

网卡绑定
网络基础知识
这部分是前置扫盲环节,如果网络基础,可以跳过直接下面的内容。
七层网络协议

OSI 七层网络模型往往是我们进行理论学习的开门课程,但是工程上往往采用 TCP/IP 4/5 层:
应用层(L7) ≈ OSI(7/6/5) 的合体
传输层(L4) = TCP/UDP
网络层(L3) = IP/ICMP/路由
网络接口/链路层(L2+L1)
为了更快速理解这些协议,编写了下面的表格方便速查
如果把网络传输比作送快递,那就比较容易理解这些晦涩的概念了。
L1物理层好比公路和汽车,只负责将比特搬运。这一层都是网络设备网线、光纤、速率/双工、光模块。
L2 数据链路层则是小区大门+门卫和电梯,这一层负责房间号分配,刷门禁、坐电梯到哪层,同楼层用VLAN分区;多部电梯联动是LACP(链路聚合)。我们的交换机和本次网卡绑定就处在这一层,它依靠楼层(VLAN)房间号(MAC地址)进行转发数据帧,而不是街道地址(IP)。数据帧的结构如下:
目的MAC(6B) → 源MAC(6B) → 类型/长度(2B) → 载荷(46–1500B) → FCS校验(4B)
这些内部结构会进一步封装上层信息,比如载荷里就会封装L3中的IP包。
MTU:单帧承载上层数据的最大字节数(以太网常见 1500B;“巨帧”可到 9000)
MSS 是 TCP 分段上限(受 MTU 约束:MSS ≈ MTU − IP/TCP 头)
这里需要注意的是,有些交换机会在L3层,这种交换机增加了路由功能。
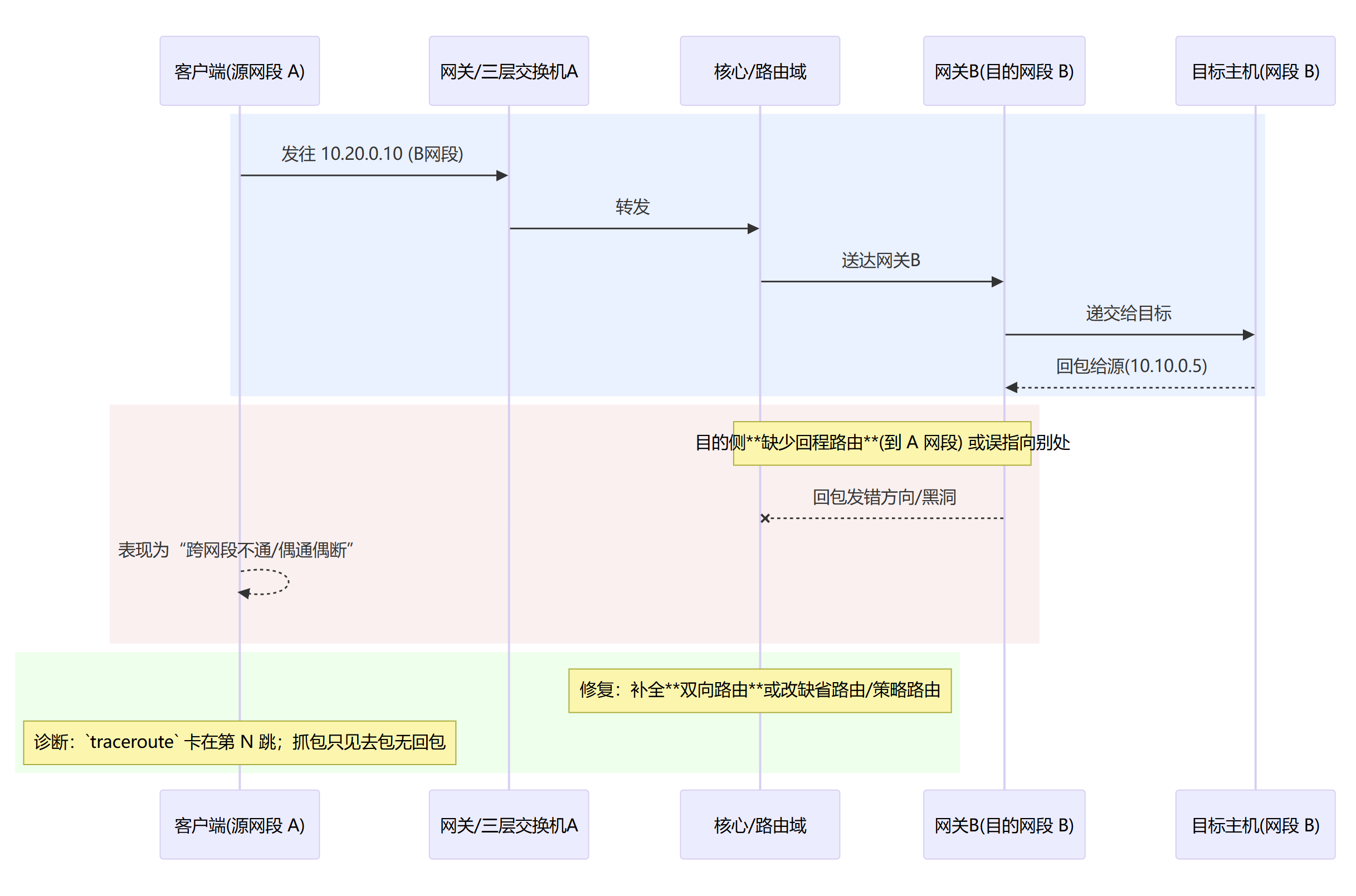
L3 网络层 这层类似城市路网+导航,认街道号(IP),找路线、跨城送;路由器就是导航。导航表错/路被封(路由/ACL)→ 跨城到不了,也就是我们常常用ping命令监测是否网络联通。
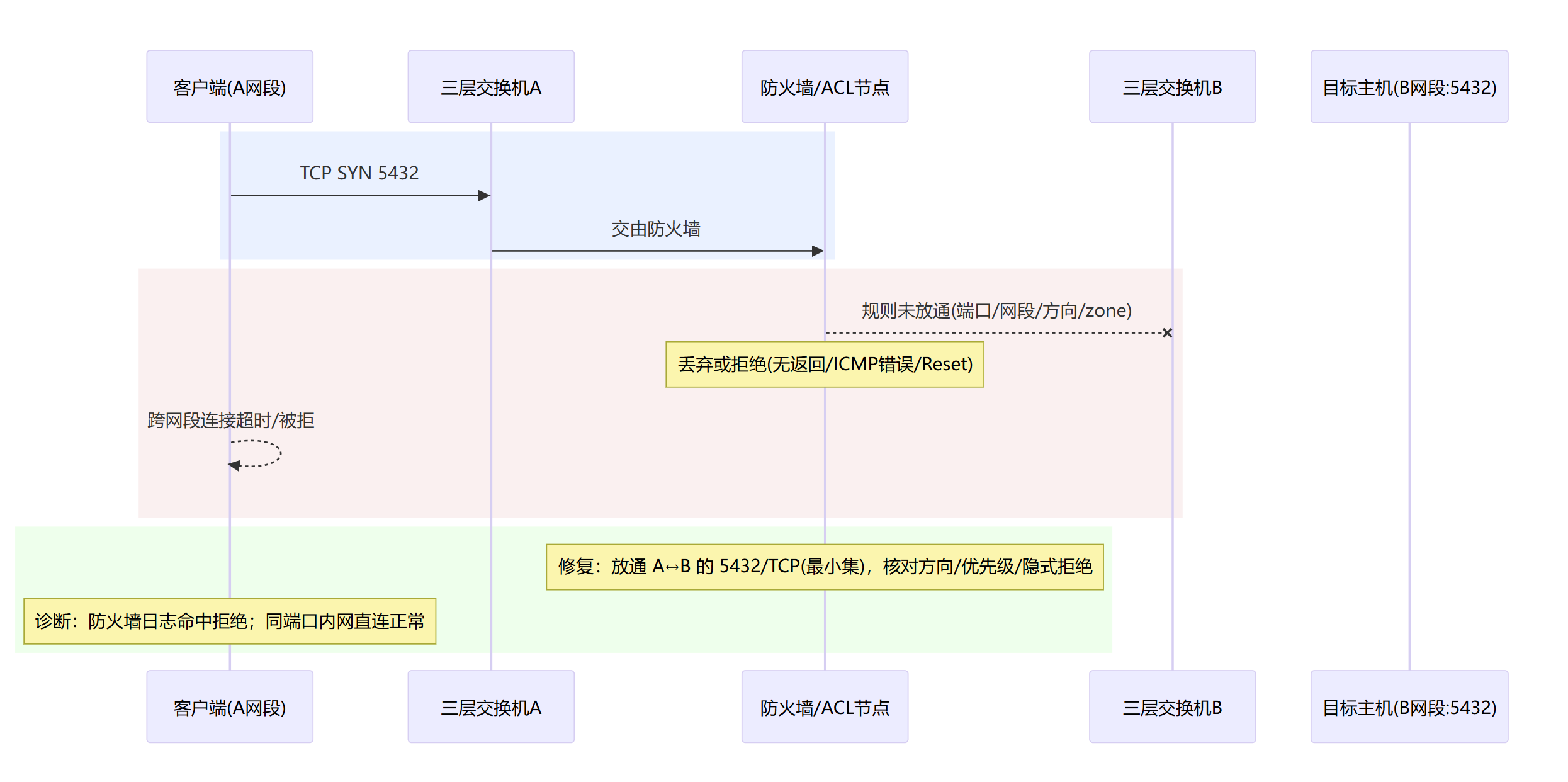
L4 传输层就是 快递箱和运单号,这里有两个重要的协议TCP和UDP,TCP保证不丢不重、按顺序到;而UDP则是快递袋不验签速递(不保证包是否妥投及包的质量)。箱子贴错单/验签失败(端口被拦、握手不成)→ 门口就被退回。
L5 会话层 表示派件员和你开始对话,这一层会建立会话、保持沟通。一般这层在工程上多向上并入L7或向下并入L4。
L6 表示层 这一层开/封保密箱、压缩打包,这一层确保数据传输的安全性,协议有SSL和TLS
L7 应用层 收件人和快递员说“这是给张三的文件”。这一层完全就是业务语义了,协议包括种类繁多,HTTP、DNS、PG/MySQL等等。SQL 登录、认证、协议兼容、pgbouncer 之类的代理都在这层。密码箱打不开/对不上口令(TLS/账户/协议)→ 见到人也无法交付。
总结成一句话就是
车和路(L1)→进小区刷门禁(L2)→城市导航找路(L3)→箱子不丢件(L4)→必要时上锁(L6/TLS)→敲门说暗号交接(L7/PG 协议)。
以postgresql数据库建立网络连接为例,可以概括如下图

交换机相关概念知识
交换机一般被划分在L2,下面介绍相关概念
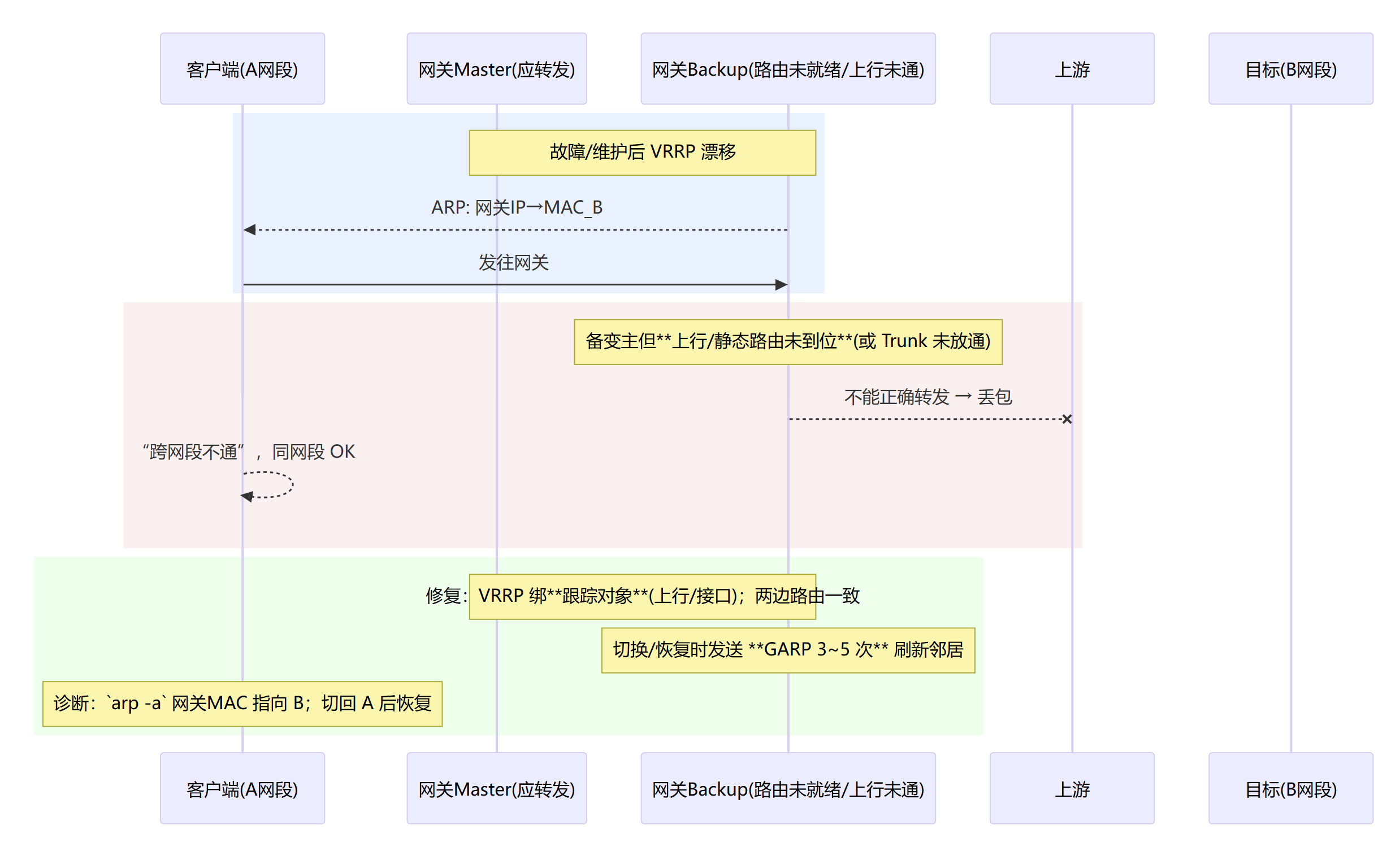
ARP和GARP
ARP:把 IP → MAC。例如主机要给 10.0.0.5 发帧,不知道对方MAC,就先广播“谁是 10.0.0.5?”。
GARP(Gratuitous ARP):主动广播“这个IP现在在我这里”,用于:
VIP 漂移/主备切换时刷新邻居表;
通知交换机/网关更新IP→MAC映射,避免短时黑洞。
VLAN / Trunk / Access
VLAN:把同一台交换机上的端口按“逻辑网段”分组,互相隔离。一栋楼按部门分层;不同 VLAN 彼此隔离。
Access 口:连接终端(服务器/PC),只承载一个 VLAN。
Trunk 口:承载多个 VLAN(用 802.1Q 标签区分),常见在交换机互联/上联。
像“货梯”,同时载多个 VLAN,用 802.1Q 标签标注(Tag);native VLAN 是不上标签的那一个(易错点:两端 native 配不一致会黑洞)。
链路聚合(LAG)
网卡绑定策略要和链路聚合方法适配,因此,本块内容非常重要。
链路聚合的目的在于,多根物理链路组成一个逻辑通道,实现带宽汇聚/冗余且单 MAC/IP对外。其实现方式主要有两类
静态聚合(不跑协议/XOR):双方手工把几个口绑成一组(容易配错/状态不协商)。
LACP(802.3ad):跑标准协议,相互协商,谁可用、怎么均衡都可交互确认,更稳。
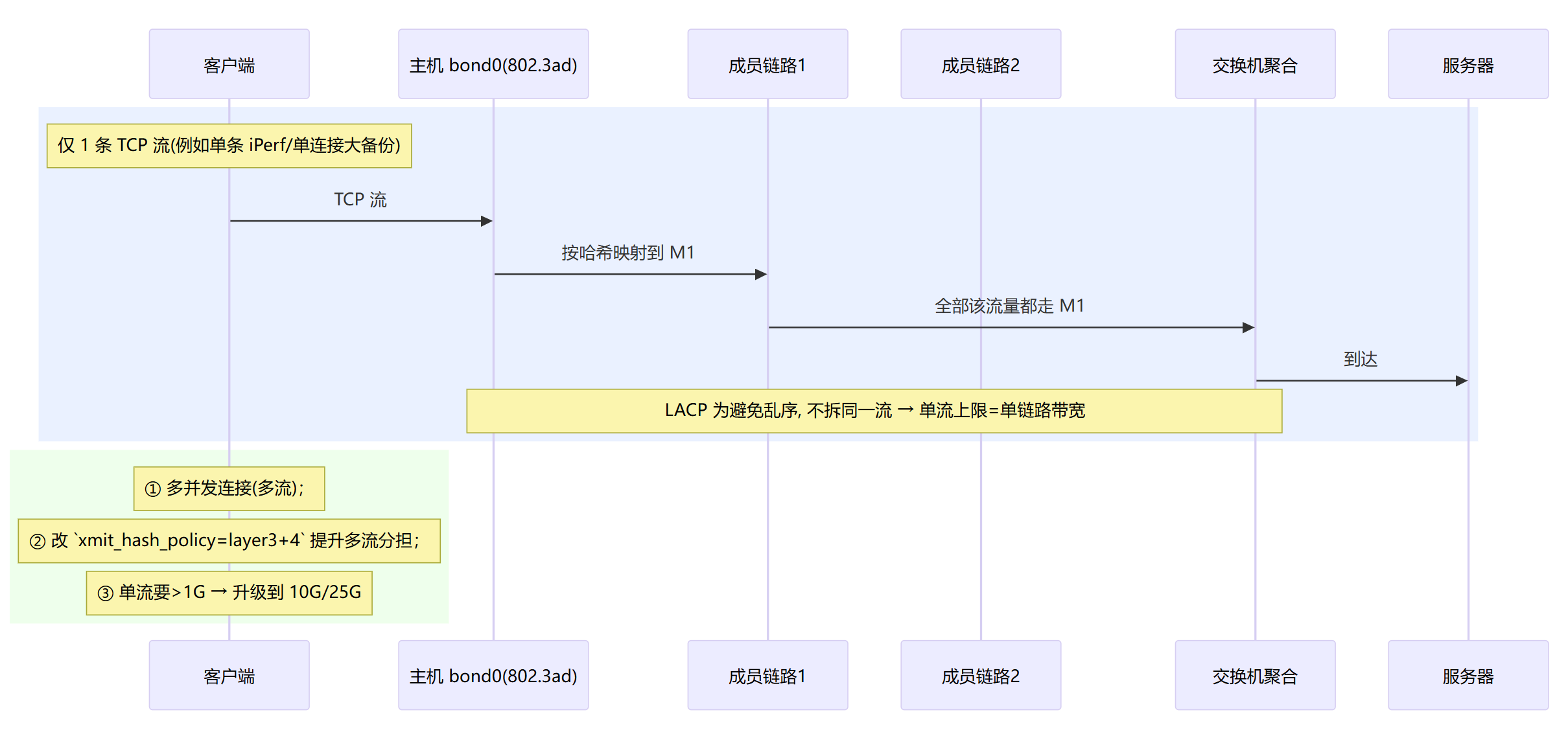
把多条线纳为一条“逻辑大电梯”;协商哪几根可用、故障自动摘除;同一条流按 哈希固定走一根(避免乱序)。
LACP(802.3ad)的一些概念点:
Actor/Partner:本端/对端参与者;
System ID/Key:一组链路身份/策略的统一标识;
Aggregator:协商后一组被收发(collecting/distributing)的成员口;
LACPDU:两端交换的控制报文;
Hash 策略:
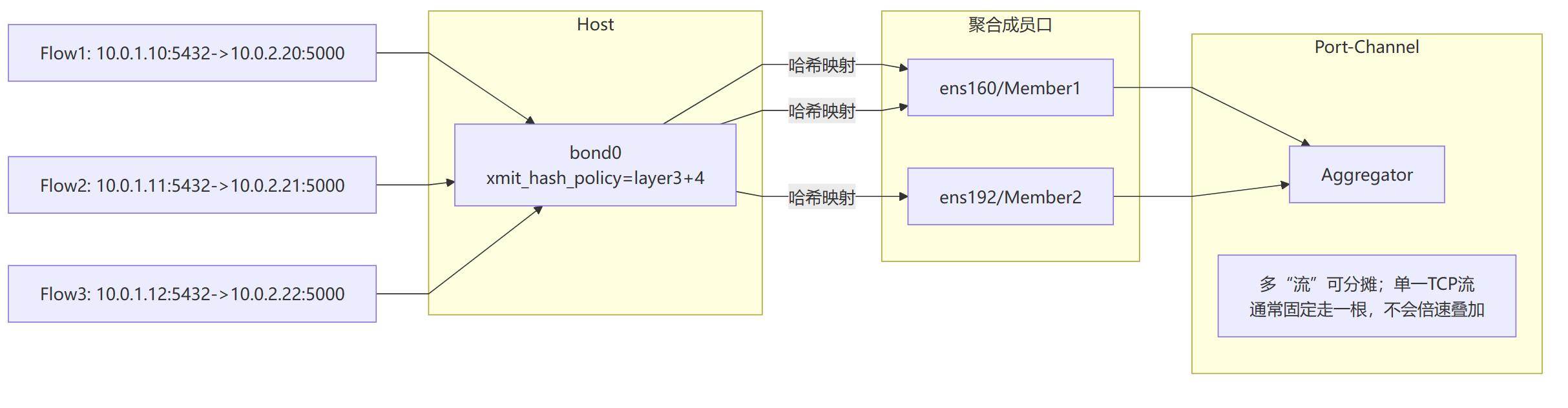
xmit_hash_policy=layer2/layer3+4等,决定某条流走哪根线。
