自次级存储的页面。
操作系统驱动的缓存与基于文件的mmap。
Unix提供了mmap系统调用,通过虚拟内存访问存储。在将文件或设备映射到虚拟内存后,内存访问将触发页面错误。操作系统随后将在页表中加载该页面,使后续的页面访问与普通内存访问一样快。
Note
页面错误分为两种类型:主要页面错误(Major Page Fault)和次要页面错误(Minor Page Fault)。
主要页面错误发生在CPU访问的虚拟内存页面既不在物理内存中,也不在内核的页缓存中。系统必须从外部存储(如磁盘)中读取该页面的内容到物理内存中,然后更新页表以完成映射。
由于涉及磁盘I/O操作,主要页面错误的处理通常非常耗时,可能导致显著的系统性能下降,特别是在内存密集型应用中。
次要页面错误发生在CPU访问的虚拟内存页面已存在于物理内存中,但该页面尚未映射到进程的地址空间中。这种情况通常发生在页面被交换到物理内存中或被其他进程共享的情况下。
次要页面错误的处理速度相对较快,因为不涉及磁盘I/O操作。尽管它仍然会导致一些系统开销,但对性能的影响比主要页面错误小得多。
显然上文提到的是主要页面错误。
因此,一些系统避免实现缓冲池,而是通过mmap数据库文件/设备来依赖操作系统页面缓存。
虽然这种方法使缓存命中非常快,但最近由Crotty等人【13】分析的主要问题包括:
确保事务安全性是困难的,可能效率低下,因为DBMS失去了对驱逐的控制。
没有异步I/O接口,I/O延迟是不可预测的。
I/O错误处理麻烦。
操作系统实现的页面错误和驱逐速度太慢,无法充分利用现代NVMe存储设备。
对基于文件的mmap方法缺乏驱逐控制是一个根本性问题。特别是,它阻止了实现ARIES风格的事务。ARIES使用就地写入,并在相应的日志条目刷新之前防止驱逐脏页——这是现有操作系统接口无法实现的【13】。没有对驱逐的明确控制,也不可能实现DBMS优化的页面替换算法。因此,一个人只能依赖当前操作系统实现的任何算法,这不太可能针对DBMS负载进行优化。
Note
什么是ARIES风格的事务
Algorithms for Recovery and Isolation Exploiting Semantics
ARIES是一种用于数据库管理系统的高效恢复算法,由C. Mohan等人在1992年提出。
ARIES的核心思想是基于日志的恢复,它依赖于“写前日志”(Write-Ahead Logging, WAL)协议和一些关键技术,如重做(Redo)、回滚(Undo)和检查点(Checkpoint)。这些技术结合起来,确保了在系统发生故障时数据库可以安全、快速地恢复到一致状态。
缺乏对驱逐机制的控制为什么是根本问题
ARIES风格的事务处理依赖于严格控制页面的持久化顺序,特别是在事务日志和数据页面的写入顺序方面。
使用
mmap时,操作系统负责管理内存页的换入换出(页面驱逐)。当页面不再使用时,操作系统可能会选择将页面驱逐出物理内存,并将修改后的数据(脏页)写回磁盘。这种写回操作是由操作系统自动执行的,数据库管理系统(DBMS)无法直接控制这个过程。这意味着,DBMS无法确保在日志条目被刷入磁盘之前,数据页面不会被驱逐到磁盘,这违反了WAL协议的要求,导致可能无法正确恢复事务。不受控制的页面刷新和无法确保事务隔离性都会导致事务的原子性和一致性难以保证,这都是mmap之于ARIES的缺点。
在
mmap管理下,错误处理可能变得更加复杂。当页面错误发生时,mmap可能会导致部分数据在磁盘和内存之间的不同步,而这些操作又不一定被DBMS知晓或控制。
DBMS驱动的虚拟内存辅助缓存。
虽然使用mmap的操作系统管理缓存可能不是大多数DBMS的好解决方案,但操作系统有一个很大的优势:不必使用显式的哈希表进行页面翻译,它可以依赖硬件支持(TLB)进行页面翻译。这引出了以下问题:是否可以利用虚拟内存子系统而不失去对驱逐和页面错误处理的控制?本文的一个贡献是肯定地回答了这个问题。在第3节中,我们描述了如何利用广泛支持的操作系统功能(匿名内存和MADV_DONTNEED提示)来实现硬件支持的页面翻译,同时在DBMS中保留对缺页和驱逐的完全控制。
可变大小的页面。
除了使页面翻译快速之外,使用页表还使得实现多种页面大小变得更加容易。具有动态页面大小显然非常有用,例如,用于存储大于一页的对象【33】。然而,许多缓冲管理器只支持一种特定的页面大小(例如4 KB),因为多种大小会导致复杂的分配和碎片问题。在这些系统中,更大的对象需要通过跨页拆分来实现,这使得访问这些对象的代码复杂且缓慢。另一方面,控制页表时,可以通过将多个(例如3个)非连续的物理页面映射到一个连续的虚拟内存范围,创建一个更大的(例如12 KB)页面。这在操作系统中易于实现,主内存中也不会出现碎片化。允许多种(尽管仅是二次幂)页面大小的一个系统是Umbra【33】。它通过为每种页面大小分配多个缓冲池大小的虚拟内存区域来实现这一点。要分配特定大小的页面,只需从该类别的内存中缺页即可。要释放页面,缓冲管理器使用MADV_DONTNEED操作系统提示。这种方法消除了不同页面大小的碎片化,但Umbra的页面翻译仍然基于指针转换,而不是页表。因此,Umbra继承了指针转换的缺点(实现困难,不支持图数据),同时可能遇到操作系统可扩展性问题。
快速虚拟内存操作。
虽然操作系统支持的方法提供了非常快速的缓存页面访问,并且支持可变大小的页面,但不幸的是,它们可能会遇到性能问题。一个问题是每个CPU核心都有自己的TLB,可能会与页表不同步。当页表发生变化时,操作系统通常必须中断所有CPU核心,并迫使它们使其TLB失效(“TLB射击”)。另一个问题是内核内的数据结构在具有许多核心的系统上可能成为可扩展性的瓶颈。Crotty等人【13】观察到,由于这些问题,mmap在内存不足的工作负载中可能表现缓慢。对于一个SSD的随机读取,他们测量到它实现的I/O吞吐量不到可实现I/O吞吐量的一半。在来自十个SSD的顺序扫描中,mmap与显式异步I/O之间的差距大约是20倍。任何基于虚拟内存的方法(包括我们基本的vmcache设计)都会遇到这些内核问题。因此,第4节描述了一种新的、专门的Linux虚拟内存子系统,称为exmap,它解决了这些性能
问题。
持久内存。
在这项工作中,我们重点关注块存储,而不是字节可寻址的持久内存,后者已有多个专门的缓存设计被提出【8, 21, 28, 41, 43】。
3. VMCACHE: VIRTUAL-MEMORY ASSISTED BUFFER MANAGEMENT
POSIX Portable Operating System Interface for UNIX 系统调用mmap通常将一个文件或存储设备映射到虚拟内存中,如图1c所示。文件支持的mmap的优点在于,由于硬件支持的页面转换,访问缓存的页面变得与普通内存访问一样快。如果页面转换已缓存到TLB中且数据恰好在L1缓存中,则访问时间可能只需要1纳秒。最大的缺点是DBMS失去了对缺页和驱逐的控制。如果页面未缓存但驻留在存储中,取消引用指针可能突然需要10毫秒,因为操作系统会导致对DBMS透明的缺页。因此,从DBMS的角度来看,驱逐和缺页是完全不可预测的,并且可能在任何时候发生。
在本节中,我们描述了vmcache,一种缓冲管理器设计——像文件支持的mmap一样,使用虚拟内存将页面标识符转换为指针(见图1c)。然而,与mmap不同,在vmcache中,DBMS保留了对缺页和驱逐的控制。
3.1 页表操作
设置虚拟内存。与文件支持的mmap方法类似,vmcache分配了一个虚拟内存区域,其大小与支持存储的大小相同(至少)。然而,与文件支持的mmap不同,此分配不会直接由存储支持。这样的“未支持”分配称为匿名分配,令人困惑的是,它也是通过mmap完成的,但使用了MAP_ANONYMOUS标志:
int flags = MAP_ANONYMOUS|MAP_PRIVATE|MAP_NORESERVE;
int prot = PROT_READ | PROT_WRITE;
char* virtMem = mmap(0, vmSize, prot, flags, -1, 0);请注意,这里没有指定文件描述符(第四个参数为-1)。存储是显式处理的,可以是一个文件(多个应用程序共享一个文件系统)或多个块设备(在RAID设置中)。此外,分配最初不会由物理内存支持,这很重要,因为存储容量通常比主内存大得多。
