

10 Rules for Scalable Performance in ‘Simple Operation’ Datastores
简单操作数据存储系统中可扩展性能的 10 条规则
将数据分区而后操作,坚持管理简单,对所有情况不进行单一化假设 do not assume one size fits all。
本文来自 acm-tod,下载地址,本文仅供学习使用,禁止用于任何商业用途
以下是正文部分。

关系数据模型由 Ted Codd 于 1970 年提出,作为解决当时数据库管理系统(DBMS)问题的最佳方案——商业数据处理。早期的关系系统包括 System R 和 Ingres,几乎所有现今的商业关系数据库管理系统(RDBMS)实现都可以追溯到这两个系统。因此,除非仔细观察,否则主要的商业供应商——Oracle、IBM 和 Microsoft,以及主要的开源系统——MySQL 和 PostgreSQL,今天看起来大同小异;我们将这些系统称为通用传统行存储系统(GPTRS general-purpose traditional row stores),它们具有以下特点:
面向磁盘的存储;
数据表按行存储在磁盘上,因此为行存储;
使用 B 树作为索引机制;
使用动态锁定作为并发控制机制;
使用预写日志(
WAL)进行崩溃恢复;使用
SQL作为访问语言;行导向
row-oriented的查询优化器和执行器,最初由 System R 开创。
key insights
过去五年中,已经引入了许多可扩展的 SQL 和 NoSQL 数据存储,专为 Web 2.0 及其他超出单服务器关系数据库管理系统(RDBMS)容量的应用设计。
这些新型数据存储在以下方面存在显著差异:一致性保证、每台服务器的性能、读写负载的可扩展性、服务器故障的自动恢复、编程的便利性以及管理的简便性。
应用程序必须为可扩展性而设计,包括将应用数据划分为“分片”(shards),避免跨分区操作,设计以并行处理为核心,并在一致性保证的需求上进行权衡。
1970 年代和 1980 年代的主要数据库市场是商业数据处理,即现在称为在线事务处理(OLTP online transaction processing)。从那时起,数据库系统开始被用于各种新市场,包括数据仓库、科学数据库、社交网络网站和游戏网站;现代数据库市场的特点如图所示。
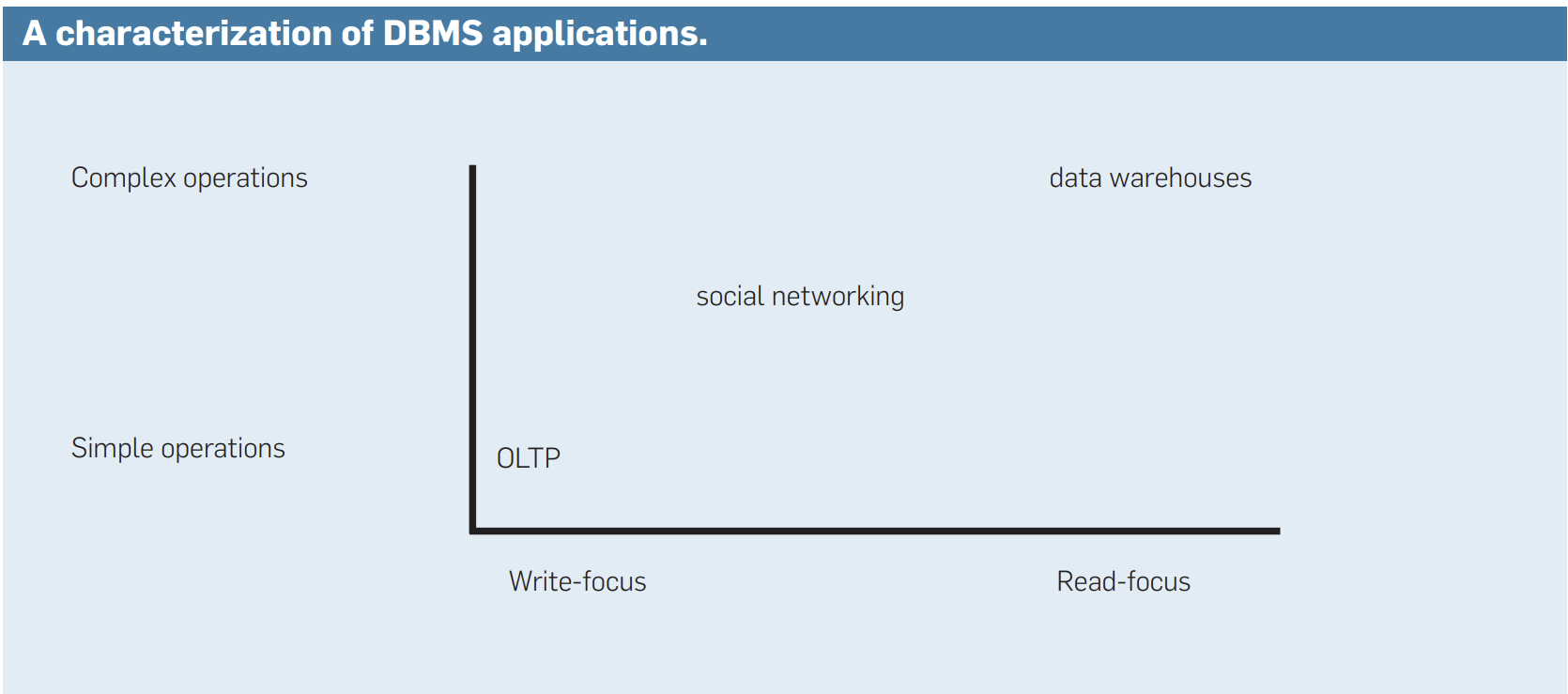
图中包括两个轴:
水平轴表示应用程序是侧重读还是侧重写
垂直轴表示应用程序执行的是简单操作(读或写少量项)还是复杂操作(读或写大量项)
例如,传统的 OLTP 市场是写重且操作简单的,而数据仓库市场是读重且操作复杂的。当然,许多应用程序介于两者之间;例如,社交网络应用主要涉及简单操作,但也有读写的平衡。因此,图应被视为两个方向上的连续体,任何给定的应用程序都位于其中的某个位置。
主要的商业引擎和开源实现的关系模型被定位为一刀切 one-size-fits-all系统;即,它们声称适用于图中的所有位置。然而,一刀切的方案也存在一些不满。例如,数据仓库市场中所谓的列存储的商业成功就是证明。这些产品仅从磁盘中检索查询中所需的列,消除了未使用数据的开销。此外,由于每个存储块上只有一种对象,列存储能够实现更好的压缩和索引。最后,通过对压缩数据进行查询执行,节省了主内存带宽。由于这些原因,列存储在典型的数据仓库工作负载中比行存储快得多,我们预计它们会在未来主导数据仓库市场。
我们在这里的重点是简单操作(SO simple-operation)应用程序,即图的下半部分。相当多的新型非 GPTRS 系统已被设计用于为这个市场提供可扩展性。大致而言,我们将它们分为以下四类:
键值存储
Key-value stores:包括Dynamo、Voldemort、Membase、Membrain、Scalaris和Riak。这些系统具有最简单的数据模型:一组对象,每个对象都有一个key和一个payload,几乎不能将payload解释为多属性对象,也没有用于非键的查询机制;文档存储
Document stores:包括CouchDB、MongoDB、SimpleDB和Terrastore,其中的数据模型由具有可变数量属性的对象组成,有些属性允许嵌套对象。对象集合通过对多个属性的约束进行搜索,使用(non-SQL)查询语言或过程机制;可扩展记录存储
Extensible record stores:包括BigTable、Cassandra、HBase、HyperTable和PNUTS,提供可变宽度的记录集,可以在多个节点上垂直和水平分区。它们通常不是通过 SQL 访问的;SQL 数据库管理系统
SQL DBMSs:专注于 SO 应用程序的可扩展性,包括 MySQL Cluster、其他 MySQL 派生产品、VoltDB、NimbusDB 和 Clustrix。它们保留了 SQL 和 ACID(原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability)事务,但其实现通常与 GPTRS 系统非常不同。
我们并不声称这一分类是准确或详尽的,尽管它涵盖了主要的新兴类别。此外,市场变化迅速,因此建议读者查阅其他最新来源。有关这些系统的更详细讨论和参考,请参见 Cattell 和下表。
Systems | Link |
|---|---|
Asterdata | |
BigTable | |
Clustrix | |
CouchDB | |
DB2 | |
Dynamo | |
Exadata | |
Greenplum | |
Hadoop | |
HBase | |
HyperTable | |
MongoDB | |
MySQL | |
MySQL Cluster | |
Netezza | |
NimbusDB | |
Oracle | |
Oracle RAC | |
Paraccel | |
PNUTs | |
PostgreSQL | |
Riak | |
Scalaris | |
SimpleDB | |
SQL Server | |
Teradata | |
Terrastore | |
Tokyo Cabinet | |
Vertica | |
Voldemort | |
VoltDB |
NoSQL 运动主要由前三类系统推动,通过仅允许单记录操作作为事务和/或通过放宽 ACID 语义(例如,仅支持数据的“最终一致性”)来限制传统的 ACID 事务概念。
这些系统的驱动力各不相同。
对于一些数据库来说,是对关系模型或 RDBMS 的“沉重性”不满;
对于另一些人来说,是由于一些大型 Web 企业面临最苛刻的服务级别(SO)问题。
这些大型 Web 企业通常是那些幸运地经历了爆炸性增长的初创公司,所谓的曲棍球棒效应
hockey-stick effective。它们通常使用开源数据库管理系统(DBMS),因为它是免费的或工作人员已经熟悉。通常在版本 1 中会搭建一个单节点的 DBMS 解决方案,但很快会出现可扩展性问题。传统的解决方法是分片shard,即将应用程序数据分区到多个节点上以共享负载。例如,一张表可以通过这种方式进行分区;员工姓名可以分到 26 个节点上,将所有“A”开头的员工姓名放在节点 1,以此类推。此时,由应用程序逻辑来确保每个查询和更新都指向正确的节点。然而,在应用程序逻辑中实现这种分片有许多严重的缺陷:
如果必须执行跨分片的过滤器或连接操作,必须在应用程序中进行编码;
如果需要在事务中对多个分片进行更新,那么应用程序负责以某种方式确保跨节点的数据一致性;
随着系统扩展,节点故障变得更加常见。一个棘手的问题是如何维护一致的副本,检测故障,故障转移到副本,并在系统运行时替换故障节点;
不“下线”分片的情况下进行模式更改是一个挑战;
重新配置硬件以添加节点或更改配置非常繁琐,尤其是当分片无法下线时,这会变得更加困难。
许多开发分片 Web 应用的开发者遭遇了极大的困扰,因为他们必须在应用层逻辑中实现这些功能。NoSQL 运动的目标正是解决这个痛点。然而,随着新系统的大量涌现及其采用的各种方法,客户可能会难以理解和选择适合其应用需求的系统。在这里,我们提出了 10 条建议,供任何有服务级别(SO)应用的客户参考,同时在评估非 GPTRS 系统时考虑。这些建议是 DBMS 要求和有关良好 SO 应用设计的指导原则的结合。尽管我们是在客户自有环境中运行软件的背景下陈述这些建议,但大多数也适用于软件即服务(SaaS Software-as-a-service)环境。
我们将逐条列出每个规则,然后说明其必要性:
1. Look for shared-nothing scalability
选择无共享架构的可扩展性
DBMS(数据库管理系统)可以运行在三种硬件架构上:
共享内存多处理(SMP
Symmetric Multiprocessing):这是最早的架构形式,DBMS 运行在一个节点上,由共享内存和磁盘系统的一组核心组成。SMP 的可扩展性受限于主内存带宽,因此只能扩展到相对较少的核心数量。尽管未来的系统核心数量会增加,但尚不清楚主内存带宽是否会随之成比例地增加。因此,多核系统在使用 DBMS 软件时面临性能限制。选择 SMP 系统的客户为了在多个 SMP 节点上实现可扩展性,往往不得不自行执行分片操作,从而面临之前提到的复杂问题。运行在 SMP 配置上的常见系统包括 MySQL、PostgreSQL 和 Microsoft SQL Server。共享磁盘集群
share a common disk system:第二种选择是选择运行在磁盘集群上的 DBMS,在这种架构中,拥有私有主内存的多个 CPU 节点共享同一个磁盘系统。这种架构在 1980 年代和 1990 年代由 DEC、HP 和 Sun 推广,但在 DBMS 上存在严重的可扩展性问题。由于每个节点的主内存中都有私有的缓冲池,因此同一个磁盘块可能会出现在多个缓冲池中,从而需要对这些缓冲池块进行严格的同步。此外,每个节点的主内存中还包含私有的锁表,同样需要小心同步,这限制了共享磁盘架构的可扩展性,通常只能扩展到 10 个以内的节点。Oracle RAC 是一个运行在共享磁盘上的流行 DBMS 示例,具有双位数节点数的 RAC 配置极为罕见。Oracle 最近推出了 Exadata 和 Exadata 2,运行在两层架构的顶层使用共享磁盘,而底层则使用无共享架构。无共享架构
shared-noting:最后一种架构是无共享架构,节点既不共享主内存也不共享磁盘,而是通过网络连接一组独立的节点。自 1995 年以来,几乎所有面向数据仓库市场的 DBMS 都运行在无共享架构上,包括Greenplum、Vertica、Asterdata、Paraccel、Netezza和Teradata。此外,DB2 可以运行在无共享架构上,许多 NoSQL 引擎也是如此。无共享引擎通常通过自动分片(分区)来实现并行处理。只有在数据对象均衡分布在系统节点之间时,无共享系统才能扩展。如果存在数据偏斜或“热点”,则无共享系统的性能会降至负载过重的节点的速度。应用程序还必须保证大多数事务是“单分片”的,关于这一点在规则 6 中会进一步讨论。