其协商时序图如下:
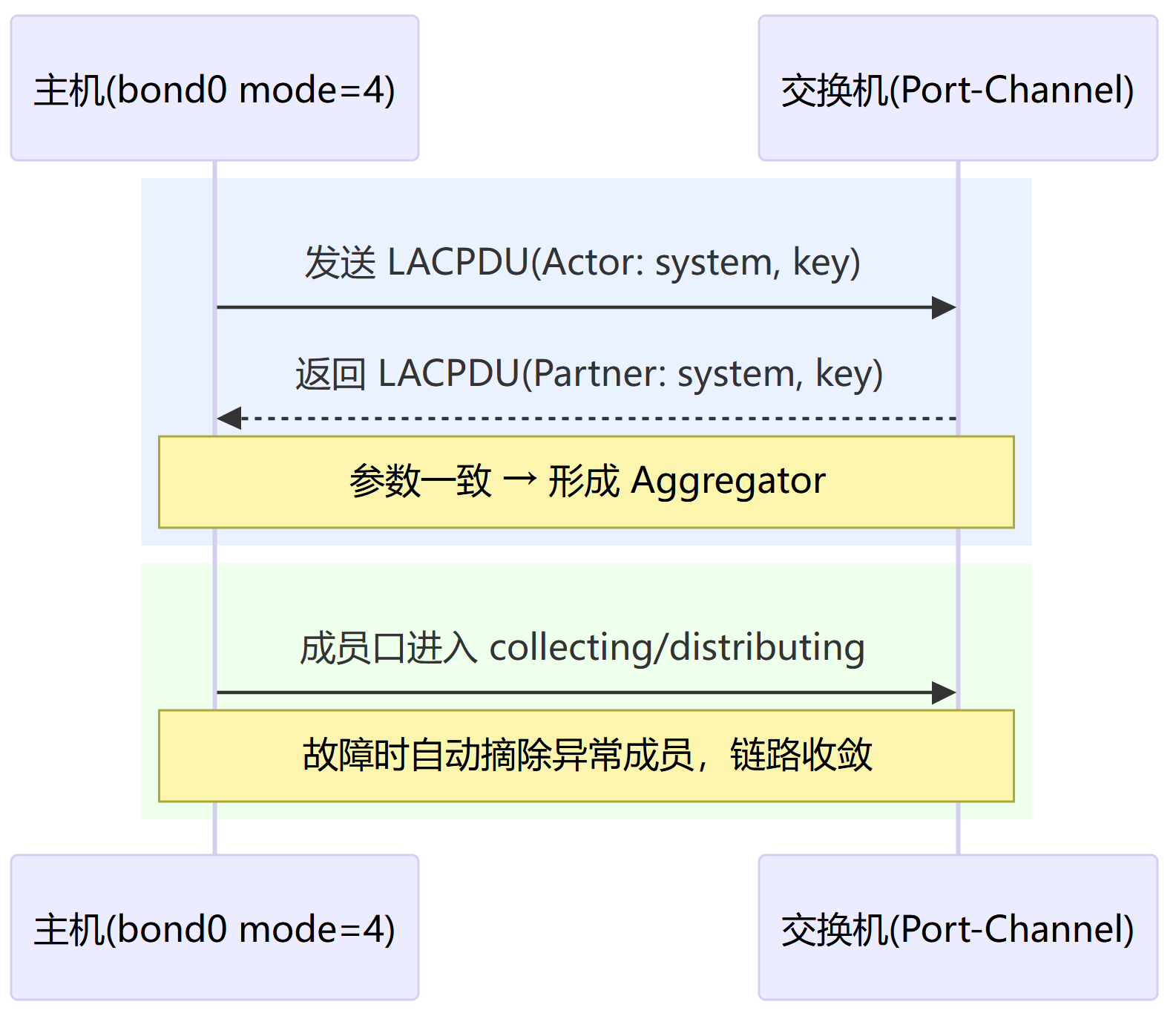
这个图看不懂也没关系下面会详细讨论绑定策略和交换机之间的关系
跨机箱聚合(MLAG / MC-LAG)
MLAG / vPC / IRF / MC-LAG:不同厂家的叫法,本质是把两台交换机协同,对服务器看来像一个聚合设备。其好处在于,单交换机故障不再把整组链路打趴。其前提是两台交换机之间有专用 Peer-Link/ISL 和心跳,并严格配置一致。这种方案有脑裂风险,不同厂商有不同的脑裂保护办法。下面给出一个拓扑示意:

交换机如何工作
了解完交换机的相关概念知识,我们开始讨论交换机是如何工作的。和上面一样,我们依旧以送快递为例说明交换机的工作原理。交换机工作主要分为以下几个部分:
源地址学习(Learn)
门卫看到“谁从哪个门进来”,就把寄件人房号=源MAC记在这扇门=入端口上(写进 MAC/FDB/CAM 表)。把“源MAC → 入端口 + VLAN”写入MAC 地址表。
目的地址查表(Lookup)
快递单上的收件人房号=目的MAC如果在名单里,就只从那扇门送过去。按“目的MAC + VLAN”查。
未知/广播/组播(Flood)
若门卫没见过这个房号(Unknown Unicast),或是广播(大家都得知道),就一层楼到处喊(除来门口之外的所有端口都发)。安红,我想你!!!
有表项 ⇒ 单播转发;无表项/广播 ⇒ 泛洪;组播 ⇒ IGMP Snooping 只转给订阅者。

老化(Aging)
很久没见到某个房号来往,门卫就把它从名单里划掉(典型 300s),避免表爆满/误导路线。超时或端口 down ⇒ 删除表项。
同端口丢弃
收件门口就是寄件来的门,门卫直接丢掉(防自环)。
流程图如下:

两台交换机用多根线直连,很容易形成二层环路:广播/未知单播会绕圈子指数放大(风暴)。为了防止环路产生,一般有如下方案:
STP:选一个根桥(Root Bridge),把冗余链路置于 Blocking/Discarding 状态,消除环路。
RSTP:快速版,秒级收敛。
MSTP:多实例,每个 VLAN 组单独选择路径。
边缘端口(PortFast/Edge):接服务器/PC 的口直接前转;配 BPDU Guard 防止“伪交换机”插进来。
环路与阻断示意
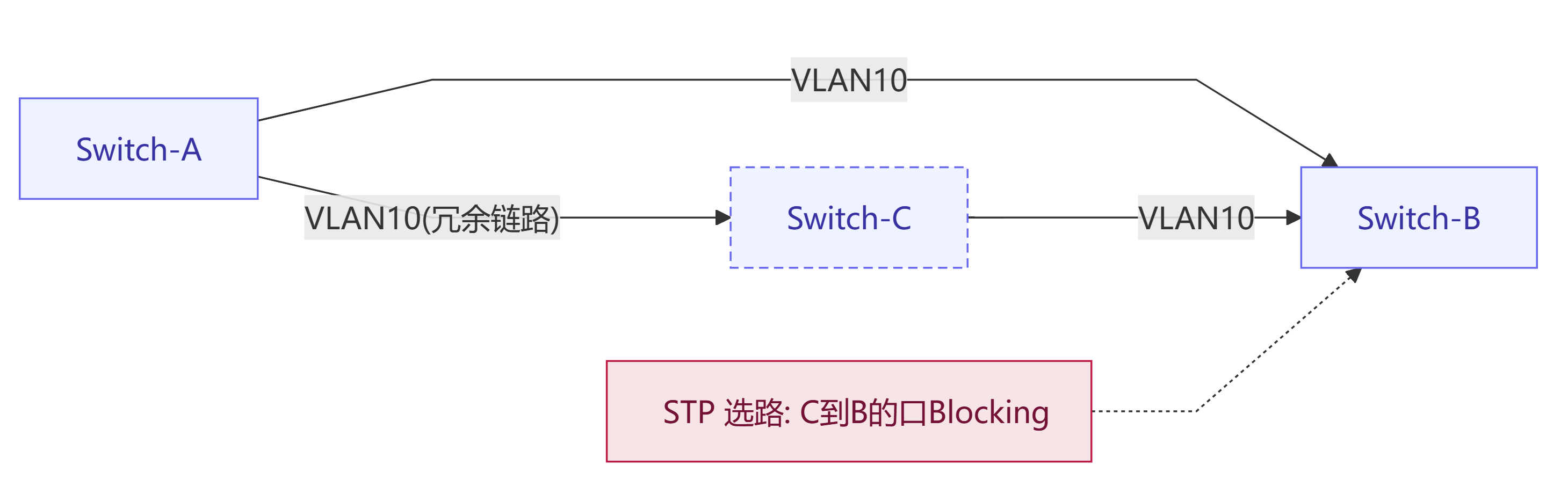
若误关 STP 或把边缘口接到交换机上,极易全网风暴。
网卡绑定
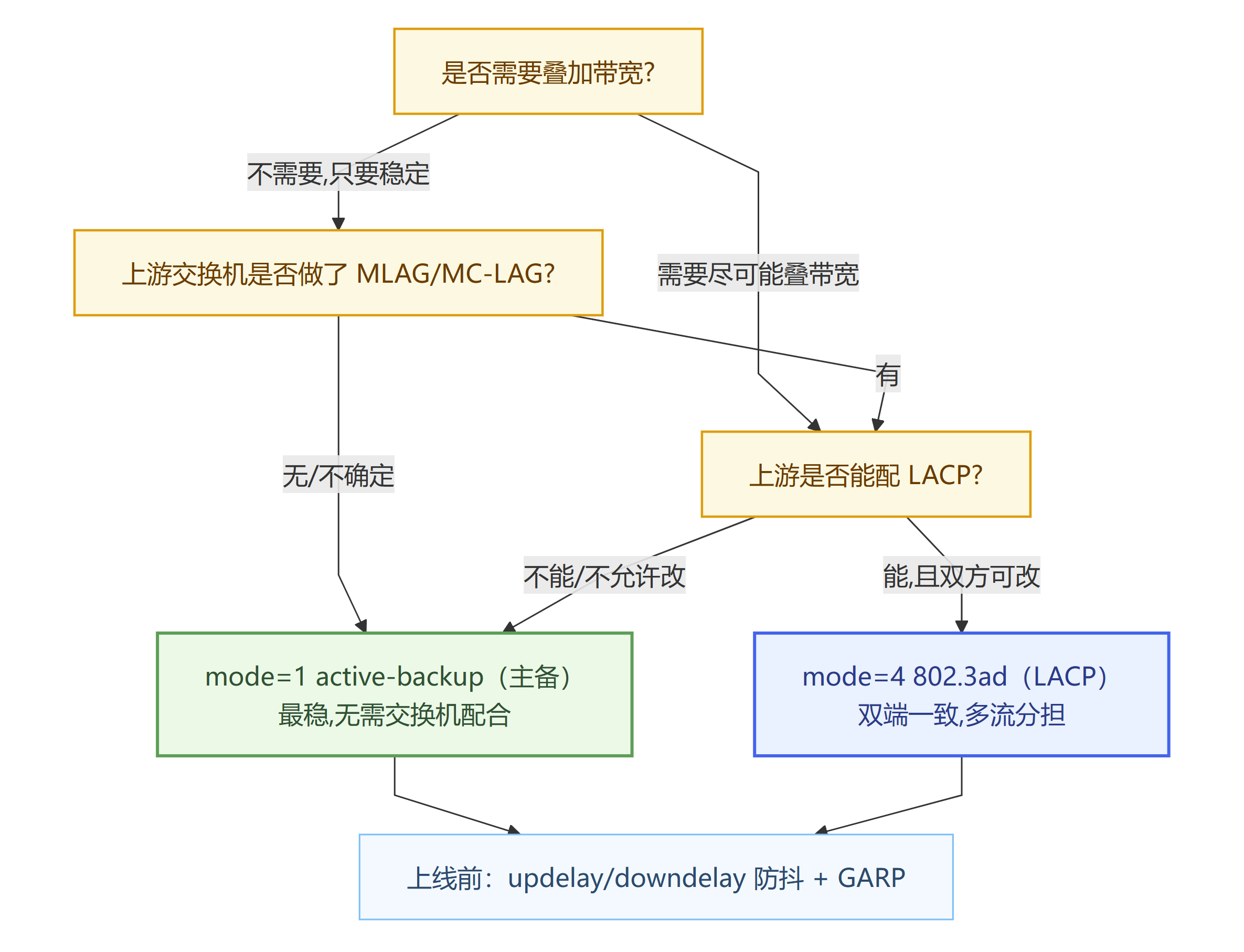
网卡绑定的目的在于把多块物理网卡捆成一个“逻辑网卡”(如 bond0),实现 链路冗余(高可用) 或 带宽聚合(多链路并发)。在运行层面,主机内核做“发包/收包分配与接管”,交换机用 端口聚合/LACP/MLAG 等把多根线当“一根”看(不是所有模式都需要交换机配合)。需要注意的是,冗余最稳的是“一主一备”;要想“多链路叠带宽”,必须两端策略匹配,否则会出现乱序、丢包、MAC 抖动。
网卡绑定模式
轮询
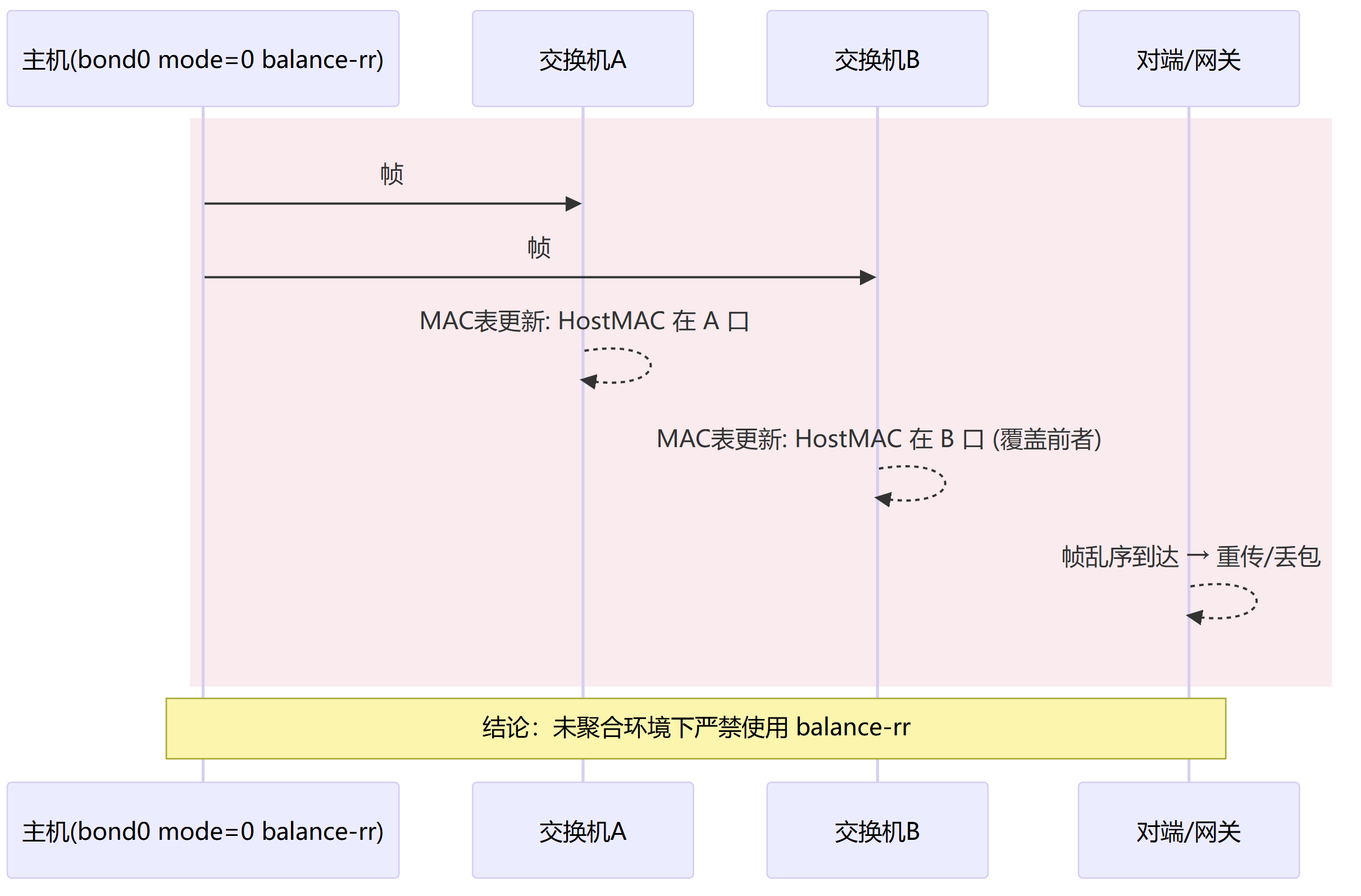
内核名称:balance-rr (mode=0)
轮询(round_robin)模式下,报文按顺序轮流走每根链路,交换机侧需要强依赖对端把多口当“一口”(聚合/MLAG)且同一转发域。这样做的好处是单流也可能叠带宽,相比其带来的有限优点,其缺点非常明显,极易造成乱序和MAC抖动,主机网卡绑定和交换机配置不匹配即掉入大坑。所以这种方法更多的用于实验和特殊场景下的特殊设备上,不推荐生产使用。
轮询触发 MAC 抖动与乱序示意图
主备
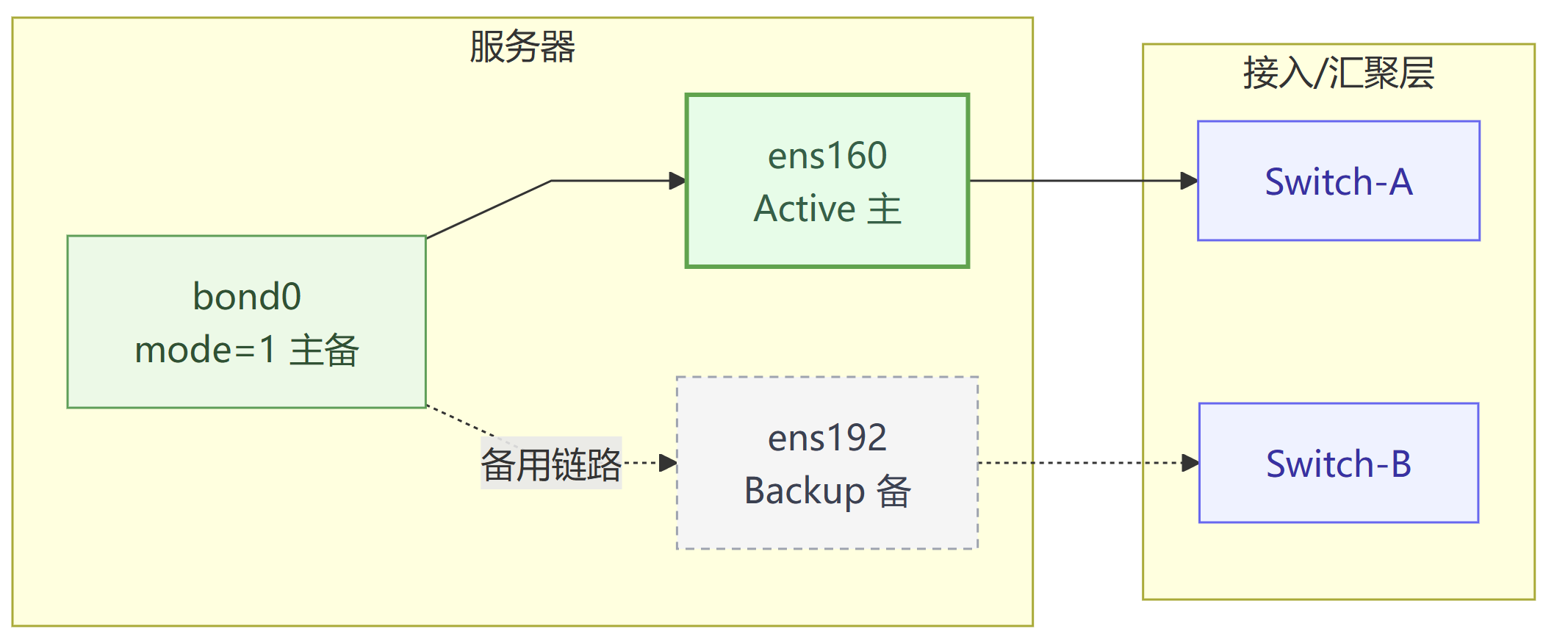
内核名称:active-backup (mode=1)
一主一备,主链路断才切备。在交换机侧 不需要对端聚合;可以接两台交换机。这种模式是稳最通用的模式,常用于服务器高可用,数据库主备等场景。
主备发生故障切换时
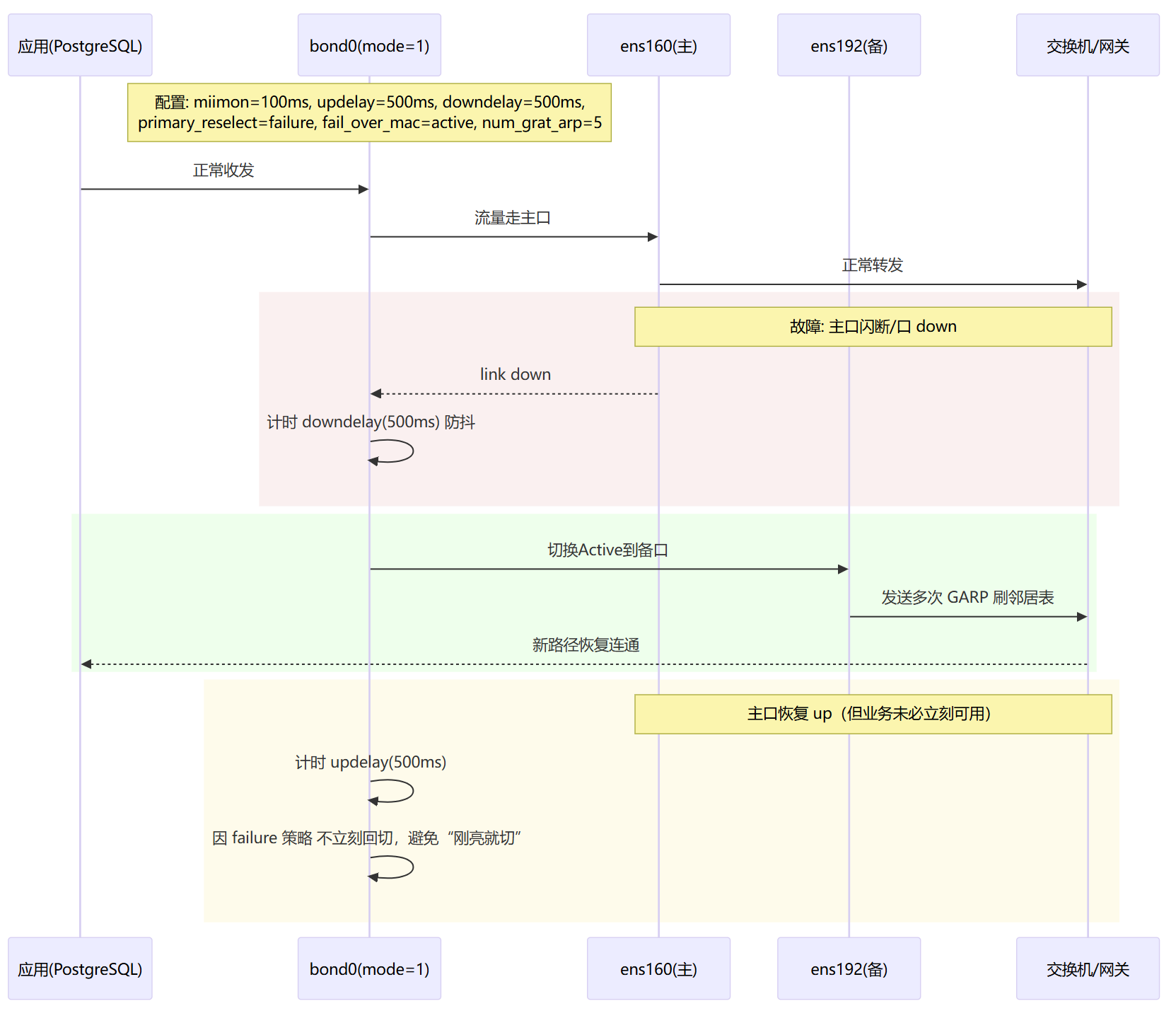
其配置方法如下:
/etc/sysconfig/network-scripts/ifcfg-bond0
融合网卡配置
DEVICE=bond0
TYPE=Bond
BONDING_MASTER=yes
BOOTPROTO=none
ONBOOT=yes
IPADDR=
PREFIX=24
GATEWAY=122.51.51.1
# 可选:VIP
IPADDR1=122.51.51.71
PREFIX1=24
BONDING_OPTS="mode=active-backup miimon=100 updelay=500 downdelay=500 \
primary_reselect=failure fail_over_mac=active num_grat_arp=5"从接口,两张物理网卡配置
# ifcfg-enp100s0f0
DEVICE=enp100s0f0
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
# ifcfg-enp100s0f1
DEVICE=enp100s0f1