将页面添加到缓存中。为了将页面添加到缓存中,缓冲管理器显式地将其从存储读取到虚拟内存中的相应位置。例如,我们可以使用pread系统调用显式地读取页面P3,如下所示:
uint64_t offset = 3 * pageSize;
pread(fd, virtMem + offset, pageSize, offset);一旦pread完成,物理内存页面将被安装到页表中,数据将对DBMS进程可见。与mmap不同的是,mmap在未命中页面时透明地处理,而不涉及DBMS,而在vmcache方法中,缓冲管理器控制I/O。例如,我们可以使用同步的pread系统调用或异步I/O接口,如libaio或io_uring。
从缓存中删除页面。在映射越来越多的页面之后,缓冲池最终将耗尽物理内存,导致分配失败或交换。在这种情况发生之前,DBMS需要开始驱逐页面,这在Linux上可以通过以下方式完成:
madvise(virtMem + offset, pageSize, MADV_DONTNEED);此调用将从页表中删除物理页面,并将其物理内存释放用于将来的分配。如果页面是脏的(即已更改),则需要首先将其写回存储,例如使用pwrite:
pwrite(fd, virtMem + offset, pageSize, offset);通过上述原语,DBMS可以控制所有缓冲管理决策:如何读取页面、哪些页面需要驱逐、是否以及何时写回页面,以及何时从页表中删除页面。
3.2 页面状态和同步基础
在缓冲管理器的实现中,最困难的方面之一是同步,例如,管理对同一页面的竞争。缓冲管理器不仅必须在内部使用可扩展的同步机制,还应为上层DBMS层提供高效且可扩展的同步原语。毕竟,大多数数据库数据结构(例如,关系、索引)都存储在可缓存的页面之上。
缓冲池状态。在传统的缓冲管理器中(参见图1a),翻译哈希表被用作缓存状态的唯一真实来源。因为所有访问都通过哈希表进行,所以同步相对简单(但通常不高效)。相比之下,我们的方法需要一个额外的数据结构来进行同步,因为并非所有页面访问都会通过页表,而且页表不能直接从用户空间操作。因此,我们分配了一个连续的数组,该数组包含与存储上的页面数量相同的页面状态条目,并且这些条目与存储中的页面位置相对应,如下图所示:

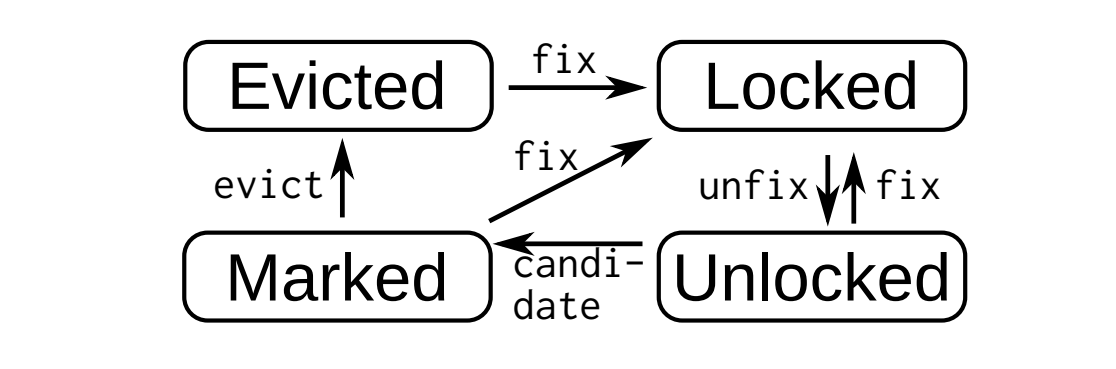
页面状态。在启动后,所有页面都处于“已驱逐”(Evicted)状态。页面访问操作首先检查它们的状态条目,并根据以下状态图进行操作:
Note
Evicted(已驱逐): 页面未在内存中,表示页面内容已经被驱逐,需要从存储设备重新加载。当访问一个“已驱逐”的页面时,系统会将页面从存储中加载到内存,并将状态更新为“Locked”(已锁定)或“Unlocked”(未锁定)。
Locked(已锁定): 页面正在被当前线程访问或修改,其他线程不能访问此页面。页面状态转换为“Locked”通常在CAS操作成功后发生。
Unlocked(未锁定): 页面已经加载到内存中,并且不再被任何线程独占,可以被其他线程访问。访问未锁定的页面时,如果需要进行操作,会将状态转换为“Locked”。
Marked(已标记): 页面可能处于某种特殊状态,通常是为了某些特定的缓存或同步策略而设置的。具体含义取决于缓冲管理器的实现细节。
Listing 1: 独占页面访问的伪代码
fix(uint64_t pid): // 独占地固定页面
uint64_t ofs = pid * pageSize
while (true) // 不断重试直到成功
PageState s = state[pid]
if (s.isEvicted()) // 如果页面已被驱逐
if (state[pid].CAS(s, Locked)) // 使用CAS操作锁定页面状态
pread(fd, virtMem + ofs, pageSize, ofs) // 从存储加载页面到内存
return virtMem + ofs // 返回页面地址,表示页面未命中(需要加载)
else if (s.isMarked() || s.isUnlocked()) // 如果页面已被标记或未锁定
if (state[pid].CAS(s, Locked)) // 尝试锁定页面状态
return virtMem + ofs // 返回页面地址,表示页面命中(已经在内存中)
unfix(uint64_t pid): // 解锁页面
state[pid].setUnlocked() // 将页面状态设置为未锁定代码清单1Listing 1展示了用于fix和unfix操作的伪代码,这些操作提供了独占页面访问。假设我们有一个当前处于“已驱逐”(Evicted)状态的页面(代码中的第5行)。如果一个线程想要访问该页面,它会调用fix,该操作将使用比较并交换(CAS)操作将页面状态转换为“已锁定”(Locked)状态(第6行)。然后,线程负责从存储中读取该页面,并通过pread隐式地将其安装到页表中(第7行)。在那之后,它可以访问页面本身,最后调用unfix,这会将页面状态转换为“未锁定”(Unlocked)状态(第13行)。如果另一个线程同时想要固定同一页面,它将等待该页面被解锁。这种方式将页面未命中操作串行化,防止同一页面被多次读取。
第四种状态“已标记”(Marked)有助于实现时钟替换策略——尽管也可以实现任意其他算法。缓存的页面通过将其状态设置为“已标记”来选择进行驱逐。如果该页面被访问,它会转回“已锁定”(Locked)状态,从而清除标记(第10行)。否则,页面可以被驱逐,并最终转换为“已驱逐”(Evicted)状态。
Listing 2: 乐观读取的伪代码
optimisticRead(uint64_t pid, Function fn):
while (true) // 不断重试直到成功
PageState s = state[pid] // 包括版本号
if (s.isUnlocked())
// 乐观读取:
fn(virtMem + (pid * pageSize))
if (state[pid] == s) // 验证版本
return // 成功
else if (s.isMarked())
// 清除标记:
state[pid].CAS(s, Unlocked)
else if (s.isEvicted())
fix(pid); unfix(pid) // 处理页面未命中3.3 高级同步
到目前为止,我们讨论了如何独占地锁定页面。为了实现可扩展且高效的读取操作,vmcache还提供了共享锁(允许多个并发读者访问同一页面)和乐观(无锁)读取。
共享锁。为了实现只读操作的共享锁,我们在页面状态中记录并发读者的数量。如果页面未被独占锁定,读操作在固定/解锁页面时会自动地增加/减少计数器【9】。独占访问必须等待计数器为0后才能获取锁。
乐观读取。无论是独占锁还是共享锁,在获取或释放锁时都会写入共享内存,这会使其他CPU核心的缓存条目失效。对于像B树这样的树形数据结构,这会导致可扩展性不佳,因为内部节点的页面状态会被不断地失效。锁的一个优雅替代方案是乐观的、无锁的页面读取,它通过验证读取是否正确来实现。当独占锁定的页面解锁时,锁包含的更新版本号会增加【9, 25, 30】。我们将这个版本计数器与页面状态一起存储在同一个64位值中,确保它们总是原子性地更改。正如代码清单2 Listing 2所示,乐观读者会检索页面状态,如果状态为“未锁定”(代码中的第4行),它会读取页面内容(第5行)。之后,我们再次检索页面状态,确保页面仍然未锁定且版本号未发生变化(第6行)。如果检查失败,操作将重新启动。请注意,版本计数器不仅在页面更改时增加,在页面被驱逐时也会增加。这对正确性至关重要,例如,确保在验证之前被驱逐的标记页面的乐观读取会失败。为了防止因重复重启导致的饥饿,还可以回退到基于锁的悲观操作(代码中未显示)。最后,我们要注意,乐观读取可以跨多个页面交错进行,从而实现像锁耦合一样的复杂数据结构的同步,如B树【24】。这种方法已被证明具有很高的可扩展性,并且性能优于无锁数据结构【42】。