除非受限于应用程序数据或操作的偏斜,否则设计良好的无共享系统应能够持续扩展,直到网络带宽耗尽或满足应用程序需求。据报道,许多 NoSQL 系统运行在 100 个以上的节点上,BigTable 据说运行在数千个节点上。
Web 应用的 DBMS 需求可以迅速推动 DBMS 的可扩展性;例如,Facebook 最近在应用逻辑中分片了 4,000 个 MySQL 实例。如果 Facebook 选择一个 DBMS,它至少需要扩展到这一数量的节点。SMP 或共享磁盘 DBMS 在这种级别的可扩展性上无法竞争,无共享 DBMS 是唯一的选择。Shared-nothing DBMSs are the only game in town
2. High-level languages are good and need not hurt performance
高级语言是好的,并且不一定会影响性能
在 SQL 事务中,运行可能包括以下几个组成部分:
优化器选择了一个次优的执行计划所带来的开销;
与 DBMS 进行通信的开销;
使用高级语言编码的固有开销;
提供服务(例如并发控制
concurrency control、崩溃恢复crash recovery和数据完整性data integrity)带来的开销;不论如何都需要执行的真正有用的工作。
在这里,我们讨论前三个问题,将后两个留给规则 3。层次结构和网络系统在 1960 年代和 1970 年代是主导的 DBMS 解决方案,它们为数据提供了低级过程接口。RDBMS 的高级语言在取代这些 DBMS 方面发挥了重要作用,原因有三:
高级语言系统要求程序员编写更少的代码,并且这些代码更容易理解;
可维护性用户陈述他们想要的内容,而不是编写一个面向磁盘的算法来访问他们需要的数据;程序员不需要理解复杂的存储优化;
隐藏复杂度高级语言系统更有可能在模式发生变化时让程序得以存活,无需维护或重新编码;因此,低级系统需要更多的维护。
可移植性
在 1970 年代和 1980 年代,针对 RDBMS 的一个指责是,它们不能像低级系统那样高效。有人声称,自动查询优化器无法像聪明的程序员那样做得好。尽管早期的优化器很原始,但它们很快就达到了除了最优秀的人类程序员外的同等水平。而且,大多数组织从未能吸引和留住这种水平的人才。因此,这种开销的来源在很大程度上已经消失,如今只在极少数 SO 应用中出现非常复杂的查询时才成为问题。
第二个开销来源是与 DBMS 的通信。出于安全原因,RDBMS 坚持应用程序在一个单独的地址空间中运行,并使用 ODBC 或 JDBC 与 DBMS 交互。这些通信协议的开销很高;运行一个 SQL 事务需要通过 TCP/IP 进行几次往返的消息传递。因此,任何对性能真正感兴趣的程序员都会通过存储过程接口运行事务,而不是通过 ODBC/JDBC 执行 SQL 命令。在存储过程的情况下,事务是一个单一的往返消息。DBMS 通过将多个事务批处理在一个调用中进一步减少了通信开销。通信成本取决于所选择的接口,可以最小化,与交互的语言级别无关。
第三个开销来源是使用 SQL 编码,而不是使用低级过程low-level procedural语言。由于大多数严肃的 SQL 引擎都编译成机器代码,或者至少编译成类似 Java 的中间表示a Java-style intermediate representation,这种开销并不大;即标准的语言编译将高级规范转换为非常高效的低级运行时可执行程序。
[NOTE!]