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes若链路物理 Up 但“网关暂不可达”时易黑洞,可改为 ARP 监控(替换 miimon):
BONDING_OPTS="mode=active-backup arp_interval=500 arp_ip_target=122.51.51.1 arp_validate=all updelay=500 downdelay=500 primary_reselect=failure fail_over_mac=active num_grat_arp=5"
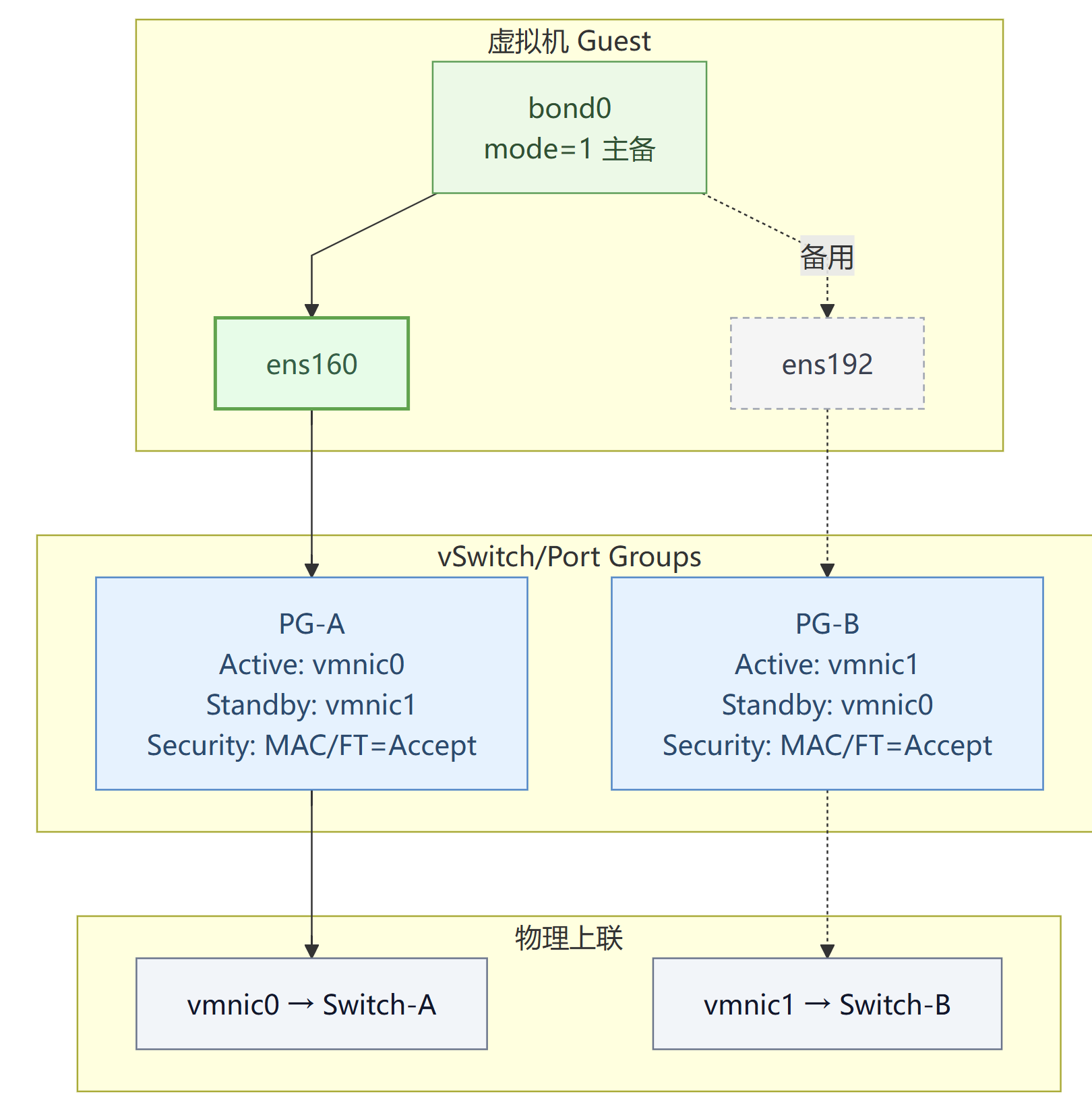
这里附带一个虚拟机的主备网卡绑定模式示意图,但是不过多讨论,有兴趣的可以自行探索。
XOR
内核名称:balance-xor (mode=2)
和mode0的轮询不同,这种负载均衡采用了哈希方式进行,按哈希(MAC/IP/端口)选一根链路。交换机测通常需要静态聚合,也就是需要手动配置,有的设备裸跑也勉强可用。优点就是多流可分摊,缺点是单流不叠加带宽,而且由于手动配置,如果配置不当容易出现抖动。常见的场景是老旧设备的轻聚合,同样不推荐生产使用。
广播
内核名称:broadcast (mode=3)
这种模式会将同包发到所有链路,交换机侧则无任何要求,好处当然是容错性极强,但是缺点也非常明显,就是带宽太浪费了。一般是非常非常特殊的工业场景使用。所以也不推荐这种模式。
802.3ad
内核名称:802.3ad (mode=4)
这种模式是标准的LACP 聚合,要求交换机侧必须启用 LACP(聚合/MLAG)。
优点是多流负载均衡、自动协商,行业标准。缺点是需要双端配合以及单流不一定叠满。多用于数据中心的常规聚合场景。这个模式也是推荐的,好处多多。
LACP协商时序图

LACP流量哈希分担示意
融合网卡配置
/etc/sysconfig/network-scripts/ifcfg-bond0
DEVICE=bond0
TYPE=Bond
BONDING_MASTER=yes
BOOTPROTO=none
ONBOOT=yes
IPADDR=122.51.51.69
PREFIX=24
GATEWAY=122.51.51.1
BONDING_OPTS="mode=802.3ad miimon=100 \
lacp_rate=fast xmit_hash_policy=layer3+4 ad_select=stable \
updelay=500 downdelay=500"从接口
# ifcfg-enp100s0f0
DEVICE=enp100s0f0
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
# ifcfg-enp100s0f1
DEVICE=enp100s0f1
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes交换机侧需把两口聚到同一聚合(Cisco: Port-Channel/vPC;H3C: Bridge-Aggregation/IRF;Huawei: Eth-Trunk/MC-LAG)。
自适应
内核名称:balance-tlb/balance-alb (mode=5/6)
这种模式下,TLB (Transmit Load Balancing,发送方向负载均衡,mode5)仅出方向均衡;ALB(Adaptive Load Balancing自适应负载均衡,mode6) 额外做接收均衡。
在上游交换机不允许你改(做不了 LACP/聚合),但你又想提升出站吞吐(TLB)或同网段内多客户端的入站吞吐(ALB)的场景下可以考虑使用。比如实验环境,临时扩容等场景。
同样,这两种模式也不推荐用于数据库集群的绑定模式。
网卡绑定选择什么样的模式,参考以下网卡绑定模式决策树
网卡绑定重要参数
融合网卡的绑定中的BONDING_OPTS项进行各种参数的配置,下面对参数进行逐一解析:
1. 选型相关
mode
作用:选择绑定策略。
取值:
balance-rr(0) 轮询(高风险乱序,不建议生产)active-backup(1) 主备(最稳,推荐默认)balance-xor(2) 静态哈希(通常需对端静态聚合)broadcast(3) 广播(极少用)802.3ad(4) LACP 聚合(双端一致才用)balance-tlb(5) TLB:仅出站均衡(无需改交换机)balance-alb(6) ALB:出站 + 同网段入站均衡(无需改交换机)
推荐:生产优先
active-backup;能和网管配好聚合再用802.3ad;rr/xor慎用。
xmit_hash_policy(仅 xor/802.3ad 有效)
作用:多流如何分摊到各链路(避免乱序)。
取值:
layer2/layer2+3/layer3+4(有些内核还支持encap2+3/encap3+4)。默认:
layer2。建议:一般用
layer3+4(基于 IP/端口,分担更均匀)。
lacp_rate(仅 802.3ad)
作用:LACPDU 发送频率。
取值:
slow(30s) /fast(1s)。建议:
fast(更快感知链路变化)。
ad_select(仅 802.3ad)
作用:当有多个 Aggregator 候选时如何选。
取值:
stable(默认,最稳) /bandwidth/count。建议:保留
stable,除非网管要求别的策略。
min_links(802.3ad/xor 可用)
作用:至少有 N 根成员口 up 才把 bond 视为 up。
场景:要求“2 根都好才提供服务”的严谨需求。
示例:
min_links=2。
2. 链路防抖动相关
MII/ethtool 物理探测 与 ARP 业务探测 互斥,选一种即可。
物理探测
miimon
作用:物理层探测(毫秒)。0=关闭。
常用:
miimon=100(100ms)。优点:简单、通用。缺点:物理 up≠业务可达。
updelay / downdelay
作用:防抖——链路 up/down 后延时启/停(单位=毫秒,实际以
miimon周期计)。常用:
updelay=500 downdelay=500。意义:避免“刚亮就切”造成黑洞(你之前踩的坑)。
use_carrier
作用:
1用netif_carrier_ok(默认),0用旧 MII。默认:
1。一般不改。
ARP业务探测
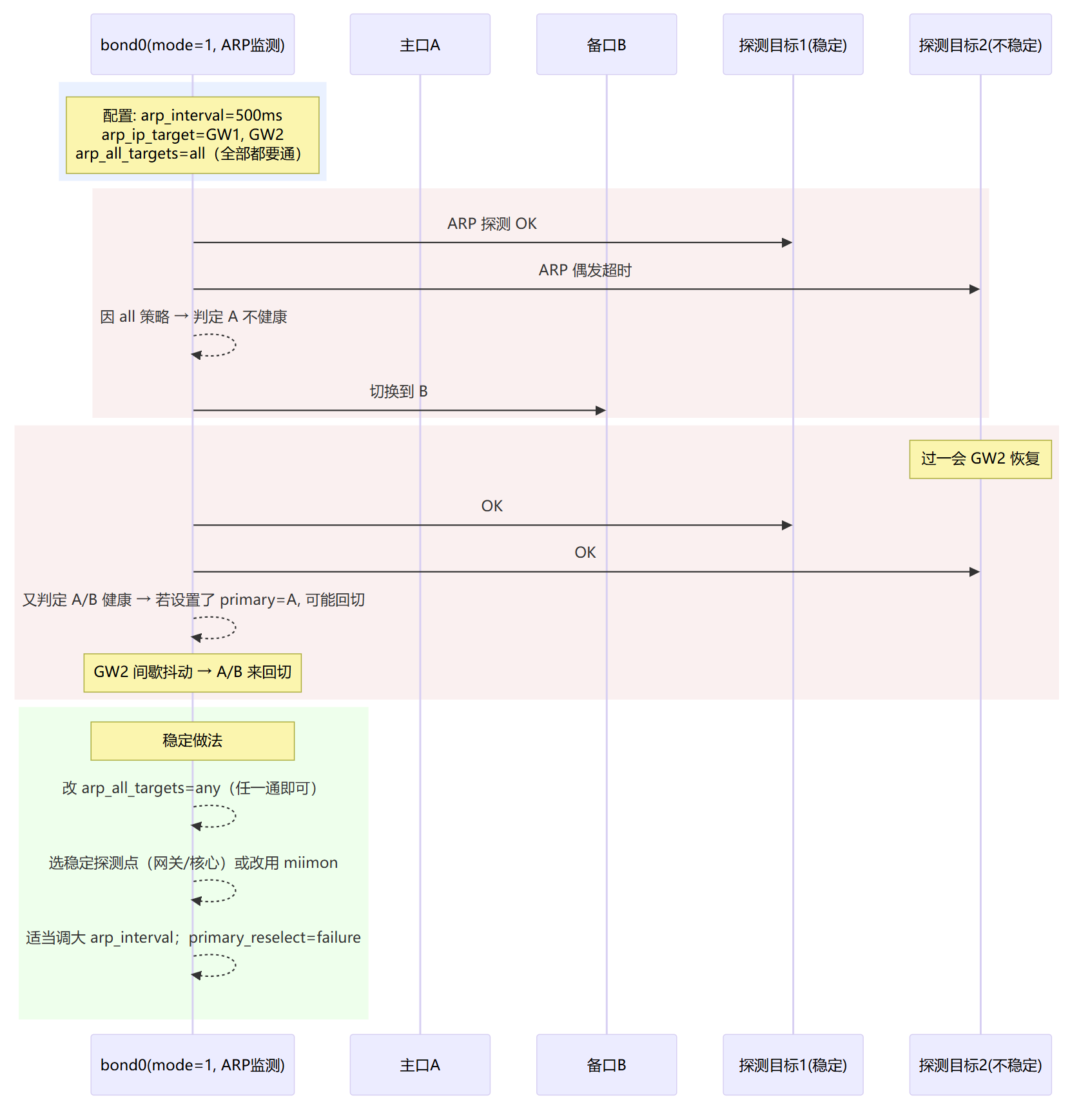
arp_interval / arp_ip_target
作用:业务层探测(ARP 心跳)。
arp_interval=毫秒;目标最多 16 个。示例:
arp_interval=500 arp_ip_target=122.51.51.1,122.51.51.2。优点:能识别“物理 up 但转发表/ACL 未就绪”。
缺点:仅对同二层广播域的目标有效;需要稳定的网关/探测点。
arp_all_targets
作用:多个目标时,bond 判定可用的逻辑。
取值:
any(任一可达即认为 up,默认)/all(全部都得通)。建议:默认
any,除非你非常确定所有目标都可靠。
arp_validate
作用:对谁做有效性验证。
取值:
none(默认)/active/backup/all。建议:主备模式可用
all(更严谨),但要保证探测目标稳定。
3. 主口,回切,MAC行为相关
primary
作用:指定首选主口(如
primary=enp173s0f0)。适用:
active-backup(也影响 TLB/ALB 的“活动口”)。
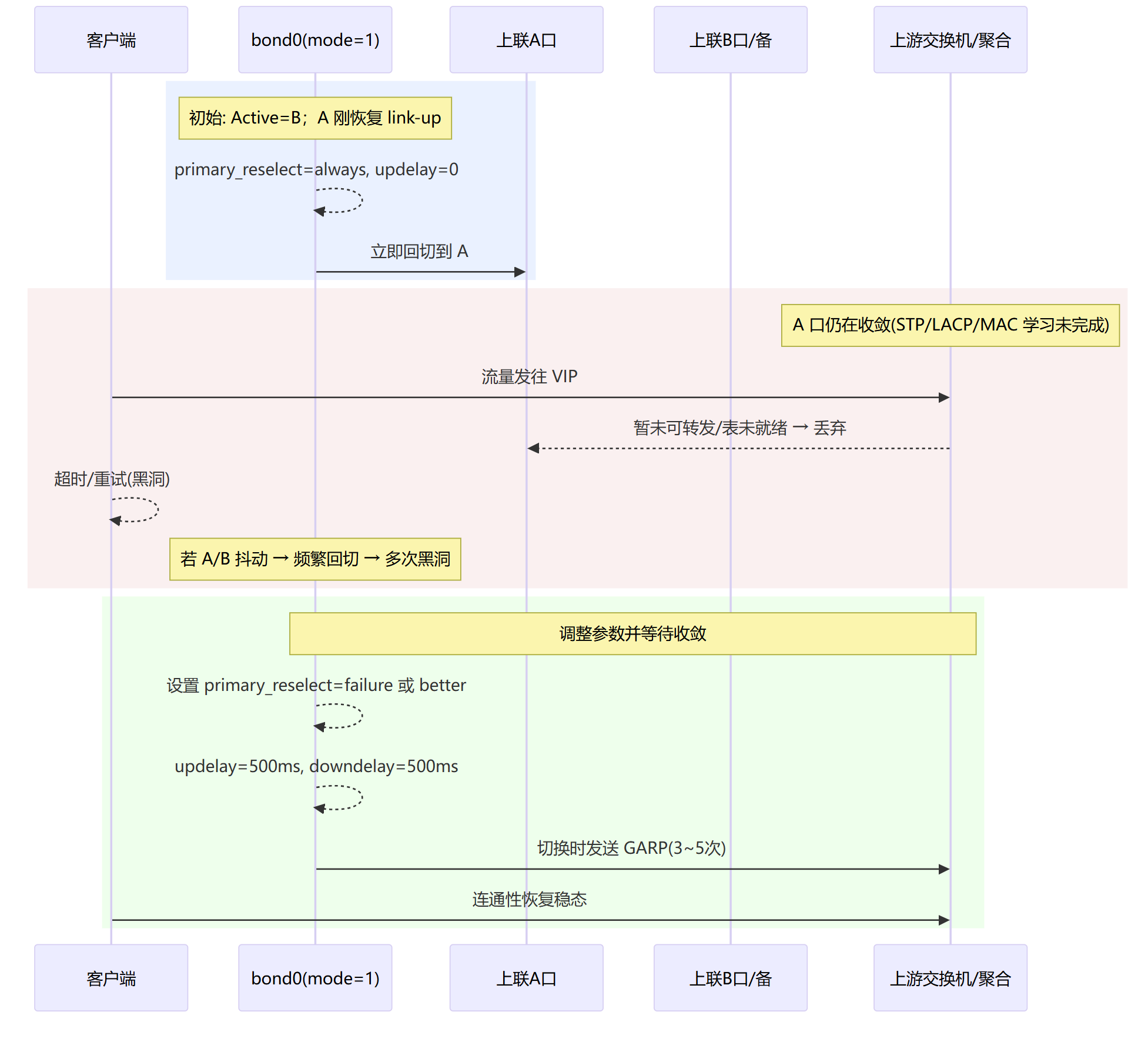
primary_reselect
作用:主口恢复后是否/何时回切。
取值:
always:一亮就回切(易抖,不建议)better:只有更“好”(速率/双工)才回切failure:仅当前口失败才回切(推荐)
结合:配
updelay/downdelay一起用,效果更稳。
fail_over_mac
作用:故障切换时 bond MAC 的策略。
取值:
none(默认):bond 使用固定 MAC(通常为第一块从口的 MAC),切换时把该 MAC 写到新主口上;对上游看起来“同一 MAC 在不同端口移动”。active:bond MAC 跟随活动口(每次切换 MAC 都会变);适合一些端口安全环境或虚拟化里不想“同 MAC 跨端口移动”。follow:每个从口保持各自 MAC,bond 的 MAC 始终等于当前活动口的 MAC(与active类似,区别在从口的本机 MAC 管理方式)。
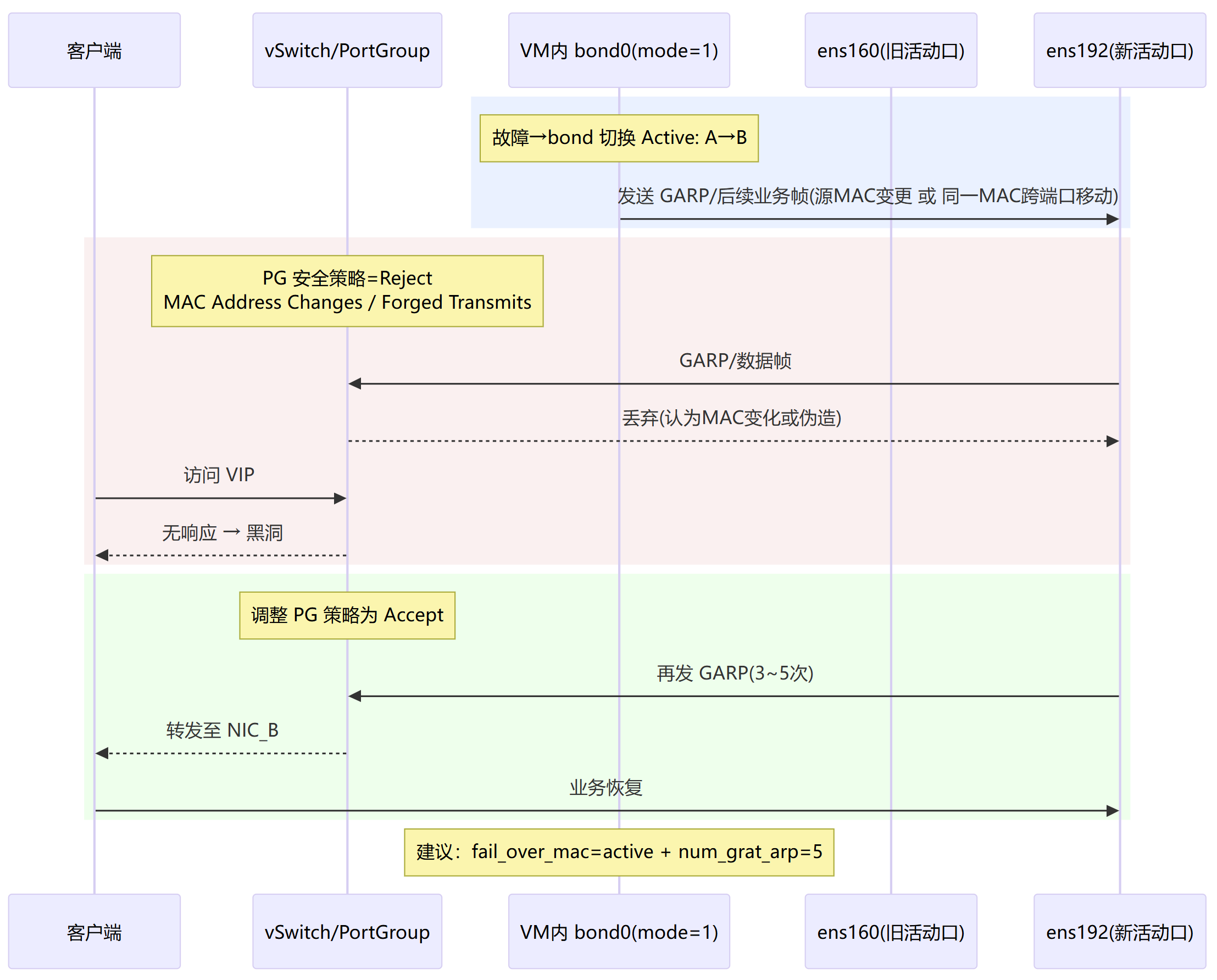
建议:物理机/常规交换机环境默认
none;虚拟化/端口安全多用active,并确保发送 GARP。
4. 切换时的邻居刷新
num_grat_arp
作用:主备切换/从口变更时发送的 Gratuitous ARP 数量。
常用:
3~5。意义:快速刷新对端 ARP/MAC 表,减少黑洞。
num_unsol_na(IPv6)
作用:发送 Unsolicited NA(邻居广告)次数,作用同上。
常用:
3~5。
resend_igmp
作用:失效转移后重发 IGMP Join 的次数(多播/组播环境)。
场景:数据库/应用组播订阅,故障切换后尽快恢复多播流。
推荐参数
主备(最稳) —— 物理探测版
BONDING_OPTS="mode=active-backup miimon=100 updelay=500 downdelay=500 \
primary_reselect=failure fail_over_mac=active num_grat_arp=5 num_unsol_na=5"主备(更“业务感知”) —— ARP 探测版
BONDING_OPTS="mode=active-backup arp_interval=500 arp_ip_target=122.51.51.1,122.51.51.2 \
arp_all_targets=any arp_validate=all updelay=500 downdelay=500 \
primary_reselect=failure fail_over_mac=active num_grat_arp=5 num_unsol_na=5"LACP 聚合
BONDING_OPTS="mode=802.3ad miimon=100 lacp_rate=fast xmit_hash_policy=layer3+4 \