64位状态条目。总体而言,我们使用64位来表示页面状态,其中8位用于编码“未锁定”(0)、“共享锁定”(1-252)、“独占锁定”(253)、“已标记”(254)和“已驱逐”(255)状态。剩下的56位用于版本计数器,这些位数足以保证在实际使用中不会发生溢出。64位也是一个方便的大小,允许进行比较并交换(CAS)等原子操作。
内存回收和乐观读取。通常,无锁数据结构在释放内存时需要特别注意【25, 27, 30】。为了解决这个问题,提出了诸如基于时代的内存回收【30】或危险指针【31】等技术。所有这些技术都会带来开销,并可能由于过长的回收延迟而导致额外的内存消耗。有趣的是,尽管vmcache支持乐观读取,但它可以完全避开这些问题。实际上,vmcache并不阻止正在进行乐观读取的页面的驱逐/回收。然而,这并不是问题,因为在使用MADV_DONTNEED提示从页表中移除页面后,它会被零页面替换。在这种情况下,乐观读取将继续从页面加载0值而不会崩溃,并且在版本检查期间检测到驱逐已发生。(检查失败是因为驱逐首先会锁定页面,然后再解锁,从而增加版本号。)因此,vmcache不需要任何额外的内存回收机制。
停车场(Parking Lot)。为了避免独占锁和共享锁浪费CPU周期并在锁竞争时确保公平性,可以使用“停车场”(Parking Lot)【9, 36】技术。其核心思想是,如果线程未能获取锁(可能在尝试了几次之后),它可以“停车”自己,线程将被阻塞,直到持有锁的线程将其唤醒。停车本身是通过使用一个固定大小的哈希表来存储操作系统支持的条件变量来实现的【9】。在页面状态中,我们只需要一个额外的位来指示是否有线程正在等待该页面锁的释放。停车场的一个巨大优势是每个页面的空间开销非常低,仅为1位,而不是pthread(读写)锁的64字节【9】。
3.4 替换策略
时钟算法的实现。原则上,可以在vmcache之上实现任意的替换策略。如前所述,我们当前的实现使用了时钟算法。在缓冲池的内存即将耗尽之前,我们将“未锁定”(Unlocked)页面的状态更改为“已标记”(Marked)。所有页面访问,包括乐观读取,都会清除“已标记”状态,以确保热点页面不会被驱逐。要实现时钟算法,需要能够遍历缓冲池中的所有页面。一种方法是遍历状态数组,同时忽略已驱逐的页面。然而,如果状态数组非常稀疏(即存储远大于主内存),这种方法的开销会非常大。我们实现了一种更稳健的方法,将当前缓存的所有页面标识符存储在哈希表中。哈希表的大小等于DRAM中的页面数(而不是存储大小),我们的页面替换算法在这个更小的数据结构上进行迭代。我们使用了一个固定大小的开放寻址哈希表,这使得迭代在缓存中更高效。请注意,与传统的缓冲管理器不同,这个哈希表在缓存命中时不会被访问,只会在页面缺页和驱逐时使用。
批量驱逐。出于效率考虑,我们的实现一次驱逐64个页面。为了最小化独占锁定和利用高效的批量I/O,驱逐分为五个步骤:
从哈希表中获取标记的候选页面批次,并以共享模式锁定脏页面。
写入脏页面(使用libaio)。
尝试锁定(升级)干净(脏)页面候选。
使用
madvise从页表中移除锁定的页面。从驱逐哈希表中移除锁定的页面,并解锁它们。
在步骤3之后,所有页面必须独占锁定,以避免驱逐过程中出现竞争条件。对于脏页面,我们已经在步骤1中获得了共享锁定,这就是为什么步骤3执行锁定升级。干净页面尚未锁定,因此步骤3尝试直接获取独占锁定。两种操作都可能失败,因为另一个线程可能访问了该页面,在这种情况下,驱逐会跳过该页面(即页面留在缓冲池中)。在基本的vmcache设计中,步骤4只是对每个页面调用一次madvise。使用exmap,我们将能够利用批量从页表中移除页面的功能。
3.5 页面大小
默认页面大小。大多数处理器默认使用4 KB的虚拟内存页面,这种粒度也非常适合闪存SSD。因此,将默认的缓冲池页面大小设置为4 KB是合理的。x86(ARM)架构还支持2 MB(1 MB)页面,对于主要读取较大块数据的系统,这可能是一个可行的替代方案。使用vmcache,OLTP系统通常应使用4 KB页面,而对于OLAP系统,4 KB和2 MB页面都是合适的选择。
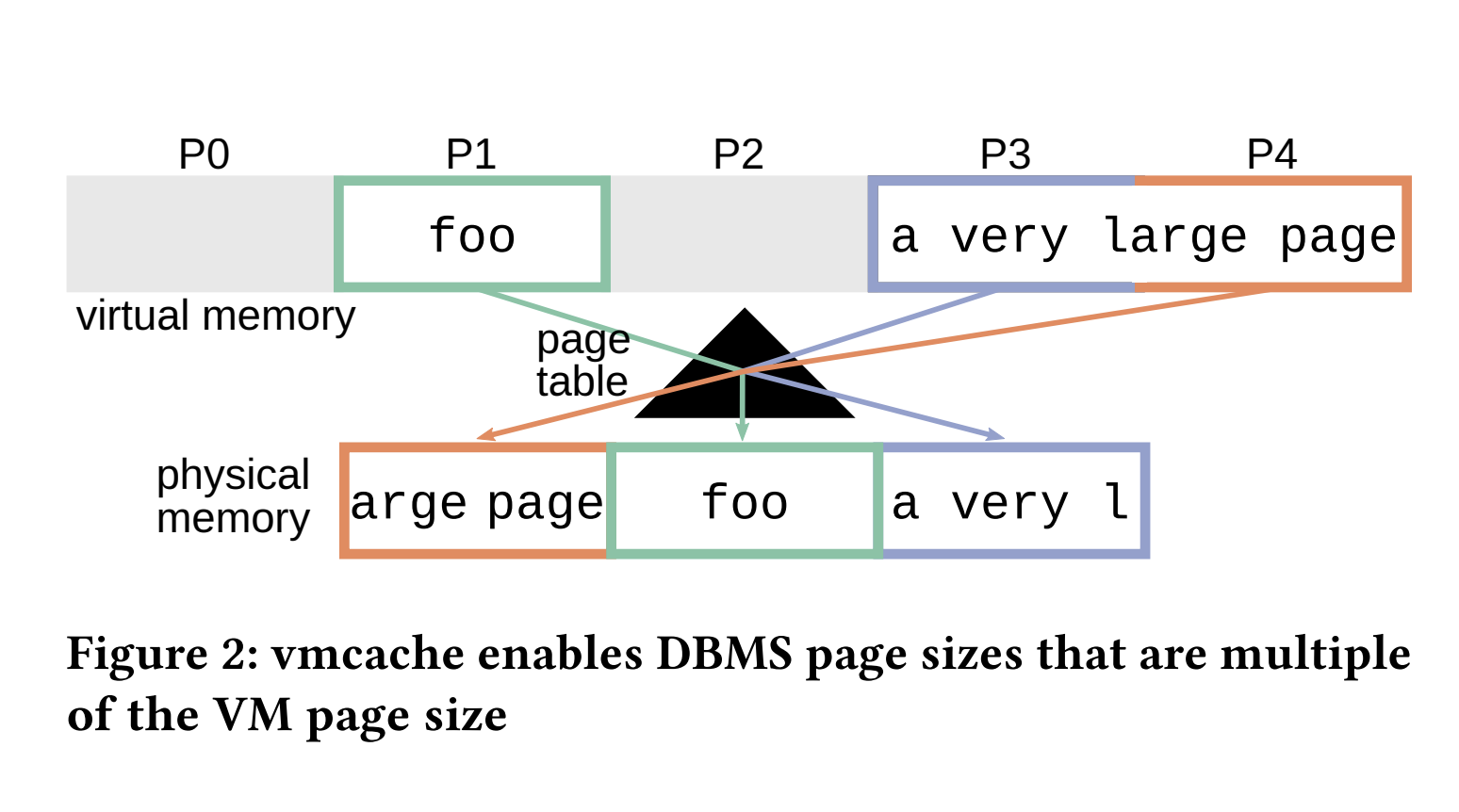
支持更大页面。vmcache还使支持任何4 KB倍数的缓冲池页面大小变得容易。图2 Figure 2展示了一个示例,其中页面P3跨越了两个物理页面。对于在缓冲管理器之上实现的数据结构,这一事实是完全透明的,即内存看起来是连续的。对大页面的访问只使用头页面的页面状态(图中的P3而非P4)。依赖虚拟内存来实现多种页面大小的优势在于,它避免了主内存的碎片化。值得注意的是,碎片化并没有简单地从用户空间移动到内核空间,而是通过页面表的间接访问允许操作系统始终处理4 KB页面,而不需要维护不同的分配类别。因此,如图2所示,连续的虚拟内存范围通常在物理上不是连续的。
大页面的优势。尽管大多数DBMS依赖于固定大小的页面,支持不同的页面大小有许多优点。一个使用可变大小页面简化和加速DBMS的例子是字符串处理。使用可变大小的页面,例如,可以简单地通过缓冲池中的指针调用外部字符串处理库。如果没有此功能,任何字符串操作(比较、LIKE、正则表达式搜索等)都需要显式处理跨多个页面的字符串分块。由于很少有现有库支持分块处理,必须将较大的字符串复制到连续的内存中才能使用它们。另一个例子是压缩的列式存储,其中每个列块具有相同数量的元组,但大小不同。在这两种情况下,确实可以将数据拆分到多个固定大小的页面中(许多系统由于缺乏可变大小的支持不得不这样做),但这会导致代码复杂化和/或性能下降。最后,我们提到,与像Umbra这样的系统【33】不同,vmcache支持任意页面大小,只要它们是4 KB的倍数。这减少了大对象的内存浪费。总体而言,我们认为这一功能可以显著简化DBMS的实现,并带来更好的性能。
3.6 讨论
状态访问。如前所述,每次页面访问都必须先检索页面状态——这通常会导致缓存未命中——然后才能读取页面数据。因此,有人可能会怀疑这种方法是否和传统的基于哈希表的缓冲管理器一样低效。然而,这两种方法在内存访问模式方面有很大不同。在哈希表方法中,页面数据指针是从哈希表中检索的,也就是说,这两个指针之间存在数据依赖性,通常需要支付两次缓存未命中的延迟成本。相比之下,在我们的方法中,页面状态指针和数据内容指针都是预先已知的。因此,现代CPU的乱序执行将同时进行这两个访问,从而隐藏了状态检索的额外开销。
内存消耗。vmcache在DRAM中有一些开销,主要以页表和页面状态数组的形式存在:为了配置虚拟内存映射,vmcache每4 KB存储需要8.016字节来设置一个5级页表。除此之外,vmcache还需要额外的8字节用于页面状态:8位用于独占/共享锁定,56位用于乐观读取的版本计数器。因此,总的来说,vmcache每4 KB存储大约需要16字节的DRAM。例如,对于1 TB的闪存SSD,内部缓冲管理器状态需要4 GB的DRAM,占SSD容量的1/256。这在经济上是合理的,因为闪存每字节大约比DRAM便宜50倍,因此额外的内存成本为闪存价格的50/256 ≈ 20%。虽然这在大多数使用场景中足够低,但仍有方法可以减少这种成本:(1) 以牺牲乐观读取(减少56位)和共享锁定(减少6位)的代价压缩64位页面状态,降至每个存储页面2位(驱逐,独占锁定),这样对于1 TB的闪存SSD,DRAM总开销为2.07 GB(增加10.11%的成本)。(2) 将页面状态放置在缓冲的页面中,并在存储页面中保留相应的8字节未使用,从而只需不可避免的2 GB DRAM开销。因此,从系统的总体成本来看,内存开销是合理的,而且可以进一步减少。
地址空间。现有的64位CPU通常至少支持48位虚拟内存地址。在Linux上,其中一半保留给内核,因此用户空间的虚拟内存分配限制为2^47 = 128 TB。从Ice Lake开始,Intel处理器支持57位虚拟内存地址,允许用户空间地址空间达到2^56 = 64 PB。因此,地址空间足够我们的方法使用,并将在可预见的未来继续足够大。
4 EXMAP:可扩展且高效的虚拟内存操作