这里译者发表一下个人意见,Java-style只是不适合这种场景,并不意味着Java的编译策略有问题,恰恰相反,Write Once, Run Anywhere的特性,要求它需要一个中间表示,在安全性,编译灵活性,编译时间上都是不错的策略选择。
因此,过去 25 年在 DBMS 领域的一个关键经验教训是:高级语言是好的,并且不会影响性能。一些新系统提供 SQL 或更有限的高级语言;其他系统仅提供“数据库汇编语言”或单个索引和对象操作。这种低级接口可能适用于非常简单的应用程序,但在所有其他情况下,高级语言提供了令人信服的优势。
3.Plan to carefully leverage main memory databases
谨慎规划利用主内存数据库。 考虑一个由 16 个节点组成的集群,每个节点有 64GB 的主内存。任何无共享 DBMS 因此都可以访问大约 1TB 的主内存。这种硬件配置几年前可能被认为是极端的,但如今已经非常普遍。此外,未来每个节点的内存将会增加,集群中的节点数量也可能增加。因此,未来典型的集群将会有越来越多的 TB 级主内存。
因此,如果数据库的大小是几 TB 或更小(一个非常大的 SO 数据库),客户应考虑使用主内存进行部署。如果数据库更大,客户应在实际情况下尽量考虑主内存部署。此外,随着价格的下降,闪存已经成为一种有前景的存储介质。
鉴于 RAM 相对于磁盘的随机访问速度,DBMS 潜在地可以快上千倍。然而,DBMS 必须正确架构才能有效利用主内存;仅仅在内存更大的机器上运行 DBMS 只能实现有限的改进。
要理解原因,考虑 DBMS 中的 CPU 开销。在 2008 年,Harizopoulos 等人通过部分主要 SO 基准测试 TPC-C 测量了性能,他们使用的是开源 DBMS Shore。选择这个 DBMS 是因为源代码可用于插装分析,并且它是一个典型的 GPTRS 实现。基于对其他 GPTRS 系统的简单衡量,Shore 的结果也能代表这些系统。
Harizopoulos 等人使用了一个数据库,其所有数据都能装入主内存,这与大多数 SO 应用一致。由于 Shore 和其他 GPTRS 系统一样是基于磁盘的,这意味着所有数据都会驻留在主内存缓冲池中。他们的目标是对 TPC-C 上的 DBMS 开销进行分类;他们让 DBMS 在与应用驱动程序相同的地址空间中运行,避免了任何 TCP/IP 开销。然后,他们观察了 CPU 使用中哪些部分执行了有用的工作或提供了 DBMS 服务。
以下是 TPC-C 中新订单事务的各项任务的 CPU 周期使用情况;由于 Harizopoulos 等人指出了大多数商业 GPTRS 中已经修复的一些缺陷,这些结果已经过调整,以假定去除了这些开销来源:
有效工作(13%)
Useful work:这是实际查找相关记录并执行相关属性的检索或更新的 CPU 成本;锁定(20%)
Locking:这是设置和释放锁、检测死锁以及管理锁表的 CPU 成本;日志记录(23%)
Logging:当记录被更新时,变更前后的像前后像 before image and after image会被写入日志。Shore 然后将事务分组在“组提交”中,将相关日志部分强制写入磁盘;缓冲池开销(33%)
Buffer pool overhead:由于所有数据都驻留在缓冲池中,任何检索或更新都需要在缓冲池中找到相关的块。然后必须定位相关记录,并找到记录中的相关属性。在有开放数据库游标的块上,必须将这些块钉住pinned在主内存中。此外,还需要使用最近最少使用(LRU)或其他替换算法,要求记录额外的信息;多线程开销(11%)
Multithreading overhead:由于大多数 DBMS 都是多线程的,多个操作并行进行。不幸的是,锁表是一个共享的数据结构,必须通过“闩锁”来序列化各并行线程的访问。此外,B 树索引和资源管理信息也必须以类似方式保护。访问共享数据结构时,必须设置和释放闩锁(互斥锁)。更多细节讨论见 Harizopoulos 等人的研究,其中还包括闩锁开销可能被低估的原因。
显然,传统基于磁盘的 DBMS 绝大多数的CPU周期都消耗在开销活动上。要大幅提高速度,DBMS 必须避免这里讨论的所有开销组件;例如,一个具有传统多线程、锁定和恢复的主内存 DBMS 仅比其基于磁盘的同类稍快。如果这些开销组件没有被处理,或者 GPTRS 解决方案没有被正确架构(例如使用交互式 SQL 而不是编译的存储过程接口),那么 NoSQL 或其他数据库引擎不会比 GPTRS 实现表现得好很多。
我们在分析中关注单机性能,但这种性能对规则 1 中讨论的多机可扩展性,以及我们其他规则都有直接影响。
[NOTE!]