ad_select=stable updelay=500 downdelay=500 min_links=2"TLB
BONDING_OPTS="mode=balance-tlb miimon=100 updelay=500 downdelay=500 tlb_dynamic_lb=1"ALB
BONDING_OPTS="mode=balance-alb miimon=100 updelay=500 downdelay=500"
# 注:IPv6入站均衡有限;虚拟化需允许 MAC 变化/伪造发出网卡绑定异常及处理
常见的异常情况
间歇丢包 / 抖动
ping/mtr 有丢,RTT 波动大。
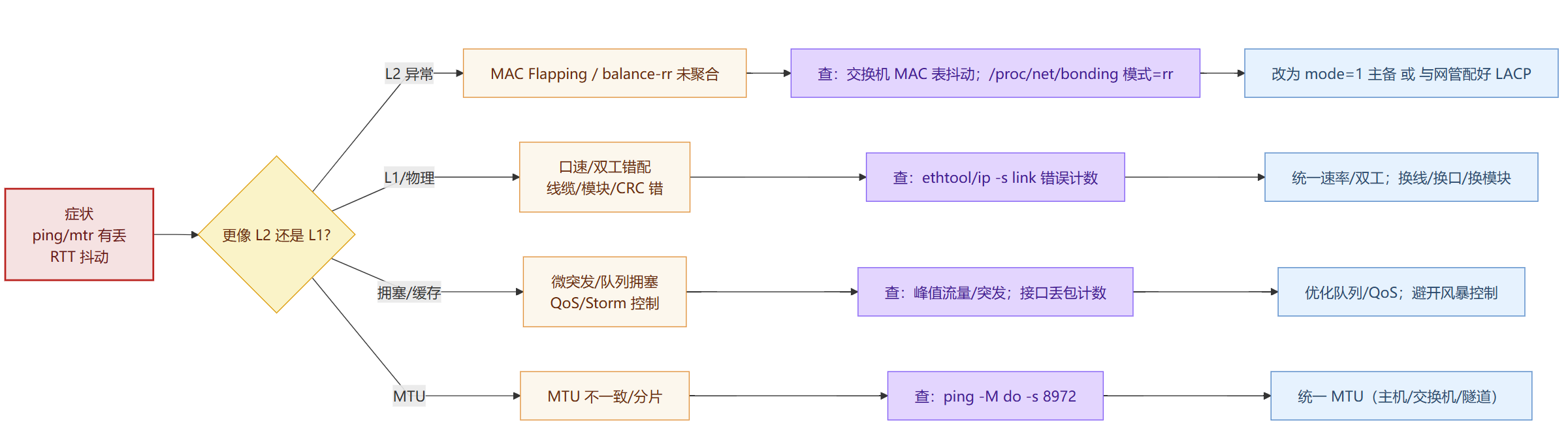
L2:MAC 抖动(balance-rr 未聚合导致乱序/丢包)
乱序→重传→ping/mtr 抖动且偶有丢。
改 mode=1 主备,或双端正确上 LACP (mode=4)。
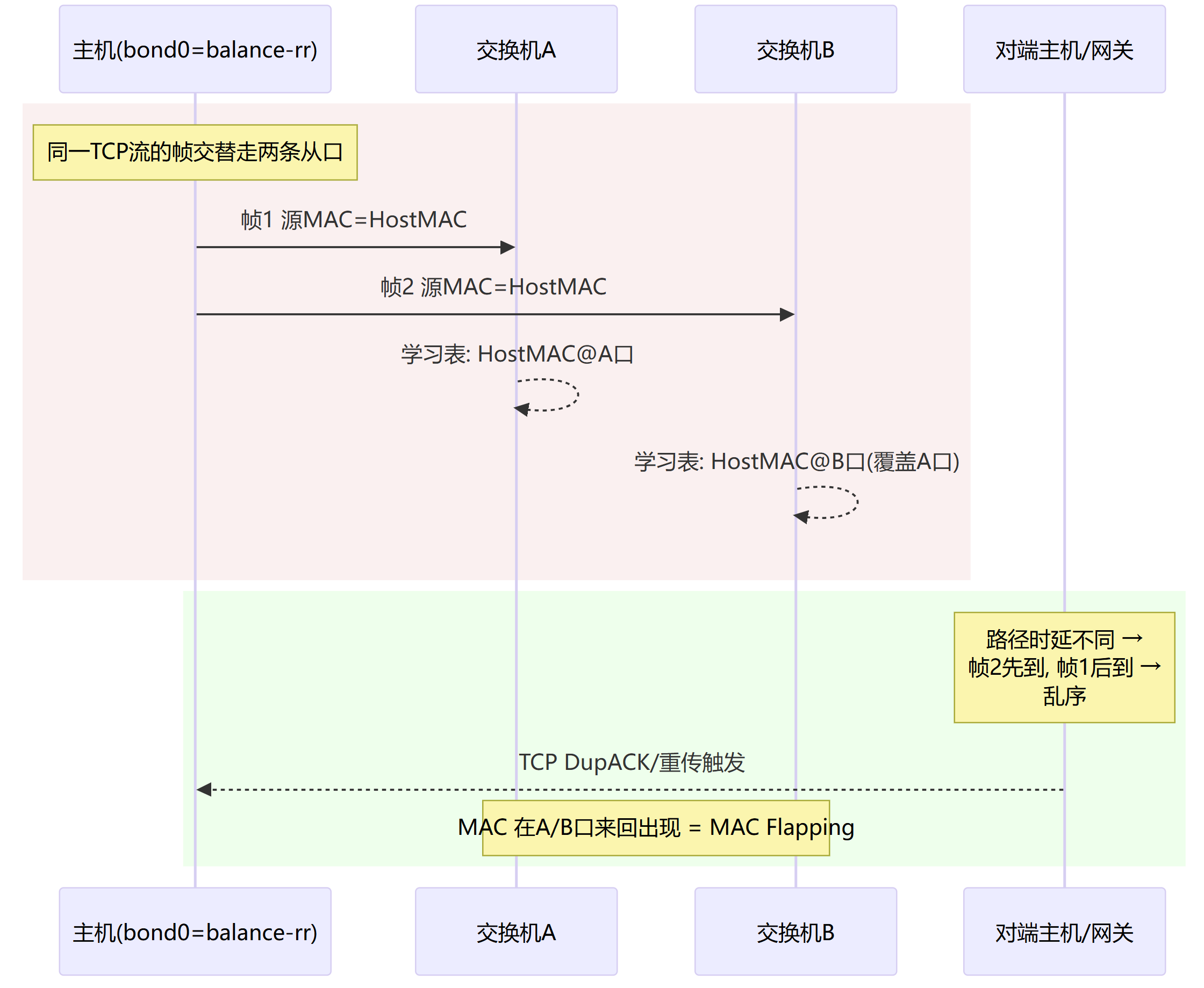
L1:速率/双工错配或物理介质问题(CRC 错/丢)
链路不掉线但有错包→重传→时延抖动。
两端速率/双工统一(都自协商或都固定)、换线/换模块/换口。
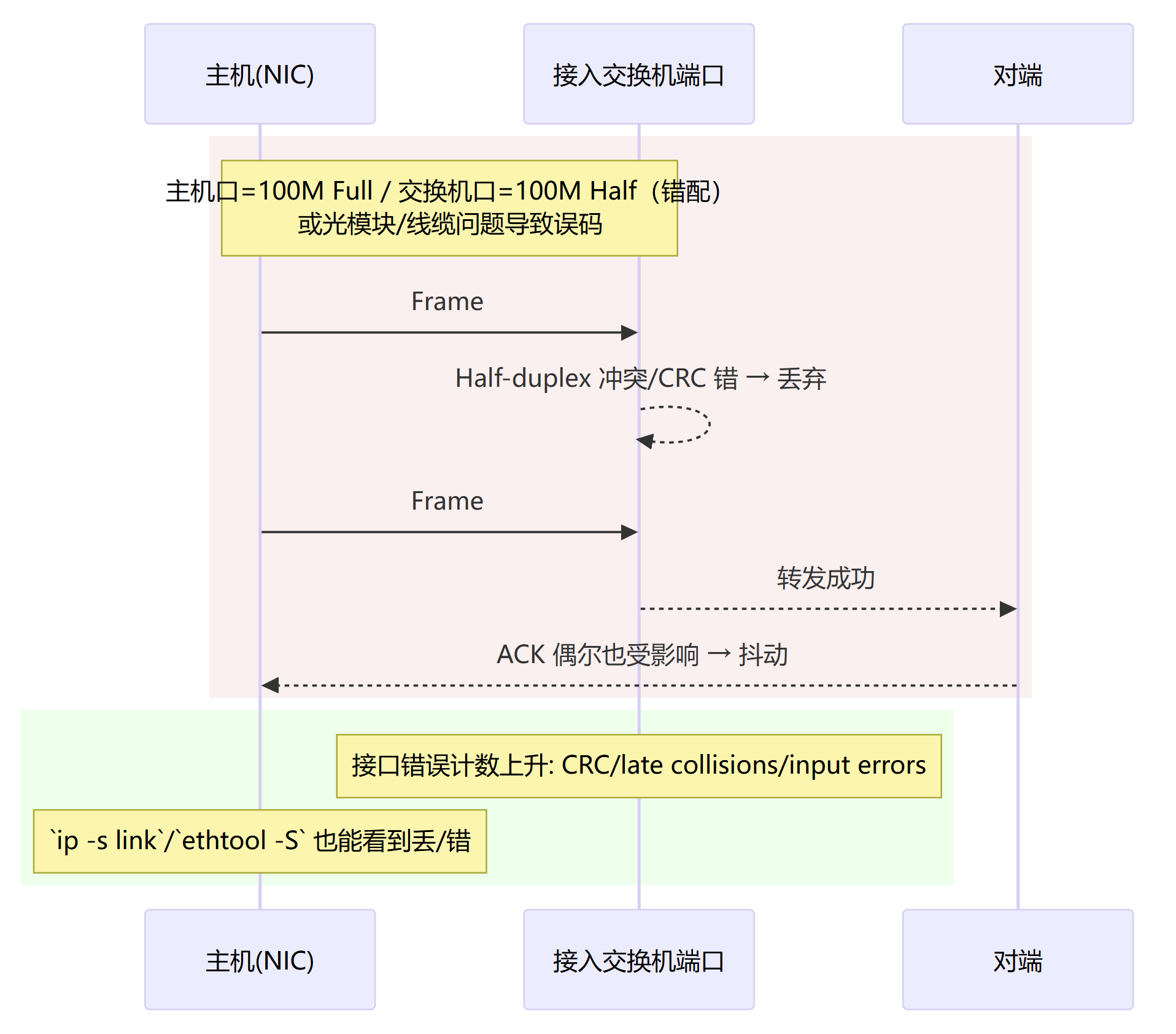
拥塞/微突发与队列丢包(Tail-Drop / 限速)
排队延迟+尾丢 → 抖动/丢包。
错峰/限速突发、增大上联/队列、与网管调 QoS(优先级/缓冲),应用侧多流并行但控制峰值。
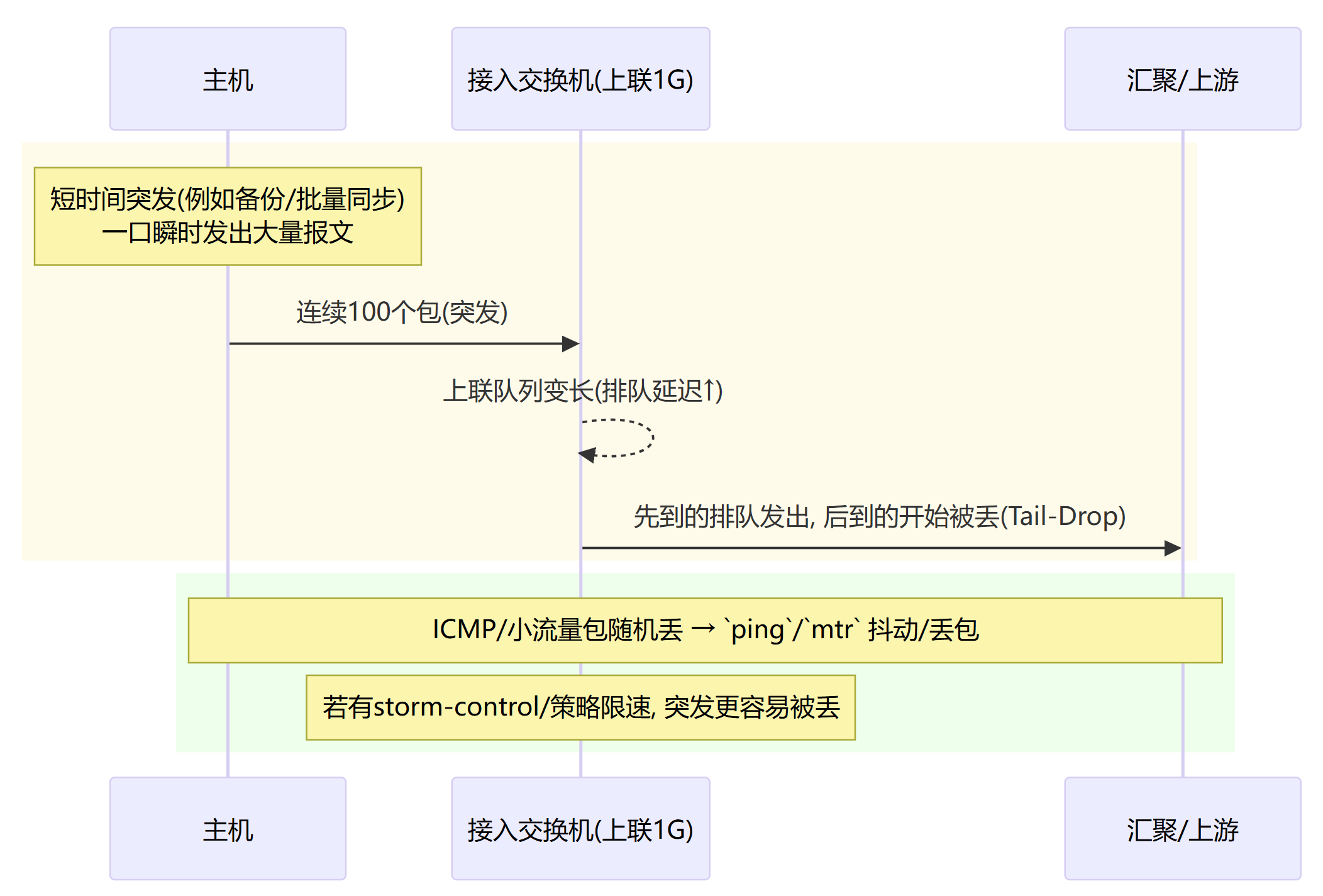
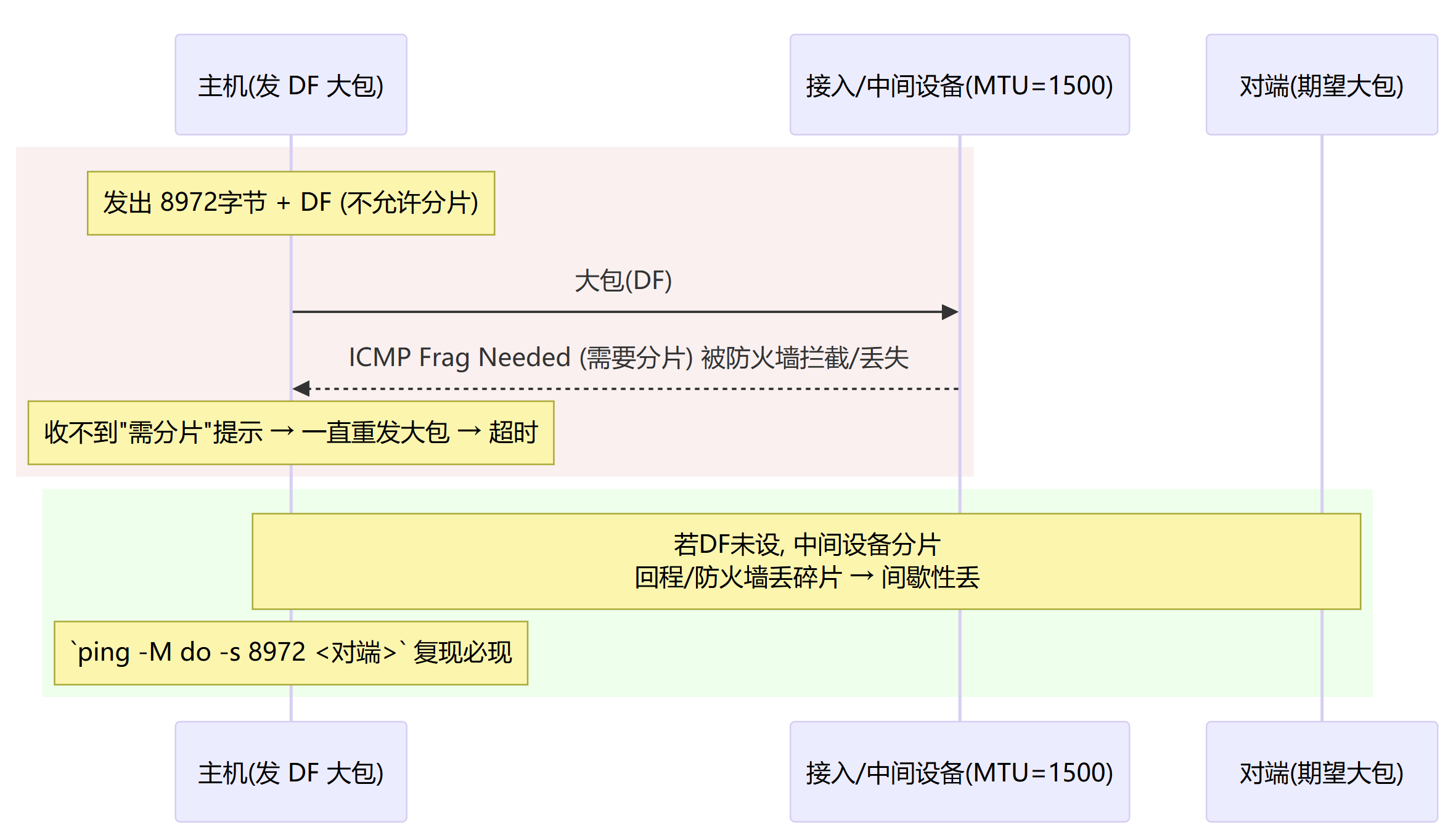
MTU 不一致 / 分片黑洞(大包必丢或间歇丢)
路径某段 MTU 小于端到端预期 → 大包被拒或碎片丢。
统一 MTU(主机/交换机/隧道),或关闭 DF/调 MSS(例如 iptables mangle --set-mss),放通 ICMP Frag Needed。
切换黑洞
主备切换 1–3s 不通。

未发送/被拦截 GARP(邻居仍指向旧MAC → 黑洞)
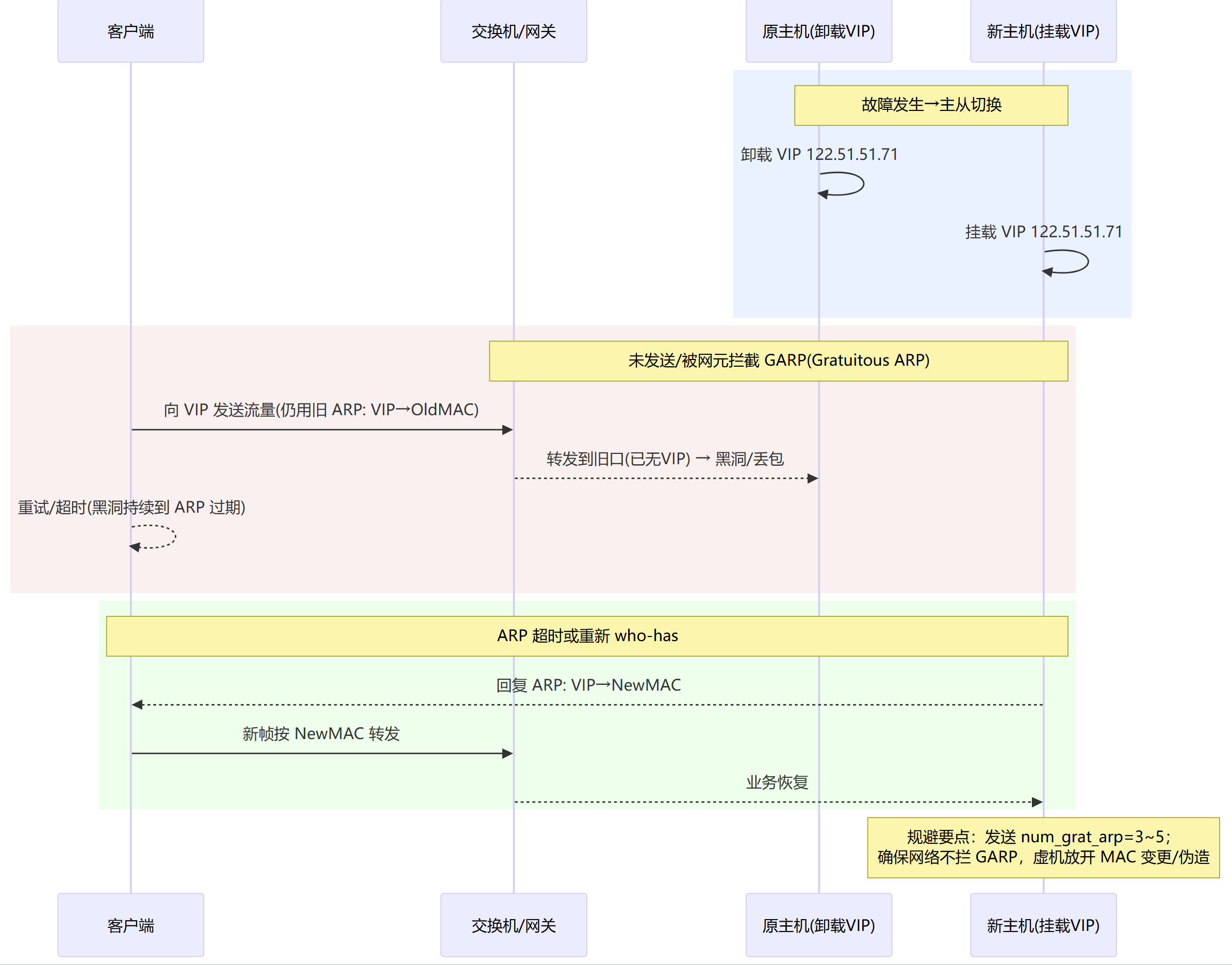
虚拟化 PG 安全策略拦截(MAC 变化/伪造被拒 → 黑洞)
回切太激进/未给收敛时间(“刚亮就切” → 黑洞)
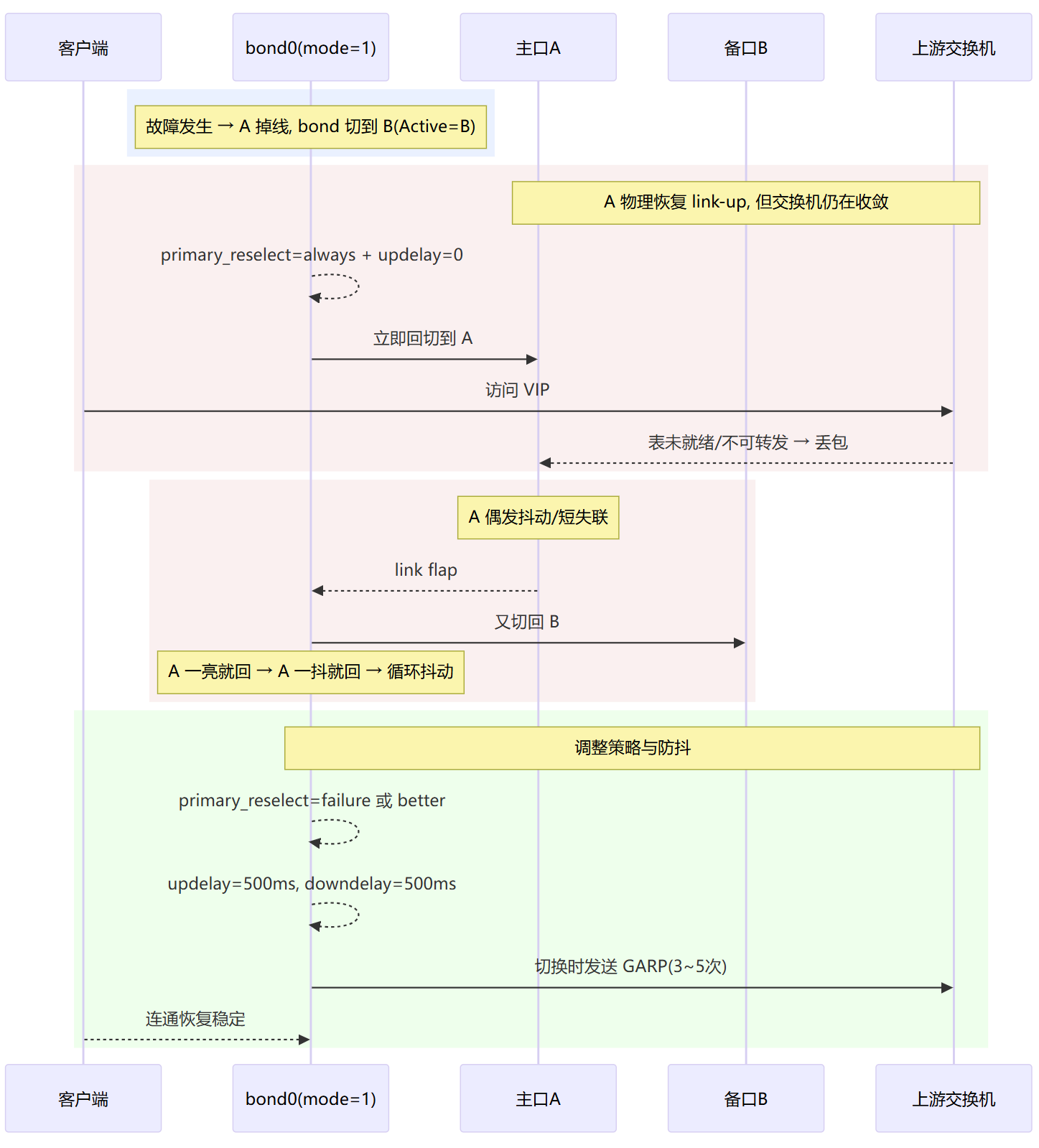
回切频繁
Active Slave 来回跳,有丢包异常。
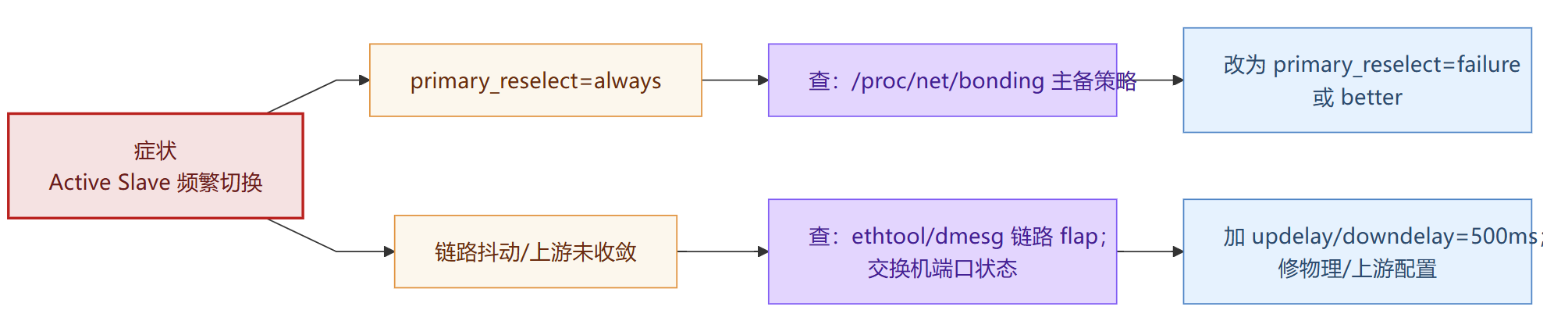
策略过激:primary_reselect=always + updelay=0(刚亮就切 → 抖动)
物理链路不稳:口速/双工/模块/光功率问题(MII 频繁 up/down)
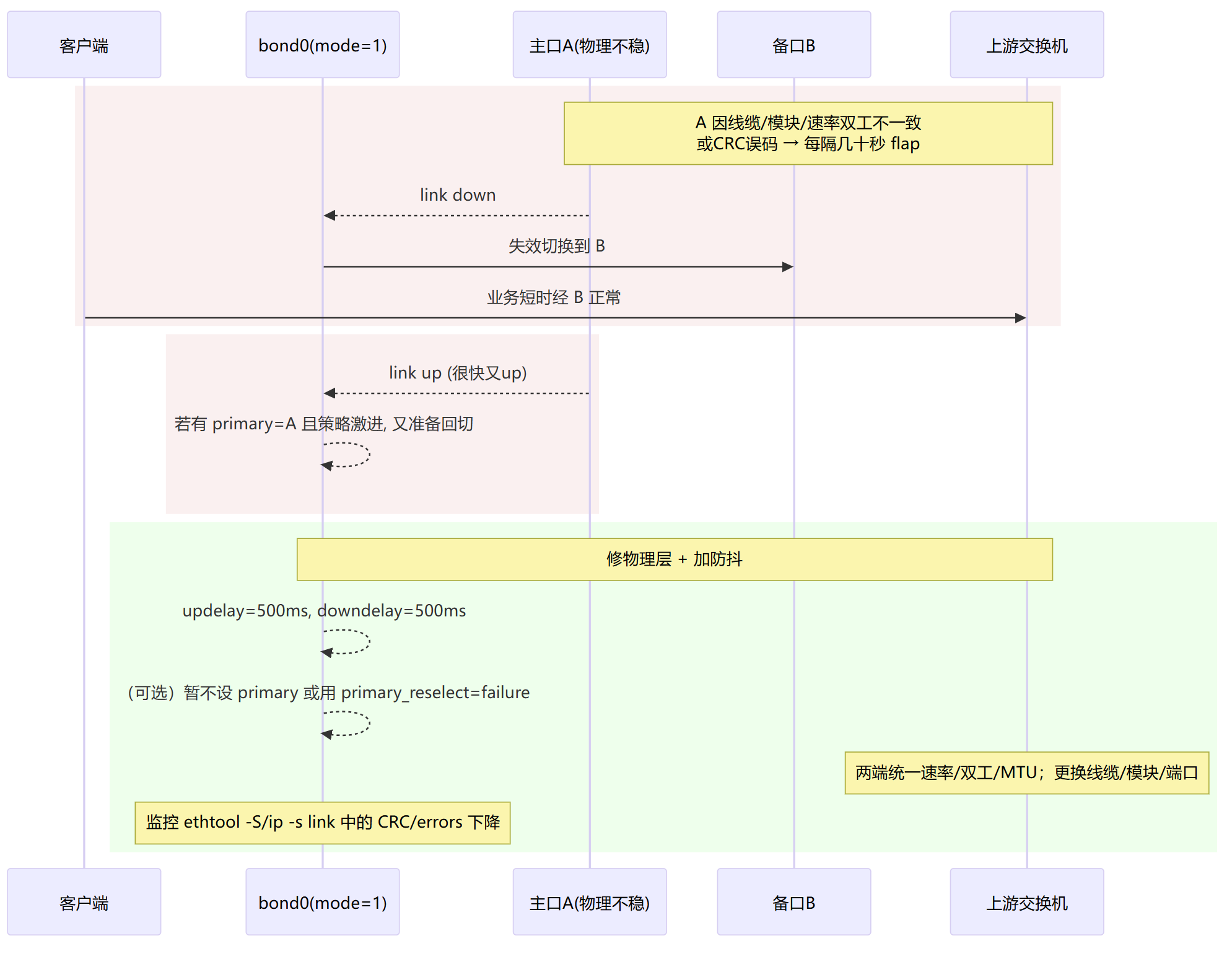
ARP 监测误判:arp_all_targets=all/目标不稳(通断抖动引发来回切)
只有一条链路在跑
LACP 不分担/成员未分发
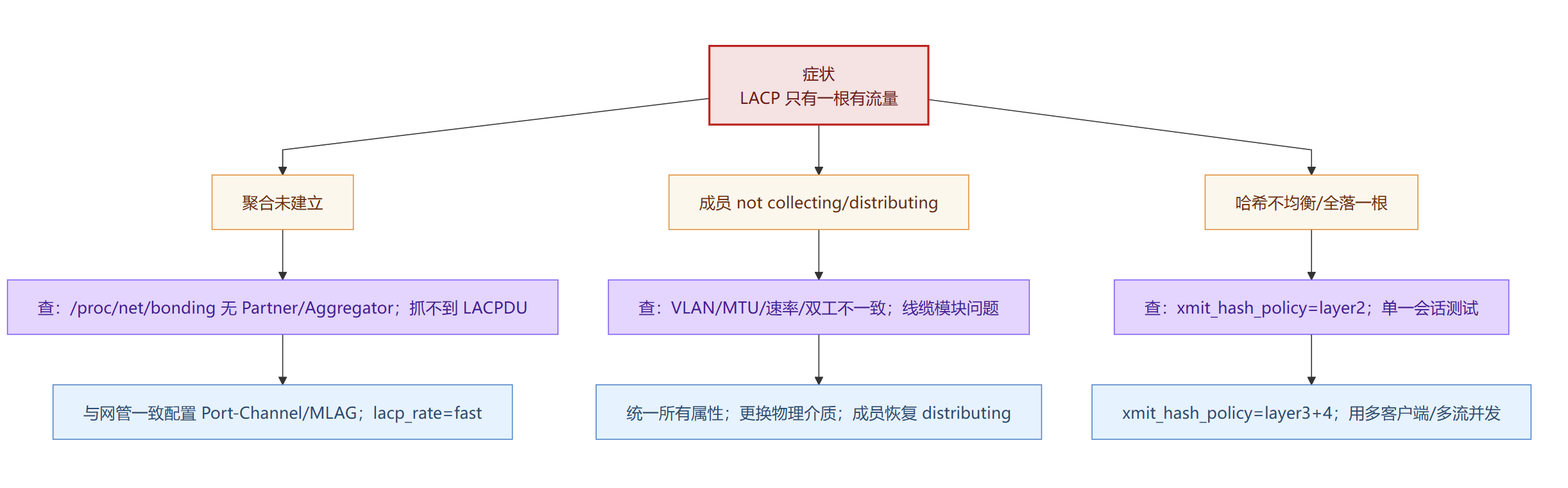
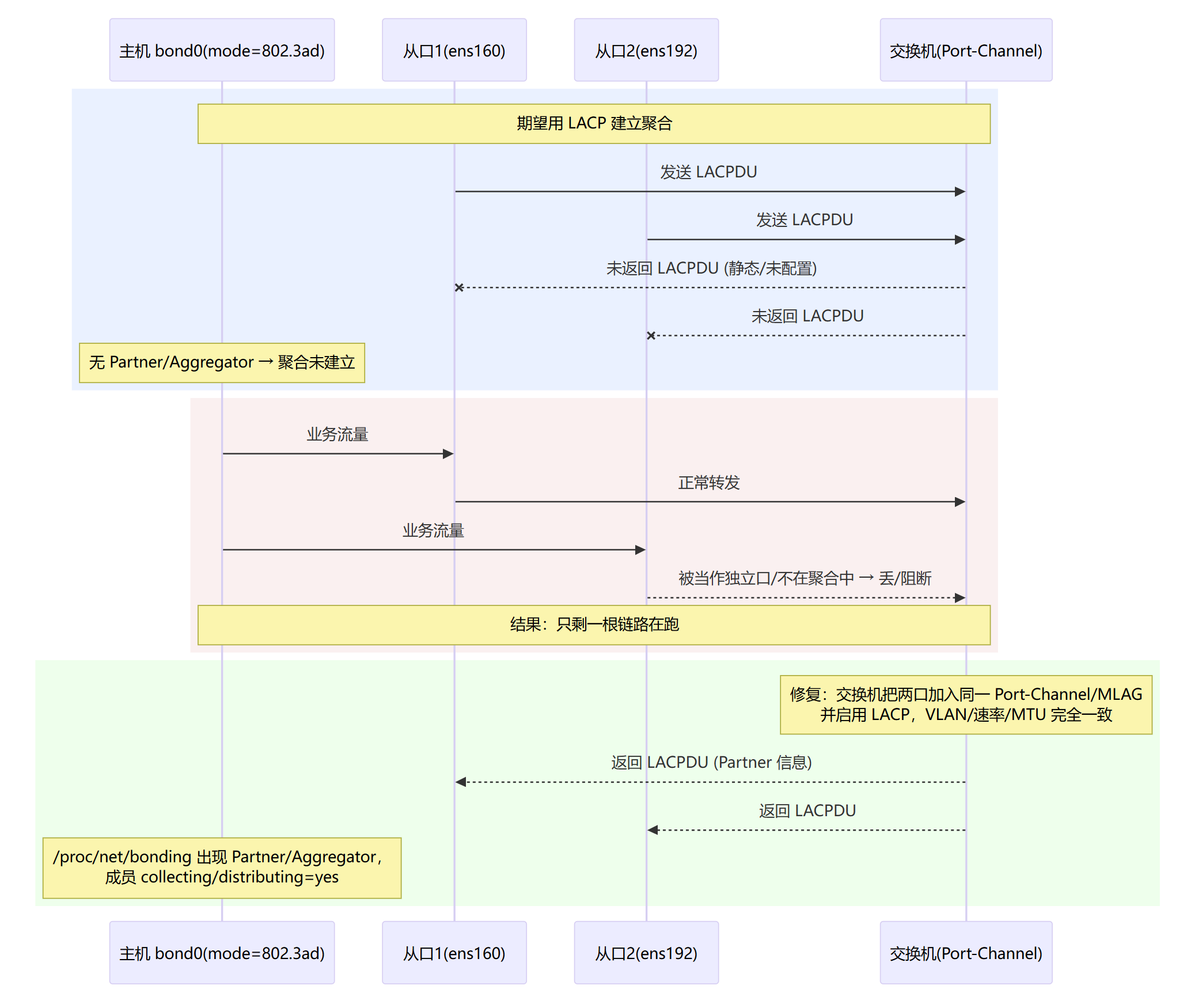
聚合未建立(交换机没开LACP/加入不同聚合)→ 退化成单链路
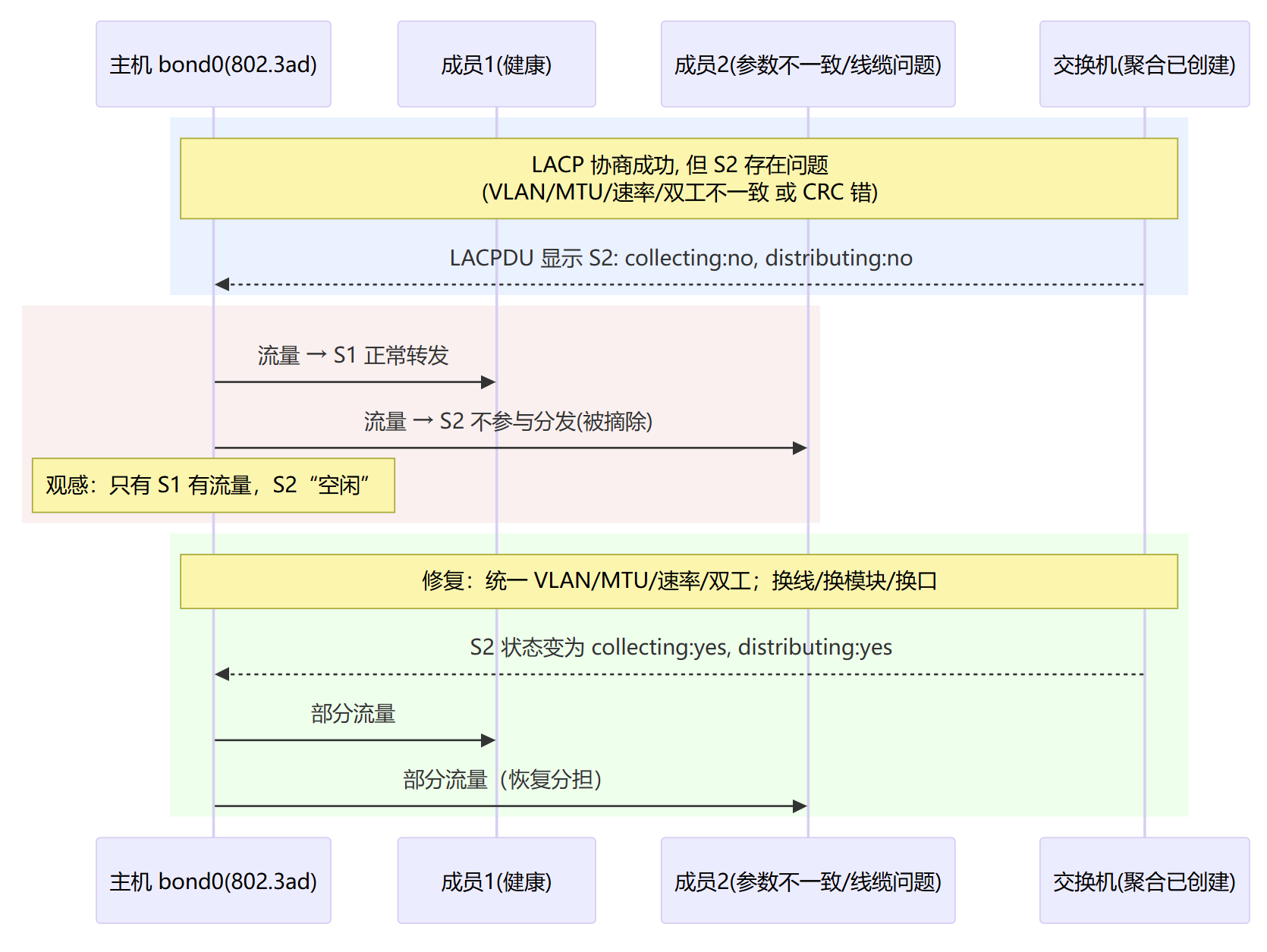
成员口“not collecting/distributing”(参数不一致/物理问题)→ 只有健康那根在转发
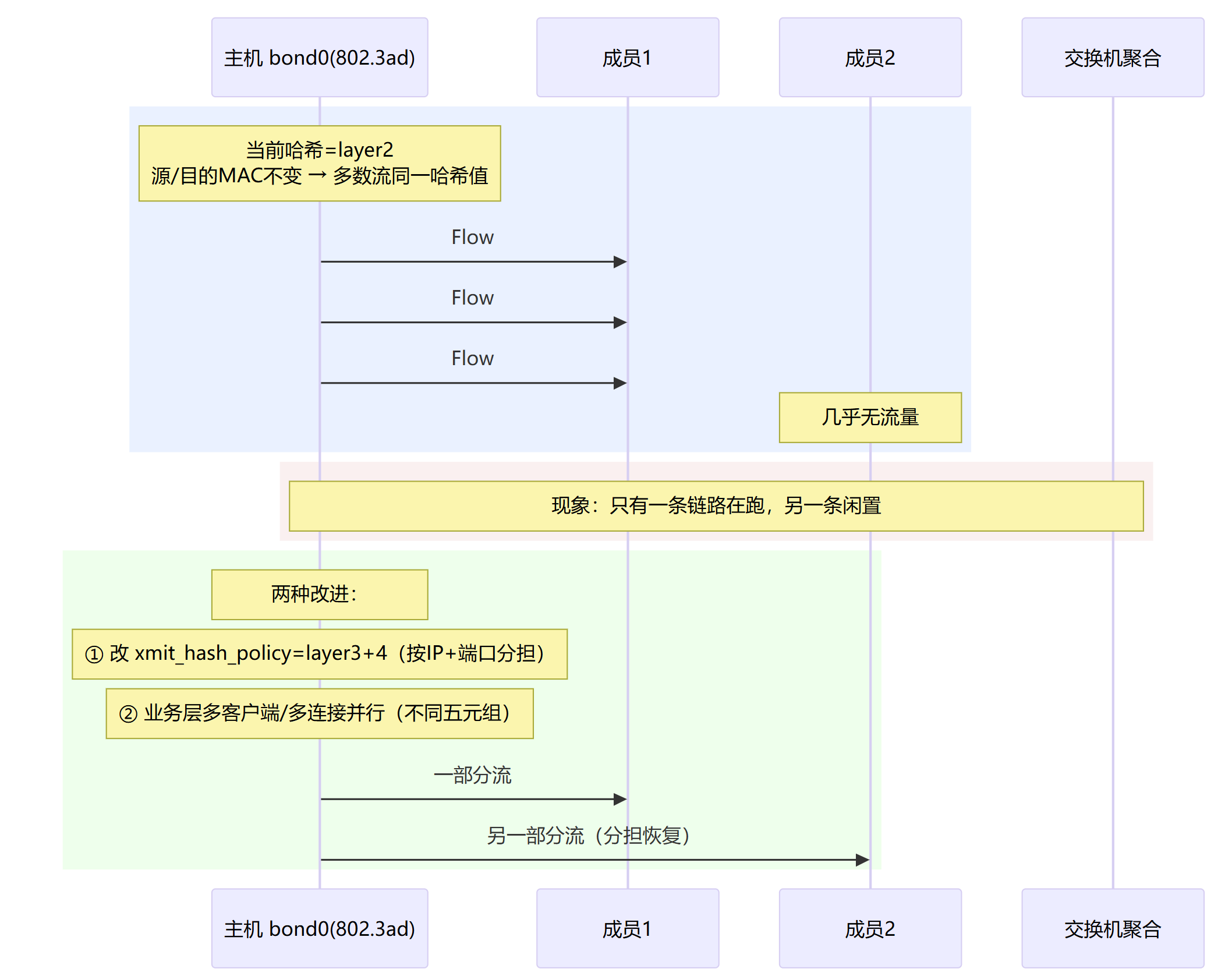
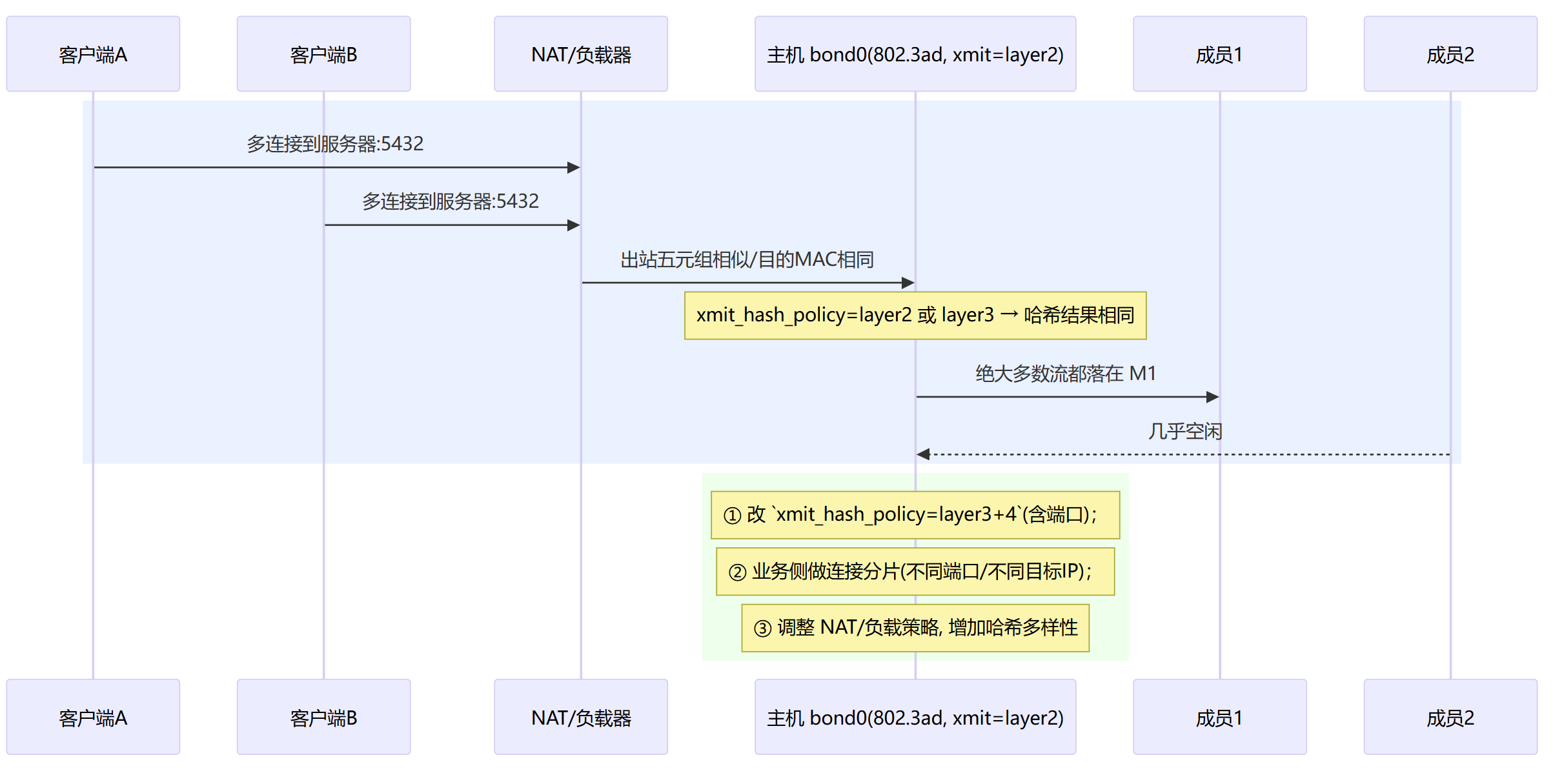
哈希不均衡(xmit_hash_policy=layer2 + 单一会话)→ 流量都落到同一根
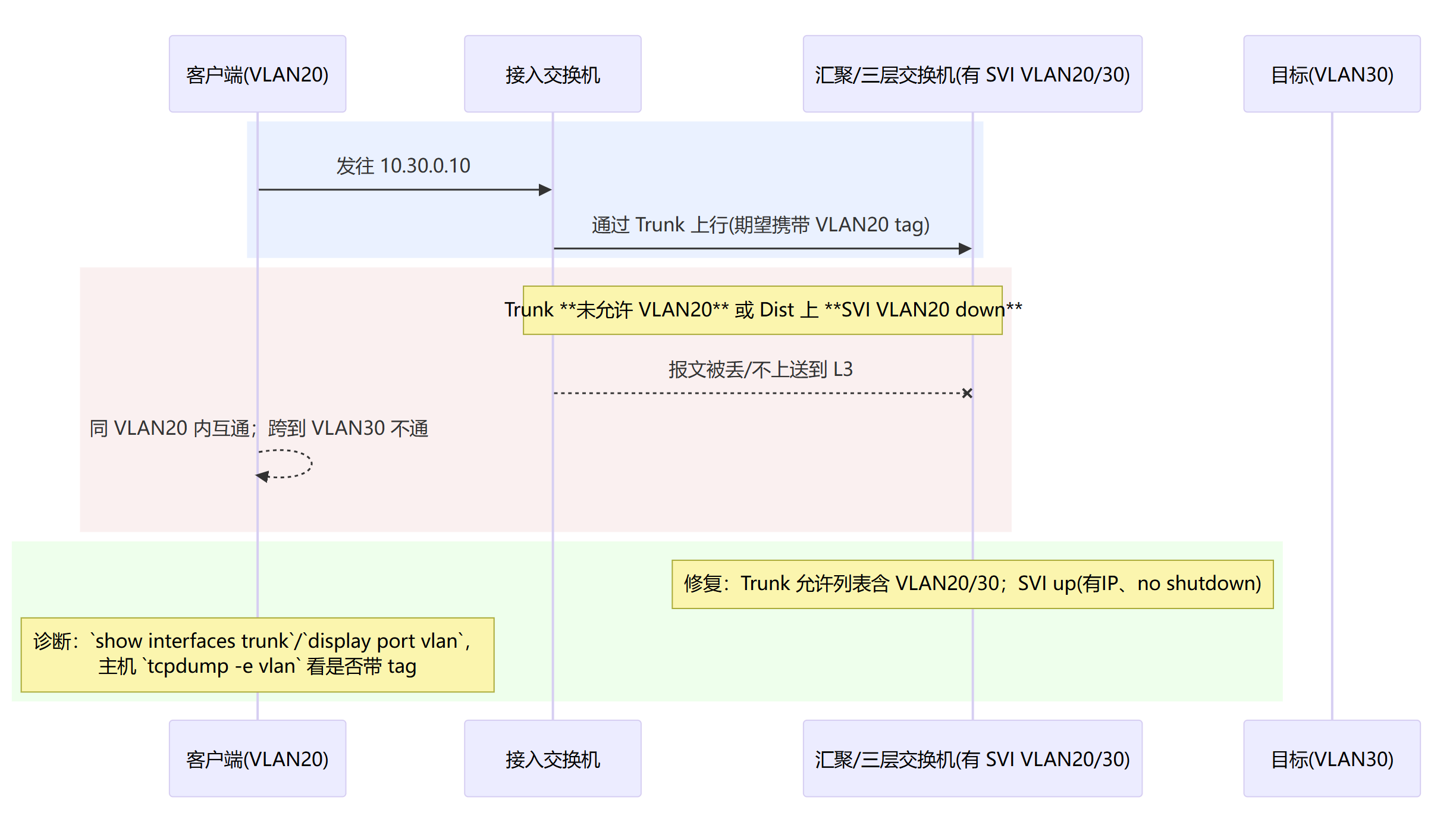
跨网段不通
同网段通、跨网段不通(多半是 L3/ACL)。
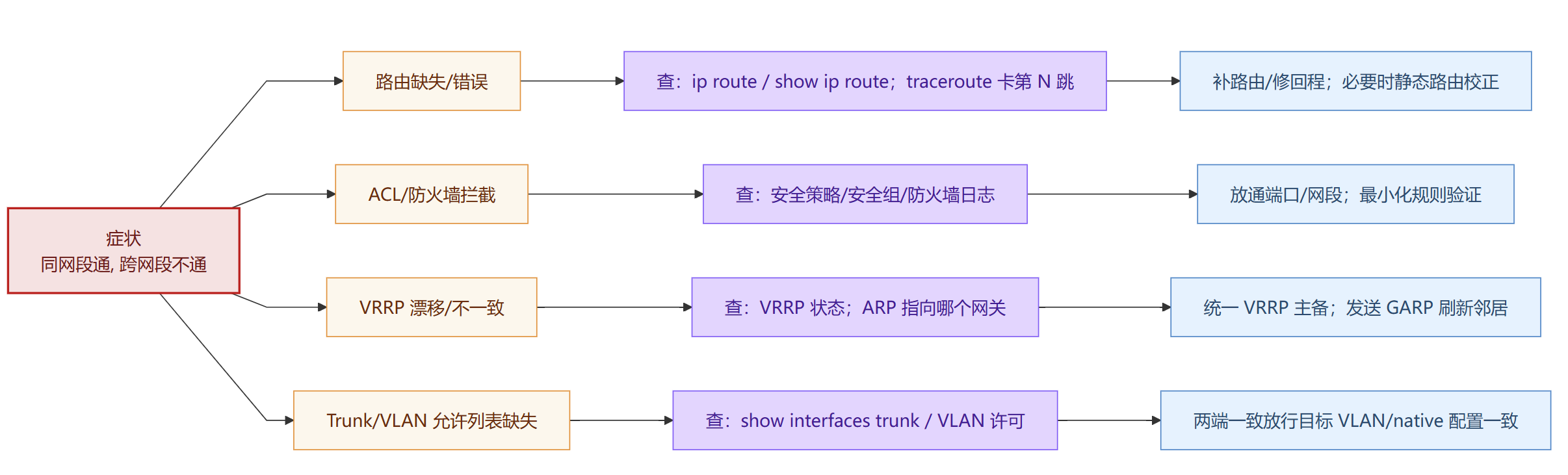
缺路由 / 回程路径丢(非对称路由)
ACL / 防火墙策略拦截(端口或网段未放通)
网关 VRRP 漂移/不一致(ARP 指向了“不会转发”的网关)
Trunk/VLAN 许可缺失 / SVI 未上线(L3 根本没起来)
带宽起不来
单流跑不满/多流也不均衡
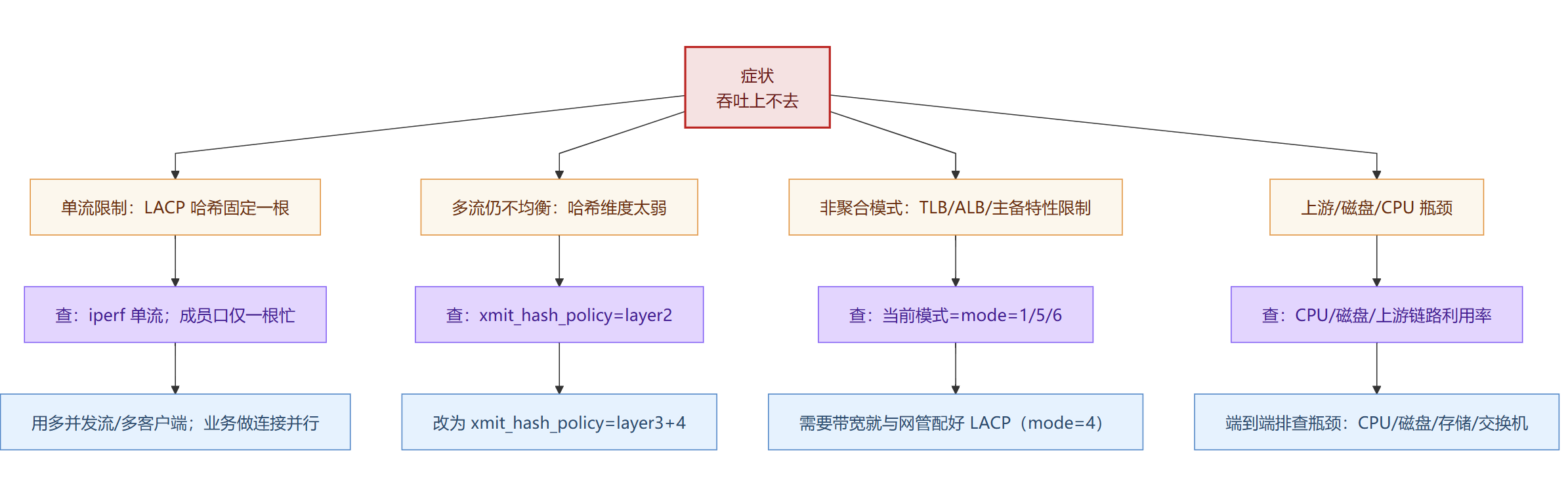
单流受限:LACP 无法把同一 TCP 流拆到多链路(1G 就只跑 1G)
哈希不均衡:哈希维度太弱 / NAT 使多流“看起来像一流”
模式能力上限:主备/TLB/ALB 本身就不叠带宽

端到端瓶颈:CPU/磁盘/虚拟化/队列导致“看起来是网慢”
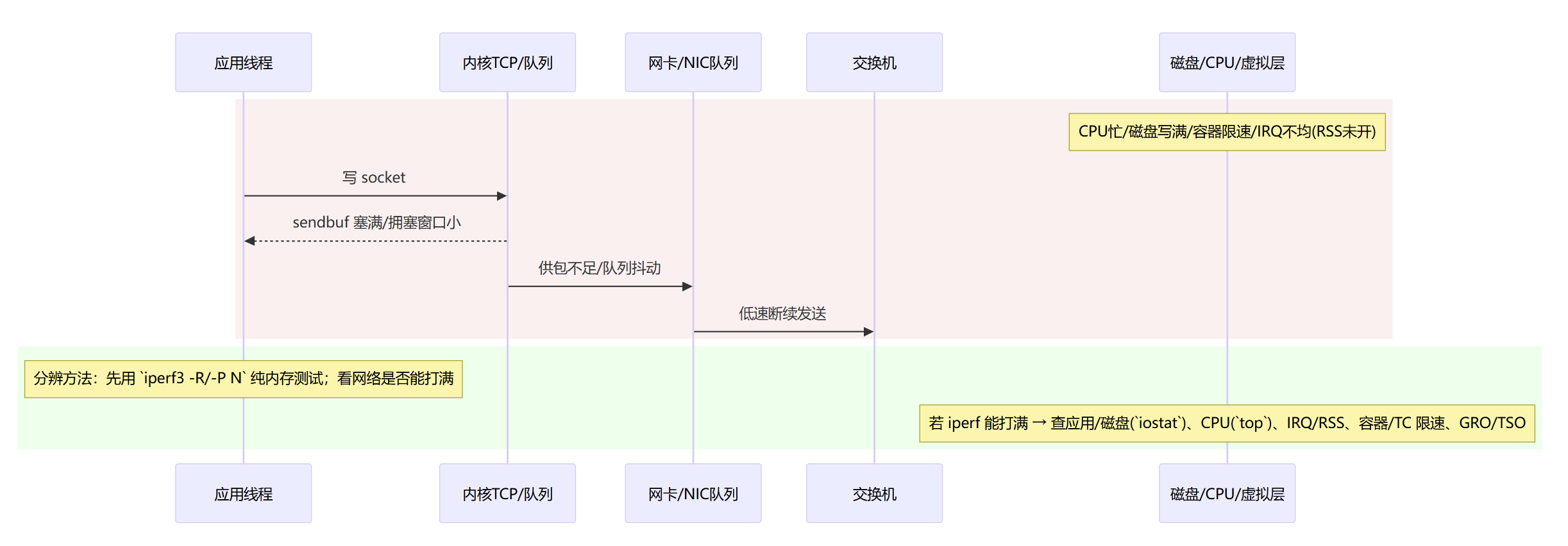
快速排查
/proc/net/bonding/bond0
cat /proc/net/bonding/bond0绑定状态“权威清单”。一口气看到 bond 的模式、探测方式、回切策略、每个从口健康与(LACP 时)协商细节。