vmcache利用硬件支持的虚拟内存,显式控制页面驱逐,同时支持灵活的锁定模式、可变大小的页面和任意引用模式(如图数据结构)。这通过依赖两种广泛可用的操作系统原语实现:匿名内存映射和显式内存释放系统调用。尽管vmcache是一种实用且有用的设计,但在某些工作负载下,它可能会遇到操作系统内核性能问题。在本节中,我们描述了一种名为exmap的Linux内核扩展,它解决了这一弱点。我们首先说明为什么现有的操作系统实现并不总是足够,然后提供设计的高级概述,最后描述实现细节。
4.1 动机
为什么要更改操作系统? 使用vmcache时,(取消)分配4 KB页面的频率与页面未命中和驱逐操作一样频繁,即操作系统的内存子系统成为内存不足工作负载中的热点路径。不幸的是,Linux的页面分配和释放实现并不具备可扩展性。因此,页面高周转率的工作负载可能会因操作系统的虚拟内存子系统而成为瓶颈,而不是存储设备。为了量化Linux上的情况,我们通过触发页面缺页在单个匿名映射上分配页面,然后使用MADV_DONTNEED再次驱逐它们。如图3所示,原生Linux在128个线程下仅能达到1.51M操作/秒。顺便提一句,一个现代的PCIe 4.0 SSD单独就可以达到每秒1.5M次随机4KB读取【4】。换句话说,一个128线程的CPU将完全忙于为一个SSD操作虚拟内存——不会留出任何CPU周期用于实际工作。
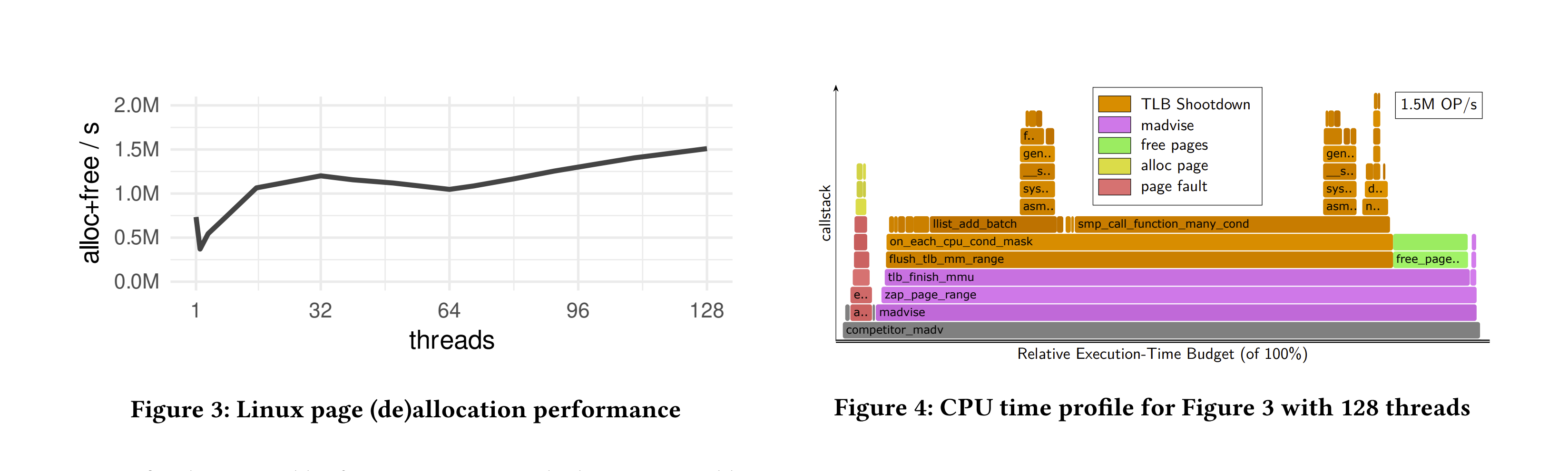
问题1:TLB(翻译后备缓冲区)清空(Shootdown)。 为了调查这种可扩展性差的问题,我们使用了perf性能分析工具,并在图4 Figure 4中展示了一个火焰图【17】。Linux将79%的CPU时间花在了flush_tlb_mm_range函数中。该函数实现了TLB清空,这是一种显式一致性措施,防止过时的TLB条目导致数据不一致或安全问题。当更改页表时,操作系统会向运行应用程序线程的所有其他(N-1)个核心发送一个处理器间中断(IPI),然后这些核心清除它们的TLB。由于每个驱逐的页面都需要N-1个IPI,这种方式从根本上是不可扩展的。
问题2:页面分配。 在清空TLB之后,Linux的下一个主要性能问题是内核内的页面分配器(火焰图中的free pages和alloc page)。Linux的页面分配器依赖于一个集中且不可扩展的数据结构,并且出于安全原因,在驱逐后必须将每个页面清零。因此,一旦更大的TLB清空瓶颈得到解决,具有高页面周转率的工作负载将受限于页面分配器。
为什么需要新的页表操作API? 上述两个性能问题无法通过在Linux中进行一些低级别更改来解决,而是根本上由现有的几十年历史的虚拟内存API和语义引起的:同步逐页API不可避免地会导致TLB清空,而页面分配则由于物理内存页面可以在不同的用户进程之间共享而变慢。因此,实现高效且可扩展的页表操作需要不同的虚拟内存API和修改后的语义。
4.2 设计原则
exmap。exmap是一个专门的Linux内核扩展,它通过新的API和高效的内核级实现,支持快速且可扩展的页表操作。我们为与vmcache配合使用而共同设计了exmap,但正如我们将在第4.5节中讨论的,它也可以用于加速其他应用程序。exmap作为一个Linux内核模块,用户可以将其加载到任何最近的Linux内核中,无需重启。与POSIX接口类似,exmap提供了用于设置虚拟内存、分配和释放页面的原语。然而,如下所述,exmap具有新的语义,以消除POSIX接口引发的瓶颈。
解决TLB清空问题。 减少TLB清空次数的一种有效方法是批量驱逐多个页面,从而通过批量大小减少清空次数。为此,exmap提供了一个批处理接口,可以通过一次系统调用释放多个页面。对于驱逐页面时的缓冲管理器来说,批处理很容易利用,但批量页面分配可能会出现问题,因为这些操作通常对延迟敏感。为了避免分配时的TLB清空,exmap确保分配根本不需要清空。为此,exmap始终对已释放页面的页表条目进行只读保护(通过在页表条目中设置特定位)。相比之下,Linux将该条目设置为可写但不可读的零页面——这可能导致在分配时需要显式失效的无效TLB条目。这一微妙的变化完全消除了分配时的清空需求。
解决页面分配问题。 Linux和exmap之间的另一个重要区别是页面分配机制。在Linux中,当页面被释放时,它会返回到一个系统范围的池(并且可能因此返回给其他进程)。这有两个缺点:(1) 页面分配的可扩展性不佳,(2) 出于安全原因,页面被反复清零。相反,exmap在创建时预先分配物理内存,并将其保留在可扩展的线程本地内存池中,从而避免了这两个瓶颈。
4.3 概述和使用
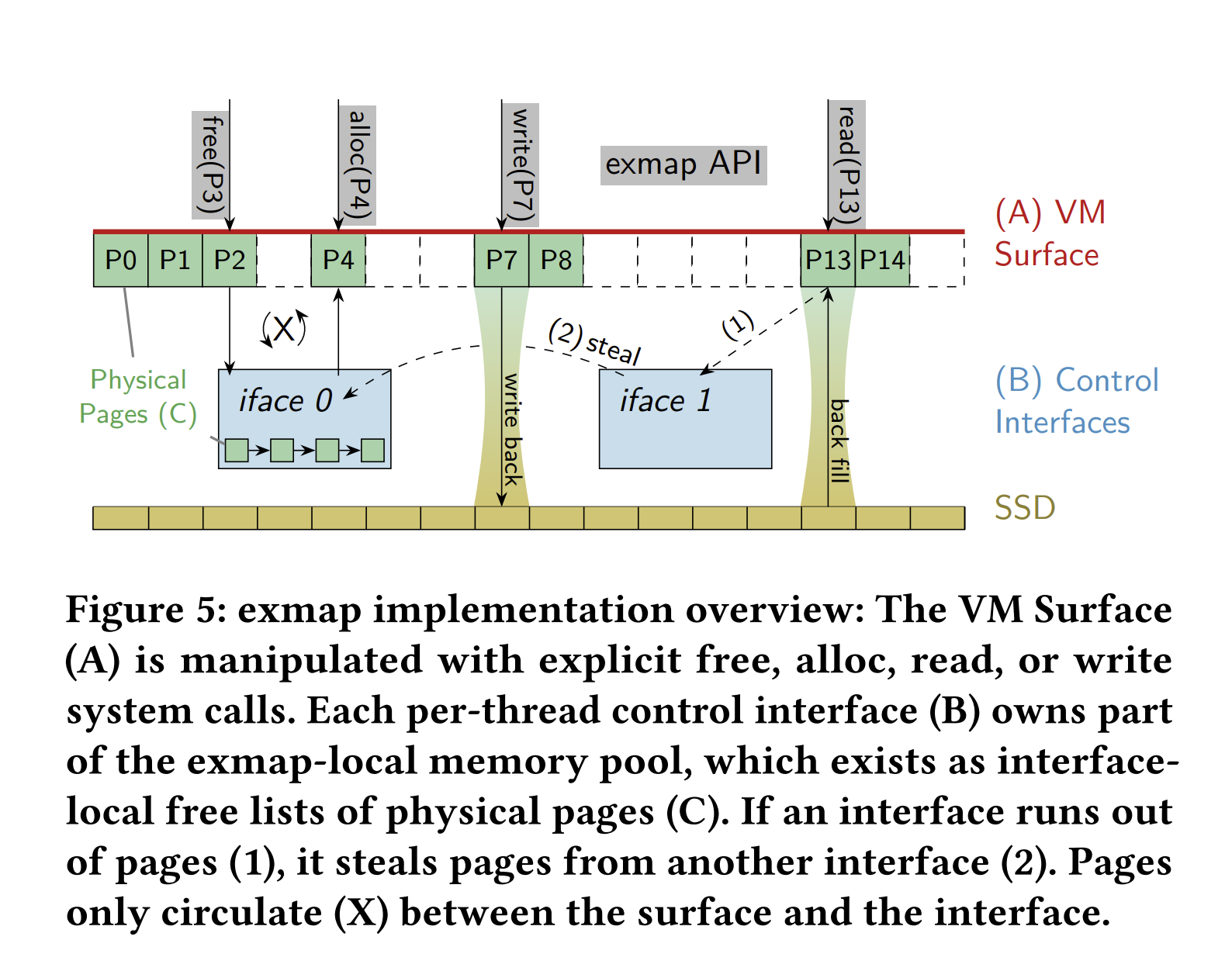
实现概述。 图5 Figure 5展示了一个exmap对象的三个主要组件:
(A) 它在虚拟内存(VM)中的表面;
(B) 用于与对象交互的若干控制接口;
(C) 一个物理DRAM页面的私有内存池,这些页面作为接口本地空闲列表存在于所有接口中。
Listing 3: exmap usage example
// 打开设备/文件作为后备存储
int fd = open("/dev/...", O_RDWR | O_DIRECT);
// 创建一个新的exmap对象
struct exmap_setup_params params = {
.max_interfaces = 8, // 控制接口的数量
.pool_size = 262144, // 内存池中的页面数量(1 GB)
.backing_fd = fd // 存储设备
};
int exmap_fd = exmap_create(¶ms);
// 在虚拟内存中映射exmap
Page* pages = (Page*)mmap(vmSize, exmap_fd, ...);
// 使用接口5分配和驱逐内存
exmap_interface_t iface = 5;
// 分散I/O向量:P1, P3-P5
struct iovec vec[] = {
{ .iov_base = &pages[1], .iov_len = pageSize },
{ .iov_base = &pages[3], .iov_len = pageSize * 3 }
};
exmap_action(exmap_fd, iface, EXMAP_ALLOC, &vec, 2);
exmap_action(exmap_fd, iface, EXMAP_FREE, &vec, 2);
// 从fd读取页面到exmap中
// 使用exmap_fd作为代理文件描述符
pread(exmap_fd, &pages[13], pageSize, iface); // 读取P13
preadv(exmap_fd, &vec, 2, iface); // 读取P1, P3-P5
// 写回操作是显式的,不使用代理文件描述符
pwrite(fd, &pages[7], pageSize, 7 * pageSize); // 写回P7
创建。 在创建时(代码清单3的第4-8行),用户配置这些组件:用户指定内核应该分配的接口数量(第5行)。通常,每个线程应使用自己的接口(例如,线程ID = 接口ID)以最大化可扩展性。用户还指定内存池页面的数量(第6行),这些页面将在exmap对象的生命周期内从Linux的页面分配器中抽取。作为第三个参数,用户可以指定一个文件描述符作为读取操作的后备存储(第7行)。
操作。 创建后,进程通过mmap将exmap表面显示在其VM中(第10行)。虽然exmap可以具有任意的VM范围,但在整个系统中只能映射一次。在映射的表面上,我们允许在exmap表面上进行向量化和分散的页面分配(第11行和图5(X))。为此,用户指定一个映射表面内的页面范围向量,并在明确指定的接口上发出EXMAP_ALLOC命令。所需的物理页面首先从指定的接口中提取(图5(1)),然后我们从其他接口中“偷取”内存(图5(2))。一旦分配,页面就永远不会被换出,因此访问永远不会导致页面缺页,从而提供确定性的访问时间。通过释放操作(第18行),我们释放页面范围,并将已删除的物理页面释放到指定的接口。