以译者经历过的高并发高负载场景,通过扩大内存进而扩大共享缓冲区,将更多的热数据加载入内存中,进而减少waitIO,降低进程队列等待,确实是个降低负载的有效办法。但是过大的共享缓冲区对检查点是个挑战,根治负载过高还是通过读写分离,分库分表等手段才是治疗根本的手段。
4. High availability and automatic recovery are essential for SO scalability.
高可用性和自动恢复对于 SO 可扩展性至关重要。
在1990年,一般的DBMS应用程序会运行在我们现在认为非常昂贵的硬件上。如果硬件故障,客户会恢复工作中的硬件,重新加载操作系统和DBMS,然后通过撤销未完成的事务以及使用DBMS日志重做已完成的事务,将数据库恢复到最后一个已完成事务的状态。这个过程可能需要一定的时间(几分钟到一个小时或更长时间),在此期间,应用程序将不可用。
如今,大多数客户都不愿意接受SO应用程序的任何停机时间,大多数客户希望运行冗余硬件,并使用数据复制来维护所有对象的副本。一旦硬件发生故障,系统会切换到备份继续运行。实际上,客户希望实现像1980年代Tandem Computers率先实现的“不间断”运行。
此外,许多大型Web服务运行在大量的无共享节点配置上,随着“活动部件”的增加,故障的概率也会上升。这种故障率使得在人为干预的恢复过程中变得不切实际;因此,无共享DBMS软件必须能够自动检测并修复故障节点。
任何用于SO应用程序的DBMS都应具有内置的高可用性功能,支持不间断的运行。对于高可用性,有三点注意事项需要解决。首先是有许多不同类型的故障,包括:
应用程序故障,应用程序破坏数据库;
DBMS故障,可重复重现的(所谓的Bohr bugs);
DBMS故障,无法重现的(所谓的Heisenbugs);
各种类型的硬件故障;
网络数据包丢失;
拒绝服务攻击;
网络分区
network partitions。网络分区这里应该指的是脑裂
brain-split
任何DBMS都能够在某些故障模式下继续运行,但不是所有故障模式。完全从所有可能的故障模式中恢复的成本非常高。因此,高可用性是一种统计上的努力,或者说是针对特定类别的故障希望达到的可用性水平。
第二个注意事项是所谓的CAP定理,即一致性consistency、可用性availability和分区容忍性partition-tolerance定理。该定理指出,在某些故障的情况下,分布式系统只能具备这三个特性中的两个:一致性、可用性和分区容忍性。因此,在高可用性领域存在理论上的限制。
此外,许多站点管理员希望防范灾难(如地震和洪水)。尽管罕见,但从灾难中恢复很重要,应被视为高可用性的延伸,通过广域网进行复制来支持。
5. Online Everything
所有操作在线化。
一个 SO DBMS 应该只有一种状态:运行中up。
从用户的角度来看,它不应该发生故障,也不应该需要下线。7*24
除了故障恢复外,我们还需要考虑许多当前实现中需要将数据库下线的操作:
模式变更。必须在不中断服务的情况下向现有数据库中添加属性;
索引变更。应该在不中断服务的情况下添加或删除索引;
重新配置。应该可以在不中断服务的情况下增加用于处理事务的节点数量;例如,一个配置可能从 10 个节点增加到 15 个节点,以适应负载的增加;
软件升级。应该可以在不中断服务的情况下将 DBMS 从版本 N 升级到版本 N + 1。
虽然支持这些操作是一个挑战,但 100% 的正常运行时间应该是目标。随着一个 SO 系统扩展到几十个节点和/或数百万互联网用户,停机时间和人工干预是不现实的。
6. Avoid multi-node operations
规则 6:避免多节点操作。
实现 SO 在服务器集群上扩展的两个必要特性是:
均匀分割Even split。必须将数据库和应用负载均匀地分布到服务器上。通过复制数据可以实现读取扩展性,但一般的读/写扩展性要求根据主键将数据分片(分区)到不同节点上;后者的读写一致性要求更高
扩展性优势Scalability advantage。应用程序很少执行跨越多个服务器或分片的操作。如果处理一个操作涉及大量服务器,那么由于冗余工作redundant work、跨服务器通信cross-server communication或所需操作的同步,扩展性优势可能会丧失。
假设某客户有一个员工表,并根据员工年龄对其进行分片。如果想知道某个特定员工的工资,则必须将查询发送到所有节点,这需要大量的消息传递。只有一个节点会找到所需数据;其他节点将运行一个冗余查询,结果什么也没有找到。此外,如果一个应用程序执行一个跨分片的更新操作,比如给鞋部门的所有员工加薪,那么系统必须承担所有同步开销,以确保在每个节点上都执行了事务。