Bonding Mode:确认是你预期的模式(1 主备 / 4 802.3ad / 5 TLB / 6 ALB / 0 RR…)。MII Polling Interval / Up/Down Delay或ARP Interval/Targets:当前用哪种探测(物理 or ARP),以及防抖时长。Primary Slave / Currently Active Slave:主口设置&当前活动口(频繁变化=抖动)。Link Failure Count:该从口累计失败次数(持续上升=不稳)。Speed/Duplex:两端应一致。仅 802.3ad:
802.3ad Partner Mac/Key/Port、Aggregator ID:看不见这些,多半交换机端没配好。collecting: yes, distributing: yes:成员参与分发;若no,这根被摘除(VLAN/MTU/物理问题)。 异常判读
Mode=0/2 但对端未聚合 → 丢包/抖动。
802.3ad 没有 Partner/Aggregator → 聚合没建立。
某从口
collecting/distributing: no→ 该口“不工作”。Link Failure Count急升 → 物理或上游抖动。常见坑,这份文件是实时状态;修改 ifcfg 后没重启网络,它不会变。
ip addr show bond0
ip addr show bond0IP/VIP/子网位于何处。确认 IP、掩码、VIP 是否绑在 bond0;是否有
secondary、scope global。inet 122.51.51.69/24是否在 bond0(而非某个从口)。VIP 应该也是绑在 bond0(
secondary也 OK)。异常:IP 绑错到从口 → 切换时黑洞/漂移失败。
ip neigh
ip neigh show dev bond0 | egrep -v REACHABLE有没有“找不到对方门牌号”。看 ARP 表是否完整、近期、正确。
关注
INCOMPLETE / FAILED / STALE的条目(尤其是网关/VIP/对端)。异常:
INCOMPLETE久不消失:对方 MAC 学不到 → VLAN/Trunk/黑洞/未发 GARP。
变体:
ip neigh show | grep <对端IP或网关IP>ip -s link
ip -s link show bond0 enp* | egrep 'RX|TX|errors|dropped|overrun|carrier'口级别丢包/错包统计。层 1/2 是否有硬错误/丢。
RX/TX errors/dropped/overrun/carrier是否增长。建议:隔 5 秒各跑一次,比对增量(增长≠0 就要追)。
异常:
carrier相关 → 物理层不稳;dropped/overrun→ 队列/驱动问题。
ethtoolðtool -Sethtool <iface> | egrep 'Speed|Duplex|Auto-negotiation|Link detected' ethtool -S <iface> | egrep -i 'err|drop|crc|miss|timeout|oversize|undersize|disc|no_buf' | head -n 30速率/双工/驱动统计。硬件速率/双工是否一致、驱动侧是否有 CRC/超时等。
Speed: 1000Mb/s、Duplex: Full、两端都自协商或都固定。统计项只要持续增长(尤其
rx_crc_errors / rx_discards / tx_timeout),就是红旗。异常:Half/Full 不一致、速率不一致 → 冲突/错包。
提示:统计项名称和驱动相关(ixgbe/mlx5/e1000…各异),看“增量”最稳。
dmesg -T
dmesg -T | egrep -i 'bond|NETDEV|link is (up|down)|reset|hang|ixgbe|mlx'内核日志里找 link flap/驱动异常。定位何时 up/down、驱动报错、bond 切换。
时间线:哪张网卡在什么时候 up/down;是否有
TX timeout / NIC reset。异常:频繁
link is down/up:物理不稳。驱动重置:可能固件/PCIe/中断问题。
mtr
mtr -rwnc 200 <网关或对端IP>连通性“体检报告”(抖动/丢在哪一跳)。
参数
-r报告模式(非交互)-w宽表-n不解析 DNS(更快更准)-c 200发送 200 个探测
Loss%、Avg/Best/Worst分布;若从第 N 跳开始抖,多半是 N 跳处或其后 的队列/策略问题。注意:某些运营商路由器对 ICMP 限速,不等于业务就丢;要结合同跳的后续节点判断。
ping大包/DF# IPv4 ping -c 10 -M do -s 1472 <对端IP> # 1472+28头=1500,标准以太网 ping -c 3 -M do -s 8972 <对端IP> # 测巨帧(若环境宣称支持)快速揪出 MTU 黑洞。路径 MTU 是否一致。
返回
Frag needed and DF set/Message too long→ 路径 MTU 更小。如果ICMP 被拦,会表现为超时(假阴性),此时逐步缩小