读取I/O。与基于文件的mmap不同,我们不会透明地分页或写回数据,而是用户(例如vmcache)明确在表面上调用读取和写入操作。为了加速这些操作,我们将exmap与常规Linux I/O子系统集成在一起,使exmap文件描述符成为指定后备设备的代理(第19-22行)。这允许在一次系统调用中结合页面分配和读取操作:在读取时,exmap首先用内存填充指定的页面范围,然后使用常规的Linux VFS接口执行实际的读取操作。由于我们从表面偏移中派生磁盘偏移,因此我们可以使用偏移参数来指定分配接口。通过这种集成,exmap支持同步(pread)和异步(libaio和io_uring)读取。此外,由于表面偏移决定了磁盘偏移,向量化读取(preadv,IORING_OP_READV)隐式地成为分散操作(第22行),目前Linux允许这种操作,无需其他系统调用。
写入I/O。在写入方面,我们主动决定不采用写入代理接口,例如,捆绑写回和页面驱逐。虽然这样的捆
绑并非必要,因为用户已经可以将表面页面写入磁盘(第24行),但如果每次单独写入时都释放页面,可能会导致不必要的开销。因此,我们将写回和(批量)释放页面分开。
4.4 实现细节
可扩展的页面分配器。通常,当内核取消映射一个页面时,它将页面返回到系统范围的伙伴分配器,该分配器可能会将其合并为更大的物理内存块。在分配时,这些块又会被分解为页面,并在映射到用户空间之前被清零。因此,在高虚拟内存周转率下,内存会不断地被清零,并在虚拟内存子系统和伙伴分配器之间循环。为了优化vmcache的虚拟内存操作,我们决定使用每个exmap独立的内存池,以绕过系统分配器。这也使我们能够避免主动的页面清零,因为页面只在同一进程的表面和内存池之间循环,从而不可能发生信息泄漏给其他进程的情况。只有在初始创建exmap时,我们才会对内存池中的页面进行清零。
线程本地控制接口和页面窃取。此外,exmap的控制接口不仅允许应用程序表达分配/驱逐的局部性,还减少了集中式分配器带来的争用和虚假共享。为此,我们将内存池分布为接口上的本地空闲4 KB页面列表,因此需要进行页面窃取。当接口本地的空闲列表耗尽时,我们使用三层页面窃取策略:(1) 从上次成功窃取的接口窃取,(2) 随机选择两个接口并从空闲页面较多的接口窃取,(3) 遍历所有接口,直到收集到足够的页面。为了最小化窃取操作的次数,我们窃取比当前操作所需更多的页面。如果我们从表面移除页面,我们总是将它们推送到指定的接口。因此,对于每个接口的分配和驱逐平衡的工作负载,窃取操作很少是必要的。
无锁页表操作。对于页表操作,Linux使用了一种细粒度的锁定机制,锁定页表树的最后一级以更新其中的页表条目。然而,在大多数架构上,这些条目具有机器字大小,我们可以直接使用原子指令进行更新。虽然出于可移植性考虑,Linux保留了这种机会,我们还是集成了一个基于原子交换的热点路径:如果操作只操作最后一级页表上的单个页表条目,我们可以通过一次比较并交换来安装(或移除)虚拟内存映射。
I/O子系统集成。对于读取操作,Linux的I/O子系统针对已填充物理内存的目标缓冲区的顺序读取进行了优化。例如,如果没有exmap,Linux不提供可以处理多个偏移量的分散读取操作;这样的读取请求必须分成多个(不相关的)读取。在较低的层面上,Linux期望虚拟内存已填充,并在发出实际设备操作之前为每个缺失页面调用页面错误处理程序。因此,Linux不能充分利用分散请求模式,而是将它们视为单独的请求,从而引发不必要的开销(即重复的页表锁定和分配器调用)。为避免这种情况,exmap提供了带代理文件描述符的向量化和分散读取。这使我们能够(1)预填充虚拟内存,避免页面错误处理程序路径,并(2)减少系统调用的开销,因为我们每个请求批次只发出一个系统调用。
多个exmap实例。一个进程可以创建多个exmap对象,这些对象映射为进程地址空间中的单独非重叠的虚拟内存区域(VMA)。这些VMA具有自己的虚拟内存子系统,并在很大程度上彼此隔离,并与内核的其余部分隔离,同时仍然确保一致性和权限隔离。如前所述,每个exmap只能映射一次,从而避免了一般解决方案的簿记开销。
4.5 讨论
操作系统定制。exmap是一个用于高效操作虚拟内存的新低级操作系统接口。看似微小的语义变化,如批处理和避免零页面操作,能够在不牺牲安全性的情况下带来非常高的性能。可以做个类比,exmap对于虚拟内存而言,就像O_DIRECT对于I/O一样:是为那些希望尽可能高效地管理和控制硬件资源的系统而设计的专用工具。exmap的两个设计决策需要进一步讨论。
功能性。我们在很大程度上将exmap的表面及其内存池与Linux的其余部分分离开来。作为这种精简设计的结果,exmap高效但不支持写时复制(copy-on-write)和交换(swapping)。很少有缓冲池实现依赖这种功能。实际上,exmap的行为简单且可预测,这实际上是一种优势,因为它允许缓冲管理器精确跟踪内存消耗并确保稳定的性能。
可移植性。另一个重要方面是对其他操作系统和架构的可推广性。由于我们的内核模块具有自己的专用虚拟内存子系统,因此它只与Linux内核的其余部分有很少的依赖关系。这使得exmap在Linux版本之间的移植非常容易,并表明该概念可以为其他操作系统(如Windows和FreeBSD)实现。除了我们在小型页表修改中依赖架构的无锁快捷方式外,exmap的实现也与使用的ISA和MMU无关,因为它重用了Linux的MMU抽象。换句话说,我们的Linux实现可以很容易地在支持Linux的CPU架构之间移植。
exmap的其他应用。尽管我们明确为缓存设计了exmap,但它也有其他用途:(1) 由于其高效的虚拟内存修改性能(参见图8),堆管理器可以使用大型exmap表面将空闲页面合并为大型连续缓冲区,这对于DBMS查询处理非常有用【14】。(2) 通过页面移动扩展,语言运行时系统可以使用exmap作为页面对齐对象池的复制垃圾回收器的基础。(3) 对于大规模图处理,工人们通常以高扇出(例如,用于广度优先搜索)和高并行性从后备存储中请求随机放置的数据,这可以通过exmap轻松处理。(4) 对于用户空间文件系统,设备支持的exmap允许用户空间控制的缓冲区缓存策略。
5 评估
本节的目的是通过实验表明,vmcache在内存工作负载中能够与最先进的基于指针转换的缓冲管理器竞争,而exmap使vmcache设计能够充分利用现代存储设备。然而,我们在此强调,vmcache的主要优势在于其定性特征,而非定量表现,正如我们在表1中总结的那样。具体来说,尽管vmcache易于实现,但它支持任意的(图)数据和可变大小的页面。
5.1 实验设置
实现。我们的缓冲管理器是用C++实现的,使用带有可变大小键/负载和乐观锁定耦合的B+树。我们比较了两个变体:(1) 使用第3节描述的常规和未修改的操作系统原语的vmcache。(2) 基于vmcache代码的vmcache+exmap,除了使用exmap内核模块和第4节提出的接口。两个变体都使用4 KB页面,并通过阻塞的pread系统调用执行读取操作。因此,每个线程最多只有一个未完成的读取I/O操作。脏页面使用libaio分批写入,每批最多64个页面。vmcache通过madvise单独释放这些页面,而vmcache+exmap则将它们分批释放为单个EXMAP_FREE调用。为了避免增加延迟,页面分配不分批处理(我们每次分配使用一个EXMAP_ALLOC调用)。
竞争对手。我们使用了三个基于B+树的最先进的开源存储引擎作为竞争对手:(1) LeanStore【1】,(2) WiredTiger 3.2.1【5】,以及(3) LMDB 0.9.24【2】。对于缓存,LeanStore和WiredTiger依赖于指针转换,而LMDB【2】使用带有异位写入的mmap。由于本研究的重点是缓冲管理,在所有系统中,我们都禁用了预写日志,并在提供的最低事务隔离级别下运行。LMDB和LeanStore使用4 KB页面,而WiredTiger在存储的叶节点上使用32 KB页面。我们将LeanStore配置为使用8个页面提供线程来处理页面替换【19】,以实现最佳性能。