因此,数据库管理员(DBA)应选择一个分片键sharding key,使尽可能多的操作成为单分片操作。幸运的是,如果数据分片得当,大多数应用程序自然涉及单分片事务;例如,如果采购订单(PO production orders)及其详细信息都根据 PO 号分片,那么绝大多数事务(如新 PO 和更新特定 PO)只会发往单个节点。
通过复制只读数据可以进一步增加单节点事务的比例;例如,客户和他们地址的列表可以在所有节点进行复制。在许多企业对企业的环境中,客户的增加、删除或地址变更的频率很低。因此,完全复制允许将客户地址插入新的 PO 中作为单节点操作。因此,选择性地复制以读为主read-mostly的数据可能具有优势。
总结来说,程序员应尽量避免多分片multi-shard操作,包括必须访问多个分片的查询以及需要 ACID 特性的多分片更新。客户应仔细考虑他们的应用程序和数据库设计,以实现这一目标。如果现有的应用程序设计无法实现该目标,他们应考虑进行重新设计,以实现更高的单分片操作single-shardedness。
7. Don’t try to build ACID consistency yourself
不要尝试自己构建 ACID 一致性。 总的来说,我们提到的键值存储、文档存储和可扩展记录存储已经放弃了事务性的 ACID 语义,转而采用了较弱的原子性、隔离性和一致性形式,提供了一种或多种以下替代机制:
在每次写入时创建对象的新版本,导致当有多个异步写入时出现并行版本;应用逻辑需要解决由此产生的冲突;
提供当前更新
update-if-current操作,该操作只有在对象匹配指定的值时才会更改它;这样,应用程序可以读取它打算稍后更新的对象,并且只有当该值仍然是当前值时才会进行更改;仅为单个对象、属性或分片的读写操作提供 ACID 语义;
提供法定人数
quorum读写操作,可确保在“最终一致”的副本之间获取最新版本。
在这些系统上构建自己的 ACID 语义是可能的,只要有足够的额外代码。然而,这项任务非常困难,我们不会希望最讨厌的人去做。如果你需要 ACID 语义,应该使用提供它的 DBMS;在 DBMS 级别处理这些问题要比在应用程序级别容易得多。
所以中间件一般都是大型项目,其中的复杂度和熵增是一般人掌控不住的,就像这段话后面说的,DBMS提供了现成的ACID特性,而目前以postgresql为代表的数据库以插件为手段,实现了All in One 的特性,你不用再为项目上复杂的技术栈和ACID发愁了
任何需要协调更新两个对象的操作都可能需要 ACID 保证。考虑一个交易,将 10 美元从一个用户账户转到另一个用户账户;在 ACID 系统中,程序员可以简单地编写:
Begin transaction
Decrement account A
Increment account B
Commit transaction 没有 ACID 系统,就没有简单的方法来执行这一协调操作。其他需要 ACID 语义的情况包括仅在客户的订单发货时扣款,并同步更新双边的“朋友”引用。标准的 ACID 语义为程序员提供了维护数据完整性所需的“全有或全无”保证。虽然某些应用程序不需要这种协调,但承诺使用非 ACID 系统意味着将来无法以需要协调的方式扩展这些应用程序。DBMS 应用程序通常寿命很长,可能会遇到未知的未来需求。
我们理解 NoSQL 运动放弃事务的动机,因为他们认为事务更新在传统 GPTRS 系统中成本高昂。然而,较新的 SQL 引擎通过仔细消除规则 3 中的所有开销,至少对于遵守规则 6(避免多节点操作)的应用程序,可以同时提供 ACID 和高性能。如果你需要 ACID 事务并且无法遵循规则 6,那么无论是自己编写 ACID 代码,还是让 DBMS 处理,你都可能会产生相当大的开销。让 DBMS 处理这是显而易见的选择。
我们听到了一些基于 CAP 定理 的放弃 ACID 事务的论点,称你只能拥有三个特性中的两个:一致性(C)、可用性(A)和分区容忍性(P)。这个论点认为分区是不可避免的,因此为了实现高可用性必须放弃一致性。我们对这个观点提出了三点质疑: 第一,某些应用确实需要一致性,无法放弃它。 第二,如规则 4 中指出的,CAP 定理仅处理了一部分可能的故障,仍然需要应对剩下的情况。 第三,我们不相信对于局域网(LAN)上的分片数据,分区是一个重大问题,特别是在有冗余局域网和同一站点上的应用程序的情况下;在这种情况下,分区可能很少发生,人们在遇到非常罕见的事件时,最好选择一致性(始终选择)而不是可用性。