-s直到通过,推算路径 MTU。 IPv6 提示:IPv6 本就不允许中间设备分片;直接ping -6 -s 1452(1452+40=1492)逐步试。
tcpdump看 LACP PDUtcpdump -ni <slave-iface> ether proto 0x8809 -vv -c 5802.3ad 是否真的在跑。确认交换机端真在说 LACP。
能抓到
LACPDU(Slow Protocols 0x8809),并且双向都有 → LACP 正在协商。抓不到:要么抓错口,要么对端没开 LACP。 配合:再看
/proc/net/bonding/bond0中的Partner/Aggregator字段。
速查表
异常恢复后的回归测试
准备与基线
目标:验证稳定性、连通性、带宽、切换行为均达标;排除“偶发抖动/黑洞/只跑一条链路”等复发。
前提:修复后的配置已生效(重启网络/连接),并记录快照。
# 记录快照(用于对比/归档)
mkdir -p /root/bond-regress && cd /root/bond-regress
date +"%F %T" | tee 00_START.txt
cat /proc/net/bonding/bond0 | tee 01_bond.txt
ip addr show bond0 | tee 02_ip.txt
ip neigh show dev bond0 | tee 03_neigh.txt
for i in bond0 $(ls /sys/class/net | grep -E 'enp|ens|eth'); do
echo "=== $i ===" | tee -a 04_ethtool.txt
ethtool $i | egrep 'Speed|Duplex|Auto-negotiation|Link detected' | tee -a 04_ethtool.txt
ethtool -S $i | egrep -i 'err|drop|crc|miss|timeout|disc|no_buf' | tee -a 04_ethtool.txt
done
dmesg -T | egrep -i 'bond|NETDEV|link is (up|down)|reset|hang|ixgbe|mlx' | tail -n 200 | tee 05_dmesg.txt
基线对象
网关IP(同VLAN/L3上游)
对端主机(同城/异地各一台,最好有
iperf3服务)VIP 与数据库端口(例如 122.51.51.71:5432)
1. 连通性与时延抖动
mtr(ICMP基线)
# 同网段 → 网关
mtr -rwnc 200 <GATEWAY_IP> | tee 10_mtr_gw.txt
# 业务对端(库/应用)
mtr -rwnc 200 <PEER_IP> | tee 11_mtr_peer.txt
验收(数据中心内/园区网参考阈值)
丢包:0%(中间跳限速不算,最后一跳必须 0%)
抖动:
Worst - Best< 5~10ms(同城);跨城视链路而定
MTU/碎片黑洞
# 以太网标准 MTU 1500:1472 + 28 头 = 1500
ping -c 10 -M do -s 1472 <PEER_IP> | tee 12_ping_mtu_1500.txt
# 若宣称巨帧 9000,做大包验证
ping -c 5 -M do -s 8972 <PEER_IP> | tee 13_ping_mtu_9000.txt
验收
不得出现
Frag needed and DF set/超时;若失败 → 统一 MTU 或设置 MSS 限制。
2. 带宽与分担
iperf3(多流吞吐)
# 对端先启动:iperf3 -s
iperf3 -c <PEER_IP> -P 8 -t 30 | tee 20_iperf_up.txt # 本机→对端
iperf3 -c <PEER_IP> -P 8 -t 30 -R | tee 21_iperf_down.txt # 对端→本机
验收
单口1G聚合:多流总吞吐 ≥ 1.7~1.9Gbps(双链路理论 2G,扣协议开销/路径差)
10G/25G 环境同比例达标(≥90% 链路能力)
成员分担(仅 LACP/TLB/ALB 相关)
# 采样各从口收发
sar -n DEV 1 30 | tee 22_sar_dev.txt
# 或 ifstat 实时
ifstat -i <slave1>,<slave2> 1 30
# LACP成员是否参与分发
awk '/Slave Interface|collecting|distributing/{print}' /proc/net/bonding/bond0 | tee 23_bond_members.txt
验收
LACP:所有成员
collecting: yes, distributing: yes;多流时各成员流量分布相近(偏差 ≤ 30% 为宜)TLB:出站(tx) 可见分担;ALB:同二层多客户端时 入站(rx) 也应分担
3. 故障切换演练
用“软方式”模拟拔线更安全,可复现:
主机侧:
ip link set dev <slave> down虚机:在 vSwitch/PG 暂时把某 uplink 置为
Unused交换机:临时
shutdown某成员口或从聚合中移除