硬件、操作系统。我们在一台配备AMD EPYC 7713处理器(64核,128个硬件线程)和512 GB主内存的单插槽服务器上运行所有实验,其中128 GB用于缓存。存储使用的是3.8 TB的三星PM1733 SSD。除运行vmcache+exmap时使用我们的exmap内核模块外,系统运行未修改的Linux 5.16。
工作负载。我们使用TPC-C以及一个由随机点查找、8字节均匀分布键和120字节值组成的键/值工作负载。这两个基准显然非常不同:TPC-C结合了复杂的访问模式且写入频繁,而查找基准则简单且只读。两者都作为独立的C++程序实现,并链接到存储引擎,因此没有网络开销。
5.2 内存内端到端比较
vmcache性能和可扩展性。在第一个实验中,我们研究了数据集适合主内存的情况下的性能和可扩展性。结果如图6 Figure 6所示。两个vmcache方法比其他系统更快,并且扩展性非常好——分别实现了将近90M次查找/秒和约3M次TPC-C事务/秒。由于内存工作负载中没有发生页面驱逐,因此我们看到exmap在性能上并没有比基本的vmcache设计提供显著优势。
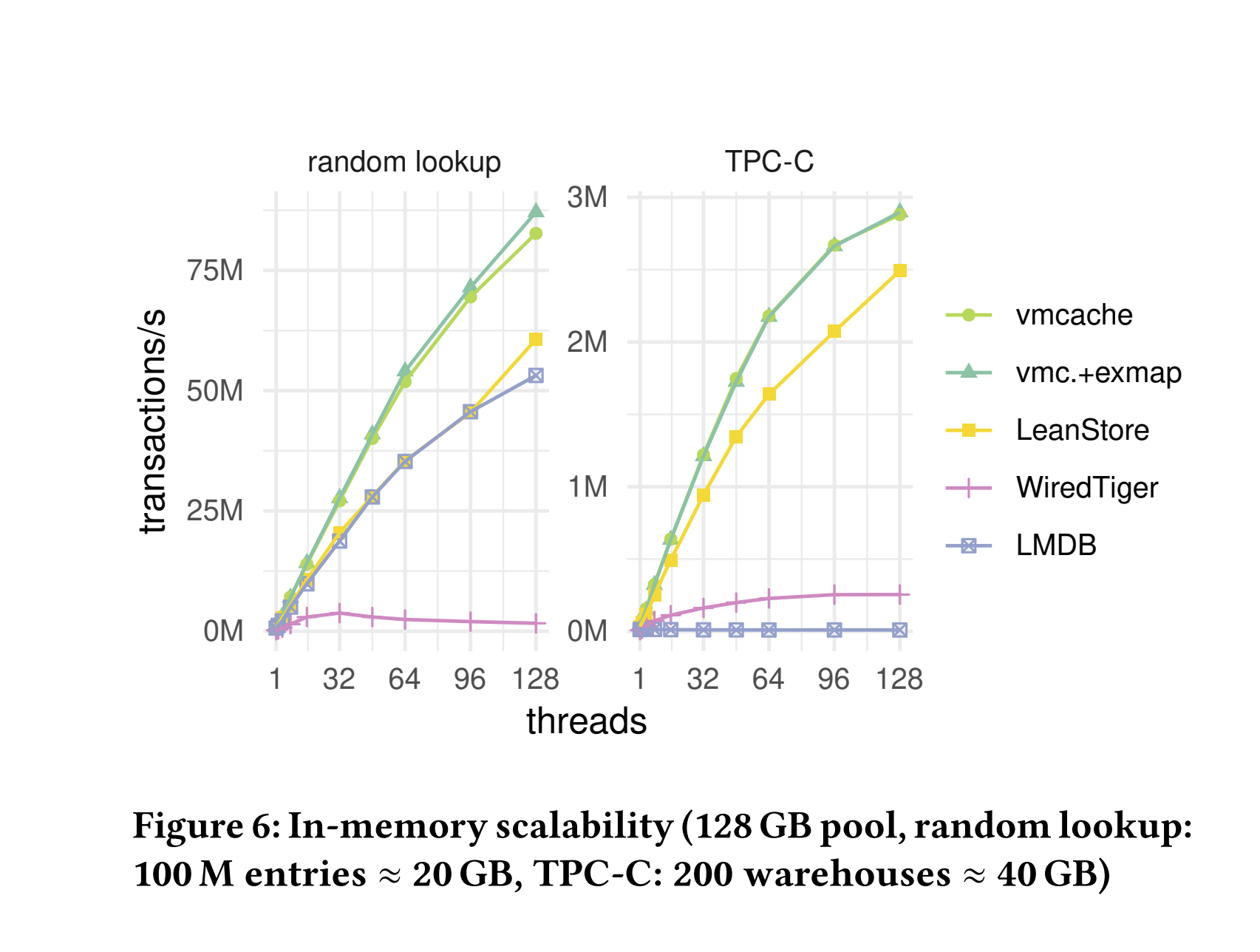
竞争对手性能。LeanStore的性能最接近vmcache,而WiredTiger则明显落后。LMDB在查找基准测试中与LeanStore竞争,但在写入频繁的TPC-C基准测试中无法扩展。这是因为LMDB使用单写入者模型和异位写入,这意味着读取操作无需同步,但在任何时间点只能有一个写入者。总体而言,结果显示vmcache设计具有出色的可扩展性和高绝对性能。
5.3 内存外端到端比较
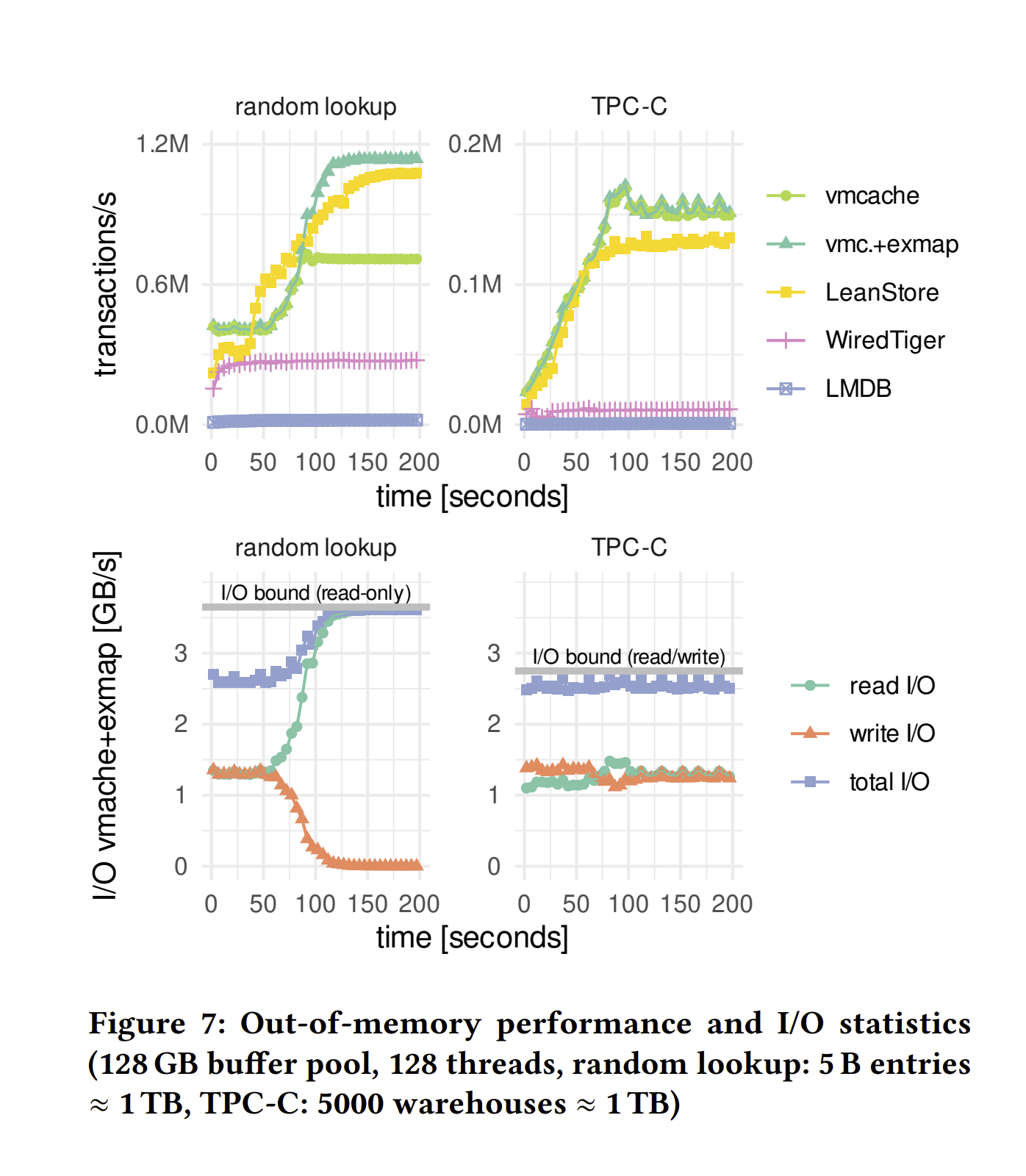
工作负载。图7 Figure 7 显示了内存外性能(上图)随时间的变化。在这个实验中,数据集比缓冲池大一个数量级,这意味着页面未命中频繁发生。我们在加载数据后立即开始测量两个工作负载的性能。因此,在所有系统中,性能需要一些时间才能收敛到稳定状态,因为缓冲池状态需要从加载调整到实际工作负载。
vmcache和exmap。对于随机查找基准测试,我们看到exmap的性能比基本的vmcache提高了约60%。这是由于Linux在页面驱逐期间的可扩展性问题所致。对于TPC-C,vmcache和vmcache+exmap之间的差异很小,因为即使是vmcache也能成为I/O受限。对于这两种工作负载,exmap变体成功地完全I/O受限,如图的下半部分所示。
LeanStore。当我们将LeanStore与vmcache和exmap进行比较时,我们看到vmcache在稳定状态下的随机查找性能明显慢于LeanStore(这也是由于vmcache受限于内核)。只有使用exmap模块,vmcache才能与LeanStore竞争。最终,exmap+vmcache的性能与LeanStore相似,并且在稳定状态下两者都受限于I/O。性能差异主要由于实现上的微小差异:vmcache+exmap由于更紧凑的B树(每次事务的I/O较少)而具有略高的稳定状态性能,而LeanStore由于使用专用后台线程进行更积极的脏页面驱逐,在40秒到90秒内暂时优于vmcache+exmap。
WiredTiger和LMDB。WiredTiger和基于mmap的LMDB明显比vmcache和LeanStore慢。WiredTiger的性能受到32 KB页面大小的影响,而LMDB受限于内核开销(随机查找)和单写入者模型(TPC-C)。总体而言,我们看到虽然基本的vmcache提供了稳健的内存外性能,但随着每秒I/O操作数量的增加,它需要借助exmap来释放快速存储设备的全部潜力。
5.4 vmcache消融研究
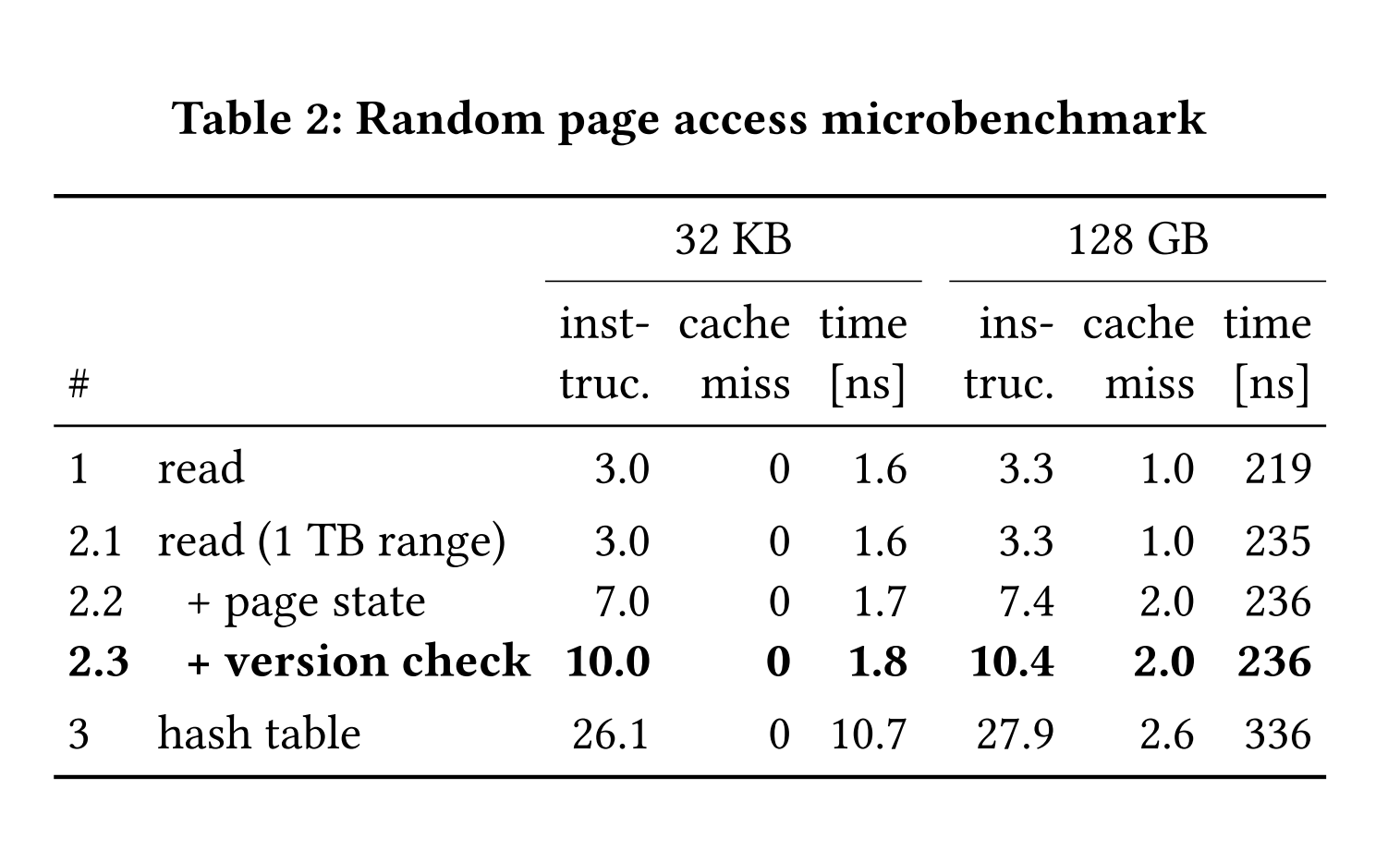
为了更好地理解虚拟内存辅助缓冲管理的性能,并将其与基于哈希表的设计进行比较,我们使用微基准测试评估了页面访问时间。我们关注内存内的情况,这也是为什么在本实验中所有页面访问都是命中。对于所有设计,我们随机读取主内存中的4 KB页面,并报告平均指令数、缓存未命中次数和访问延迟。我们报告了32 KB和128 GB数据的数值。前者对应于非常热的驻留在CPU缓存中的页面,后者则对应于DRAM中的较冷页面。表2 Table 2中的第1行仅显示了32 KB/128 GB数组中的随机访问时间,因此代表了任何缓冲管理器设计的下限。接下来的三行逐步显示了vmcache设计中必要的步骤(分别在第3.1节、第3.2节和第3.3节中描述)。在第2.1行中,我们随机从1 TB(而非128 GB)的虚拟内存范围中读取,这增加了7%的延迟,因为增加了TLB的压力。在第2.2行中,除了访问页面本身外,我们还访问了页面状态数组,这是vmcache设计所要求的。如第3.6节所述,这种额外的缓存未命中不会显著增加访问延迟,因为两个内存访问是独立的,因此CPU可以并行执行它们。在第2.3行中,我们还包括了版本验证,这实现了完整的vmcache页面访问逻辑。总体而言,这项实验表明,与简单的随机内存读取相比,vmcache中的完整乐观读取仅增加了不到8%的开销。我们测量到,在128 GB RAM上进行独占且无竞争的页面访问(fix和unfix)需要238纳秒(表中未显示)。表中的最后一行显示了基于开放寻址的哈希表实现的性能。即使是这样一个快速的哈希表,也会导致显著更高的延迟,因为页面指针只有在哈希表查找之后才能获得。请注意,我们的哈希表实现是不同步的,因此显示的开销实际上是任何基于哈希表的设计的真实成本的下限。
5.5 exmap的分配性能
分配基准测试。迄今为止的端到端结果表明,exmap在效率上优于标准的Linux页表操作原语。然而,由于我们受限于I/O,我们尚未评估exmap的实际速度。为了量化exmap的性能,我们使用了类似于图3中的分配基准测试场景,即我们不断地成批分配和释放页面。
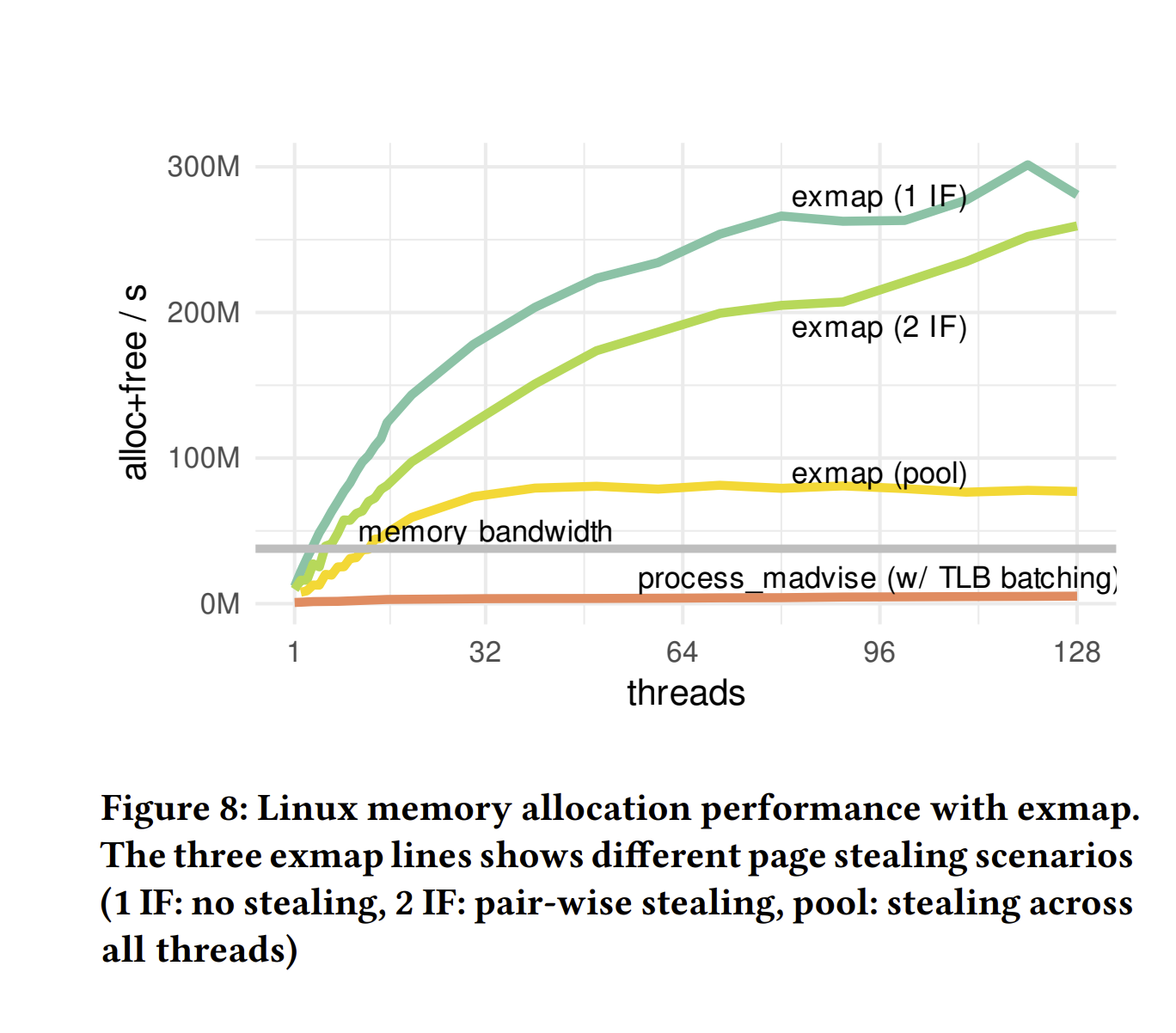
基线。结果如图8所示。我们总是使用512个独立4 KB页面的批量分配/驱逐。作为基线,我们使用带有TLB批处理的process_madvise,这已经需要内核更改。作为参考,我们还显示了通过pmbw基准测试工具和64个线程实现的最大DRAM读取速率(144.56 GiB/s)。如果操作系统提供的内存速度超过这个阈值,我们可以确定内存分配不会成为瓶颈。
页面窃取场景。exmap使用页面窃取,因此其性能取决于特定的线程间分配模式。我们研究了三个不同程度页面窃取的工作负载场景:对于exmap(1 IF),没有发生窃取,因为每个线程分配512个页面,然后在同一接口上再次驱逐它们。exmap(2 IF)类似于1 IF,但每个线程有两个接口,一个用于分配,一个用于驱逐页面。由于内存池足够大(1 GB),很少发生窃取,我们经常窃取超过512个页面,但最终每个页面在每次分配时必须被窃取一次。对于exmap(Pool),一半的线程尽快分配页面,而另一半线程则再次释放这些页面。在这里,内存池总是接近耗尽,窃取频繁发生,但通常不会返回超过512个页面。因此,这种场景是对exmap的最具挑战性的工作负载。
结果。图8 Figure 8显示,exmap在所有场景中都显著优于当前的Linux技术,并且我们达到了301M操作/秒,相当于提供1,150 GiB/s的内存,远超当前DRAM的速度。我们还看到,在低内存压力场景(2 IF)中,页面窃取对性能的影响较小,而高内存压力(Pool)将速率降低了73%。这也证明了我们接口本地空闲列表的成功,并表明应用程序应尽量在每个接口上平衡分配和释放操作,以实现最佳性能。
5.6 exmap的读取I/O性能