虽然广域网(WAN)分区比局域网分区更常见,但广域网复制通常用于只读副本或灾难恢复(例如,当整个数据中心离线时);广域网延迟太高,无法用于同步复制或分片。很少有用户希望在不出现短暂可用性中断的情况下从重大灾难中恢复,因此 CAP 定理在这种情况下可能不那么相关。
我们建议需要 ACID 的客户寻找提供 ACID 的 DBMS,而不是自己编写代码,通过良好的数据库和应用设计来最大限度地减少分布式事务的开销。
真心给最后这句建议一个大大的赞,鼓吹分布式忽略它的复杂度往往是小白新手容易犯的错误,一个好的项目好的技术架构往往是各方面综合博弈后,打磨出来的。
8. Look for administrative simplicit
注重管理的简便性。
我们最常抱怨关系型 DBMS 的一个问题就是它们开箱即用时表现不佳。大多数产品都包含许多调优选项,可以调整 DBMS 的行为;而且,根据我们的经验,一个熟练的 DBA 可以让某个厂商的产品运行速度比不熟练的 DBA 快两倍甚至更多。
事实上,性能调优和上面的工作一样,DBA虽然重要,但是调优工作往往不仅仅是调参。
因此,采用一个新 DBMS 尤其是分布式的 DBMS 是一项艰巨的任务。这需要进行安装、模式构建、应用设计、数据分布、调优和监控。即便是获得 TPC-C 基准测试的高性能版本也需要数周时间,尽管代码和模式是现成的。此外,一旦应用投入生产,它仍然需要大量的 DBA 资源来保持运行。
在考虑一个新的 DBMS 时,应该仔细考虑开箱即用的体验。绝不要让厂商为你做概念验证练习。你应该亲自进行概念验证,以便近距离了解开箱即用的情况。同时,在做出决定时,应仔细考虑应用监控工具。
最后,要特别注意规则 5。大多数系统中一些最棘手的管理问题(如模式更改和重新配置)都需要人工干预。
9. Pay attention to node performance
关注节点性能。
如今常听到的一句口号是“追求线性可扩展性;这样你总是可以配置资源来满足应用需求,而节点性能就不那么重要了。”虽然线性可扩展性确实很重要,但忽视节点性能是一个重大错误。应该始终记住,线性可扩展性意味着整体性能是节点数量乘以节点性能的乘积。节点性能越快,所需的节点就越少。
解决方案在节点性能上通常相差一个数量级或更多;例如,在 DBMS 风格的查询中,并行 DBMS 的性能比 Hadoop 高出一个数量级以上。同样,H-store(VoltDB 的原型前身)在 TPC-C 基准测试中的吞吐量已经被证明比主要厂商的产品更高。例如,假设某客户在两个数据库解决方案之间进行选择,每个都提供线性可扩展性。如果解决方案 A 的节点性能比解决方案 B 高 20 倍,那么使用解决方案 A 的客户可能只需要 50 个硬件节点,而使用解决方案 B 则需要 1,000 个节点。
这两种解决方案在硬件成本、机架空间、冷却和电力消耗上的巨大差异显然不可忽视。更重要的是,如果每个节点平均每三年故障一次,那么解决方案 B 每天都会出现一次故障,而解决方案 A 每月故障不到一次。这种显著的差异将极大地影响冗余的配置程度以及处理可靠性问题所需的管理时间。节点性能可以使其他一切变得更容易。
10. Open source gives you more control over your future
开源能让你对未来有更多的控制权。
这个最终规则并不是一个技术点,但仍然值得一提,因此,或许它更应该是一个建议而不是一个规则。现实中有很多这样的情况:公司购买了某个厂商的产品,结果在随后的几年里不得不面对昂贵的升级费用、巨大的维护账单,而这些费用往往是为了获得低劣的技术支持,并且由于切换到其他产品的成本高昂(需要大量的重新编码),公司无法避免这些费用。避免“厂商不良行为”的最佳方法是使用开源产品。开源软件消除了昂贵的许可费用和升级费用,通常还提供多种替代支持、新功能和修复 bug 的方式,甚至包括自行开发的选项。
护驾还是绑架,你本将心照明月,奈何厂商把你耍。
出于这些原因,许多新的面向 Web 的公司坚持只使用开源系统。此外,多个厂商已经证明,使用开源模式是可以建立可行的商业模式的。我们预计这种趋势在未来会更加流行,并建议客户认真考虑开源的优势。
结论 我们提出的这10条规则明确了任何SO数据存储的理想属性。对于那些在寻找分布式数据存储解决方案的客户,建议在考虑这些系统时,将它们置于这些规则的框架内进行评估,同时也要结合自身独特的应用需求。如今可用的系统数量众多,其能力和局限性差异很大。
致谢 我们要感谢Andy Pavlo、Rick Hillegas、Rune Humborstad、Stavros Harizopoulos、Dan DeMaggio、Dan Weinreb、Daniel Abadi、Evan Jones、Greg Luck 和 Bobbi Heath 对本文提供的宝贵意见。