失效切换(Active → Standby)
# 1) 连续探测(另一个终端) ping -O <VIP_OR_PEER_IP> | ts '[%H:%M:%S]' | tee 30_ping_during_failover.txt # 2) 切换动作(本终端) ip link set dev <ACTIVE_SLAVE> down sleep 5 ip link set dev <ACTIVE_SLAVE> up同时抓取
tcpdump -ni bond0 arp -vv -c 10 | tee 31_garp.txt验收
丢包不超过 3 个 ICMP(~3 秒内恢复为上限,良好配置通常 0~1 个)
tcpdump能看到 GARP ≥ 3 次(与你的num_grat_arp一致)/proc/net/bonding/bond0的Currently Active Slave切换正确;Link Failure Count合理+1
恢复/回切策略验证
主备:
primary_reselect=failure→ 主口恢复不立刻回切;只有当前口失败才回有需要回切时:把现有活动口
down,观察是否回到 primary 验收无频繁回切(日志/active slave 不应来回跳)
updelay/downdelay生效(切换时间≈设定值,减少“刚亮就切”)
LACP 专项(若用 mode=4)
# 看 LACPDU 与伙伴信息 tcpdump -ni <slave> ether proto 0x8809 -vv -c 5 | tee 32_lacp_pdu.txt cat /proc/net/bonding/bond0 | egrep -i '802.3ad|Partner|Aggregator|collecting|distributing' | tee 33_lacp_state.txt # min_links 验证:降到阈值以下,bond 应整体 down ip link set dev <SLAVE2> down # 观察 MII Status / 上层探测是否感知 bond down ip link set dev <SLAVE2> up 验收
有 Partner/Aggregator 字段;所有成员
collecting/distributing=yeslacp_rate=fast下,成员 up/down 的感知在秒级min_links行为与设定一致(例如< 2成员就bond down)
4. L2/L3 配置完整性
VLAN/Trunk/native 一致性
tcpdump -ni bond0 -e vlan -c 10 | tee 40_vlan_tag.txt验收
需要打标签的流量能看到
vlan <ID>;native VLAN 双端一致
路由与回程
ip route show | tee 41_route.txt
traceroute -n <PEER_IP> | tee 42_trace.txt
验收
去/回程对称或可接受的非对称;无缺失路由/被黑洞
5. 日志与计数器“归零观察”
# 记录“起点”
for i in bond0 $(ls /sys/class/net | grep -E 'enp|ens|eth'); do
ethtool -S $i | egrep -i 'err|drop|crc|miss|timeout|disc|no_buf' > /tmp/${i}_stat.start
done
# 10~15 分钟后复采
for i in bond0 $(ls /sys/class/net | grep -E 'enp|ens|eth'); do
ethtool -S $i | egrep -i 'err|drop|crc|miss|timeout|disc|no_buf' > /tmp/${i}_stat.end
echo "=== $i ==="; diff -u /tmp/${i}_stat.start /tmp/${i}_stat.end || true
done
验收
错包/丢包计数不增长(或仅极小幅度/可解释的增长)
dmesg无新的link is down/up、TX timeout、reset等告警
6. 数据库与业务验证
连接/握手
pg_isready -h <VIP> -p 5432 -t 2
psql "host=<VIP> port=5432 dbname=<DB> user=<USER> options='-c statement_timeout=2000'" -c 'select 1;'
读写/复制场景
用应用实际的健康检查与读写路径跑一轮;备库/归档/复制链路也做一次吞吐与延时观测。
验收
健康检查/应用日志无错误;复制延迟、归档成功率维持正常区间
8. 结果归档与回滚预案
打包证据
tar czf bond-regress_$(hostname)_$(date +%F_%H%M).tar.gz /root/bond-regress
echo "证据包: bond-regress_$(hostname)_$(date +%F_%H%M).tar.gz"
回滚建议(必要时)
明确上一次可用配置(ifcfg/nmcli 备份/交换机 Port-Channel 配置)
回滚后重复本回归测试的关键用例(连通性、切换、带宽三件套)