I/O库。vmcache和exmap都支持同步(pread)和异步I/O(io_uring和libaio)。通过异步I/O,可以使用更少的线程实现高I/O。在最后的实验中,我们量化了不同用户空间I/O策略的读取吞吐量。为此,N个线程使用同步pread系统调用和Linux的现代异步io_uring接口,在O_DIRECT模式下从我们的三星PM1733 SSD随机读取4 KB块。目标内存是vmcache、exmap或线程本地固定缓冲区(FB)。由于这些FB有固定地址,因此此变体不包括虚拟内存操作的开销,并标志着Linux I/O子系统在相应系统调用接口上的上限。对于io_uring变体,我们使用线程本地提交队列,并允许每个线程有256个未完成的操作。我们将每个读取提交为单独的操作,不使用exmap的分散和向量化读取功能。对于vmcache,我们使用带有TLB批处理的process_madvise进行驱逐,而对于exmap,我们在同一exmap接口上进行读取和驱逐。由于SSD最多可处理128个并行请求,并且具有6 GiB/s的最大随机读取吞吐量,我们感兴趣的是哪种策略可以饱和它,以及需要多少线程才能实现这一点。
I/O性能。在图9 Figure 9中,我们看到,pread变体中每个线程最多只有一个未完成的读取操作,无法饱和SSD。然而,vmcache和exmap都紧跟固定缓冲区变体的吞吐量,因此我们可以得出结论,vmcache的概念在这里不是限制因素。使用io_uring时,单个线程已经可以提交足够的并行读取来理论上饱和SSD,三种变体最终都达到了6 GiB/s的最大值。使用固定缓冲区,3个线程就能饱和SSD,随机读取达到1.58 MIOP/s。使用常规Linux系统调用接口实现vmcache时,我们需要11个线程才能达到相同水平。使用单个线程时,我们达到了固定缓冲区性能的40%。更好的是,使用exmap和io_uring时,我们只需4个线程就能达到6 GiB/s,3个线程时已达到96%。使用单个线程时,exmap达到了单线程FB变体的66%。因此,我们认为,在可以使用多个SSD的现代硬件环境中,exmap是缓冲管理的完美选择。vmcache和exmap都可以与Linux的现成异步I/O一起工作。此外,exmap将虚拟内存开销降至最低,并紧跟性能上限实现(FB)。

5.7 exmap的消融研究
虚拟内存优化。让我们量化第4.4节中提出的exmap优化的影响。为此,我们进行了一个消融研究,代表了高虚拟内存周转率的场景。图10的左侧显示了各个技术如何对exmap的性能做出贡献。对于最基本的变体(参见图10),exmap的性能与madvise相似。然而,对于这种变体,TLB清空占总CPU时间的98.16%,这解释了为什么TLB批处理对端到端性能的影响显著。通过TLB批处理,exmap达到了92.34M操作/秒。我们的下一个优化是添加私有的可扩展页面分配器。通过TLB批处理和私有内存池,exmap达到了267.32M操作/秒。最后,我们启用了无锁页表操作,这进一步加快了随机页面大小表面操作,从而达到286.38M操作/秒(见图10)。通过我们的最终变体,exmap的性能超过现成的madvise大约190倍。

I/O优化。我们的I/O集成技术也对exmap的性能有所贡献。为了量化它们的贡献,我们测量了从null_blk设备(irqmode=0, queue_mode=0)读取到exmap表面的性能。由于null_blk驱动程序的可扩展性问题,我们只显示了单线程性能。从基线开始,读取操作单独发出并引发每次页面错误,我们首先以512个页面的批量预填充表面,从而实现了67%的读取增益。最后,通过代理文件描述符将分配与实际I/O请求结合,我们在512个分散读取的批次中又获得了35%的提升。
6 相关工作
我们已经在第2节中描述了缓冲管理的相关工作,现在我们讨论与虚拟内存和操作系统相关的工作。
在DBMS中利用虚拟内存。除了缓存,虚拟内存操作在其他数据库使用场景中也被证明是有用的,比如查询处理【37】和实现动态数据结构如打包内存数组【26】。在多线程环境中,这些应用程序可能会遇到内核可扩展性问题,因此可能会从我们在第4节中提出的优化中受益。
DBMS/OS协同设计。让我们提到两个最近的DBMS/OS协同设计项目。MxKernel【3】是一个针对多核CPU上数据密集型系统的运行时系统【32】。DBOS【38】的重点是云编排(即管理和协调多个实例)以及使用数据库概念和系统来简化这一任务。再次强调,像exmap这样的技术与这两种设计都是正交的,可以被它们利用。
优化TLB清空。操作系统社区已将TLB清空识别为主要的性能问题,并提出了几种技术,包括批处理,以减轻这一问题【6, 7, 22】。exmap使用了相同的批处理思想来加速虚拟内存操作。
增量虚拟内存改进。现有的关于改进Linux虚拟内存子系统的工作可以分为两类:(1) 加速现有基础设施和(2) 提供新的虚拟内存管理系统。对于第一类,Song等人【39】修改了页面错误处理程序中的分配策略。释放的页面被保存在应用程序本地列表中,而不是直接返回系统,从而使页面能够在应用程序内循环使用。通过exmap,我们将这一点扩展到显式地址的空闲列表,以避免分配路径内的争用。此外,他们通过批量写回操作来减少写I/O路径的开销。Choi等人【10】在munmap上立即删除缓存的VMA,而是将其用于将来的使用。他们还扩展了madvise的内存提示系统,增加了异步预映射等新功能。总体而言,由于Linux虚拟内存子系统的复杂性和通用性,这些增量方法的加速效果有限。Linux虚拟内存系统的另一个瓶颈是VMA列表的管理,该列表存储在一个锁保护的红黑树中。Bonsai【11】使用基于RCU的二叉树提供无锁页面错误处理。在后续工作中,RadixVM【12】加速了非重叠地址范围内的映射操作。由于exmap和vmcache仅使用单个长期存在的VMA,且内存不是通过页面错误隐式分配的,我们不期望这些方法会显著加速,尽管它们与我们的方法是正交的。
新的虚拟内存子系统。增量更改的替代方案是开发专用的Linux虚拟内存子系统。在UMap【35】中,内存映射I/O完全在用户空间中使用userfaultfd处理。通过内存提示进行预取、缓存和驱逐以及可配置的页面大小,他们实现了相对于未修改的Linux最高2.5倍的速度提升。与我们的exmap方法类似,UMap管理绕过Linux内存管理的独立区域。这种方法还通过提供可配置的阈值来影响驱逐策略,赋予应用程序更多的控制权。然而,不同于vmcache,内核仍然控制页面驱逐。此外,用户级页面错误处理引入了系统调用开销,这与提高虚拟内存速度的目标相悖。Papagiannis等人识别了Linux虚拟内存系统中的瓶颈,并提出FastMap【34】作为内存映射文件I/O的替代方案。他们通过每核空闲页面列表以及分离的干净和脏页面树减轻锁争用。他们还识别TLB失效是可扩展性的限制因素,并通过批量TLB清空来解决这一问题。总体而言,他们的实现比未修改的Linux快多达5倍,并提供了高达11.8倍的随机IOPS/s。尽管比Linux的mmap显著更快,UMap和FastMap都没有提供页面驱逐的显式控制,这使它们对数据库系统不具吸引力。
7 总结
vmcache。在本文中,我们提出了虚拟内存辅助的、但由DBMS控制的缓冲管理。通过利用虚拟内存,vmcache不仅快速且可扩展,而且易于实现,支持可变大小页面并支持图数据。基本的vmcache设计仅依赖于广泛可用的操作系统功能,因此具有可移植性。这种功能组合使得vmcache适用于各种数据管理系统。vmcache可在https://github.com/viktorleis/vmcache获得。
exmap。随着快速存储设备的发展,vmcache依赖的页表操作原语可能成为性能瓶颈。为了解决这个问题,我们提出了exmap,一种用于页表操作的专用操作系统接口。我们将exmap实现为一个高效且可扩展的Linux内核模块。当将vmcache与exmap结合使用时,可以充分利用非常快速的存储设备。exmap可在https://github.com/tuhhosg/exmap获得。
致谢
本项目的起源于Dagstuhl研讨会21283“现代内存和存储层次结构的数据结构”中的讨论。本研究由德国研究基金会(DFG,German Research Foundation)资助——项目编号447457559、468988364、501887536。
引用
[1] 2022. LeanStore - A High-Performance Storage Engine for Modern Hardware. https://leanstore.io/.
[2] 2022. Lightning Memory-Mapped Database Manager (LMDB). http://www.lmdb.tech/doc/.
[3] 2022. MxKernel - A Bare-Metal Runtime System for Database Operations on Heterogeneous Many-Core Hardware. https://ess.cs.uos.de/research/projects/MxKernel/.
[4] 2022. Samsung PCIe Gen 4-enabled PM1733 SSD. https://semiconductor.samsung.com/ssd/enterprise-ssd/pm1733-pm1735/mzwlj3t8hbls-00007/.
[5] 2022. WiredTiger Storage Engine. https://docs.mongodb.com/manual/core/wiredtiger/.
[6] Nadav Amit. 2017. Optimizing the TLB Shootdown Algorithm with Page Access Tracking. In USENIX ATC. 27–39.
[7] Nadav Amit, Amy Tai, and Michael Wei. 2020. Don’t shoot down TLB shootdowns!. In EuroSys. 1–14.
[8] Lawrence Benson, Hendrik Makait, and Tilmann Rabl. 2021. Viper: An Efficient Hybrid PMem-DRAM Key-Value Store. PVLDB 14, 9 (2021), 1544–1556.
[9] Jan Böttcher, Viktor Leis, Jana Giceva, Thomas Neumann, and Alfons Kemper. 2020. Scalable and robust latches for database systems. In DaMoN.
[10] Jungsik Choi, Jiwon Kim, and Hwansoo Han. 2017. Efficient Memory Mapped File I/O for In-Memory File Systems. In HotStorage.
[11] Austin T. Clements, M. Frans Kaashoek, and Nickolai Zeldovich. 2012. Scalable Address Spaces Using RCU Balanced Trees. In ASPLOS. 199–210.
[12] Austin T. Clements, M. Frans Kaashoek, and Nickolai Zeldovich. 2013. RadixVM: Scalable Address Spaces for Multithreaded Applications. In EuroSys. 211–224.
[13] Andrew Crotty, Viktor Leis, and Andrew Pavlo. 2022. Are You Sure You Want to Use MMAP in Your Database Management System?. In CIDR.
[14] Dominik Durner, Viktor Leis, and Thomas Neumann. 2019. Experimental Study of Memory Allocation for High-Performance Query Processing. In ADMS. 1–9.
[15] Wolfgang Effelsberg and Theo Härder. 1984. Principles of Database Buffer Management. ACM Trans. Database Syst. 9, 4 (1984).
[16] Goetz Graefe, Haris Volos, Hideaki Kimura, Harumi A. Kuno, Joseph Tucek, Mark Lillibridge, and Alistair C. Veitch. 2014. In-Memory Performance for Big Data. PVLDB 8, 1 (2014), 37–48.
[17] Brendan Gregg. 2016. The flame graph. Commun. ACM 59, 6 (2016), 48–57.
[18] Gabriel Haas, Michael Haubenschild, and Viktor Leis. 2020. Exploiting Directly-Attached NVMe Arrays in DBMS. In CIDR.
[19] Michael Haubenschild, Caetano Sauer, Thomas Neumann, and Viktor Leis. 2020. Rethinking Logging, Checkpoints, and Recovery for High-Performance Storage Engines. In SIGMOD. 877–892.
[20] Alfons Kemper and Donald Kossmann. 1995. Adaptable Pointer Swizzling Strategies in Object Bases: Design, Realization, and Quantitative Analysis. VLDB Journal 4, 3 (1995), 519–566.
[21] Hideaki Kimura. 2015. FOEDUS: OLTP Engine for a Thousand Cores and NVRAM. In SIGMOD. 691–706.
[22] Mohan Kumar, Steffen Maass, Sanidhya Kashyap, Ján Veselý, Zi Yan, Taesoo Kim, Abhishek Bhattacharjee, and Tushar Krishna. 2018. LATR: Lazy Translation Coherence. In ASPLOS. 651–664.
[23] Viktor Leis, Michael Haubenschild, Alfons Kemper, and Thomas Neumann. 2018. LeanStore: In-Memory Data Management beyond Main Memory. In ICDE. 185–196.
[24] Viktor Leis, Michael Haubenschild, and Thomas Neumann. 2019. Optimistic Lock Coupling: A Scalable and Efficient General-Purpose Synchronization Method. IEEE Data Eng. Bull. 42, 1 (2019), 73–84.
[25] Viktor Leis, Florian Scheibner, Alfons Kemper, and Thomas Neumann. 2016. The ART of practical synchronization. In DaMoN.
[26] Dean De Leo and Peter A. Boncz. 2019. Packed Memory Arrays - Rewired. In ICDE. 830–841.
[27] Justin J. Levandoski, David B. Lomet, and Sudipta Sengupta. 2013. The Bw-Tree: A B-tree for new hardware platforms. In ICDE. 302–313.
[28] Gang Liu, Leying Chen, and Shimin Chen. 2021. Zen: a High-Throughput Log-Free OLTP Engine for Non-Volatile Main Memory. PVLDB 14, 5 (2021), 835–848.
[29] David B. Lomet. 2019. Data Caching Systems Win the Cost/Performance Game. IEEE Data Eng. Bull. 42, 1 (2019), 3–5.
[30] Yandong Mao, Eddie Kohler, and Robert Tappan Morris. 2012. Cache craftiness for fast multicore key-value storage. In EuroSys. 183–196.
[31] Maged M. Michael. 2004. Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects. IEEE Trans. Parallel Distributed Syst. 15, 6 (2004), 491–504.
[32] Jan Mühlig and Jens Teubner. 2021. MxTasks: How to Make Efficient Synchronization and Prefetching Easy. In SIGMOD. 1331–1344.
[33] Thomas Neumann and Michael Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. In CIDR.
[34] Anastasios Papagiannis, Giorgos Xanthakis, Giorgos Saloustros, Manolis Marazakis, and Angelos Bilas. 2020. Optimizing Memory-mapped I/O for Fast Storage Devices. In USENIX ATC. 813–827.
[35] Ivy Peng, Marty McFadden, Eric Green, Keita Iwabuchi, Kai Wu, Dong Li, Roger Pearce, and Maya Gokhale. 2019. UMap: Enabling application-driven optimizations for page management. In IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC). 71–78.
[36] Filip Pizlo. 2016. Locking in WebKit. https://webkit.org/blog/6161/locking-in-webkit/.
[37] Felix Martin Schuhknecht, Jens Dittrich, and Ankur Sharma. 2016. RUMA has it: Rewired User-space Memory Access is Possible! PVLDB 9, 10 (2016), 768–779.
[38] Athinagoras Skiadopoulos, Qian Li, Peter Kraft, Kostis Kaffes, Daniel Hong, Shana Mathew, David Bestor, Michael J. Cafarella, Vijay Gadepally, Goetz Graefe, Jeremy Kepner, Christos Kozyrakis, Tim Kraska, Michael Stonebraker, Lalith Suresh, and Matei Zaharia. 2021. DBOS: A DBMS-oriented Operating System. PVLDB 15, 1 (2021), 21–30.
[39] Nae Young Song, Yongseok Son, Hyuck Han, and Heon Young Yeom. 2016. Efficient memory-mapped I/O on fast storage device. ACM Transactions on Storage (TOS) 12, 4 (2016), 1–27.
[40] Michael Stonebraker. 1981. Operating System Support for Database Management. Commun. ACM 24, 7 (1981), 412–418.
[41] Alexander van Renen, Viktor Leis, Alfons Kemper, Thomas Neumann, Takushi Hashida, Kazuichi Oe, Yoshiyasu Doi, Lilian Harada, and Mitsuru Sato. 2018. Managing Non-Volatile Memory in Database Systems. In SIGMOD. 1541–1555.
[42] Ziqi Wang, Andrew Pavlo, Hyeontaek Lim, Viktor Leis, Huanchen Zhang, Michael Kaminsky, and David G. Andersen. 2018. Building a Bw-Tree Takes More Than Just Buzz Words. In SIGMOD. 473–488.
[43] Xinjing Zhou, Joy Arulraj, Andrew Pavlo, and David Cohen. 2021. Spitfire: A Three-Tier Buffer Manager for Volatile and Non-Volatile Memory. In SIGMOD. 2195–2207.
注释
The page table, which is an in-memory data structure, itself is coherent across CPU cores. However, a CPU core accessing memory caches virtual to physical pointer translations in a per-core hardware cache called TLB. If the page table is changed, the hardware does not automatically update or invalidate existing TLB entries.
On Windows these primitives are available as VirtualAlloc(..., MEM_RESERVE, ...) and VirtualFree(..., MEM_RELEASE).
Strictly speaking, the OS could decide to evict vmcache pages – but this does not affect the correctness of our design. OS-triggered eviction can be prevented by disabling swapping or by mlocking the virtual memory range
If a page translation is cached in the TLB of a particular thread, the thread does not have to consult the page table.
For example, Linux usually maintains a reverse mapping from physical to virtual addresses that is necessary to implement features such as copy-on-write fork.
We measured the I/O bound for this experiment using the fio benchmarking and 128 threads doing synchronous random I/O operations.