蓝象十日谈·第01日_数据库的发展历程
数据库的发展历程
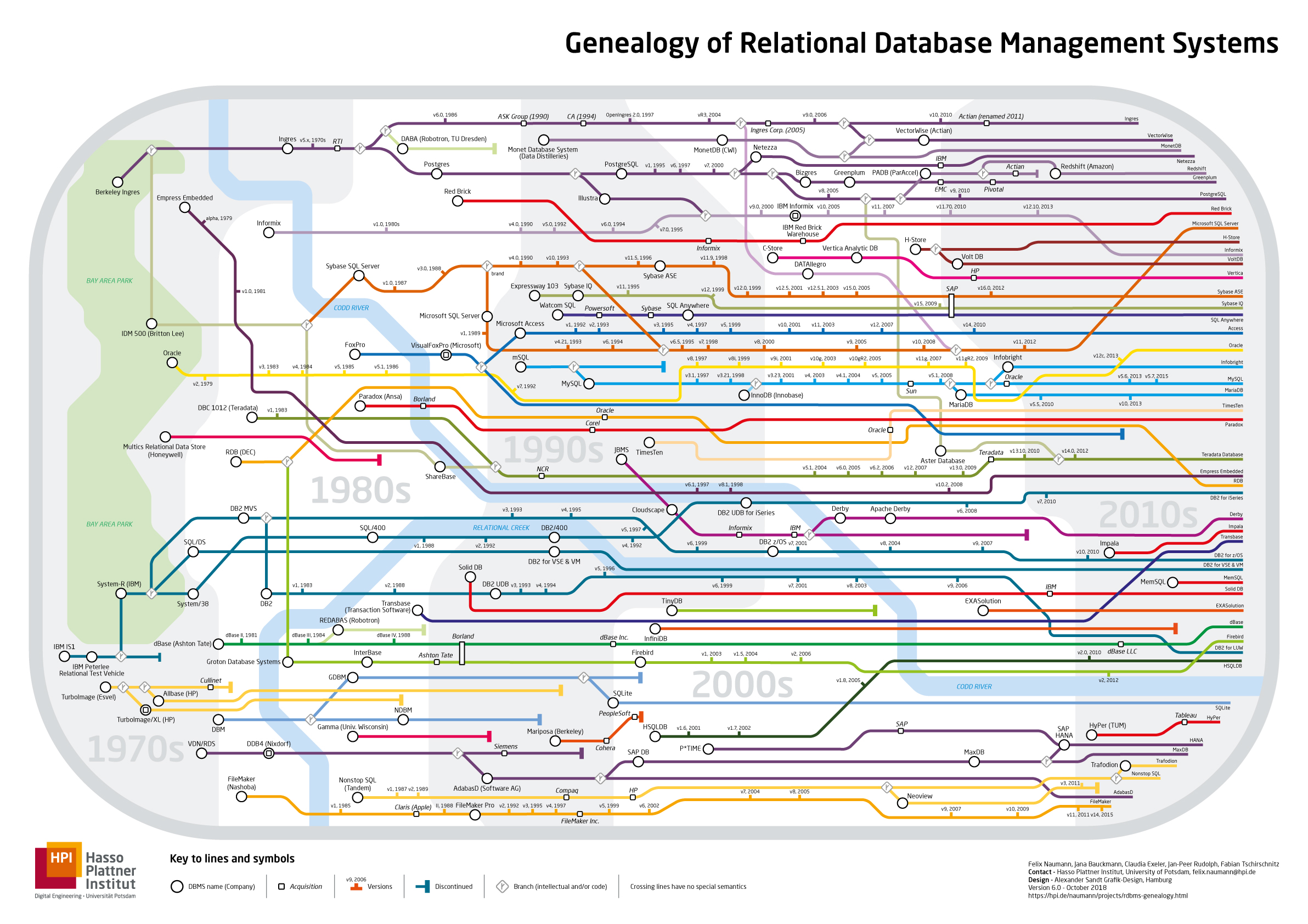
滚滚长江东逝水,浪花淘尽英雄。数据库系统的发展历程波澜壮阔,血脉丛横交错。每个年代都有各自的佼佼者和里程碑。主线脉络我这里分为8条:
IBM 系统 R → DB2
1970s 的 System R 奠定了 SQL 与商用 RDBMS 的起点,随后发展为 DB2,并衍生出多条企业级分支(如 OS/400、Mainframe 等)。
Ingres/POSTGRES → PostgreSQL
伯克利 Ingres 一脉演化到 POSTGRES、Postgres95,最终成为 PostgreSQL。这条线上你会看到:
Illustra(Stonebraker 团队)被 Informix 吸收,推动了对象-关系特性。
Greenplum、Bizgres、ParAccel(PADB)等以 PostgreSQL 为前端或基础作了 MPP/列存创新,Amazon Redshift 则来自 ParAccel 的谱系。
MonetDB / VectorWise 等列式数据库与分析型家族在右上方并行发展,对现代分析引擎影响深远。
Sybase ↔ Microsoft SQL Server
早期 MS SQL Server 与 Sybase 共享渊源,90年代后各自独立快速演进,形成今天的两大企业级阵营之一。
Oracle
80年代起几乎贯穿全图,一军崛起。大量并购节点(方块)和与 TimesTen 等内存/加速技术的融合;另外 Oracle 收购 Sun 后间接拿到 MySQL 的归属权,成为历史转折点。
MySQL 家族与存储引擎
InnoDB(Innobase) 被 Oracle 收购后成为主流引擎。
MariaDB、Percona 等 fork/变体在 2010s 分支壮大。
MySQL 线上的版本密集里程碑反映了 LAMP 时代的高增速。
分析型与“云数仓”崛起
Teradata、Red Brick、Netezza、Vertica、Greenplum、ParAccel → Amazon Redshift, 2000s–2010s 列式存储、MPP、云托管 的浪潮。
NewSQL/内存型探索
H-Store、VoltDB 等在 2010s 初期出现,主打内存计算与分布式事务的新路线。
轻量嵌入式支线
SQLite 以独立、嵌入式定位。
整个数据库发展历程的开端为文件系统阶段,数据直接存储在文件系统中,由程序负责管理。这导致了许多许多问题,无法使用非过程语言(SQL)进行查询,只能由非常专业的程序员去进行维护,而且数据冗余高,难以维护。之后是层次模型和网络模型阶段,这个阶段采用树状结构存储数据,比如IBM的IMS系统,用于银行和航空等行业的大型事务处理。优点当然是树形数据结果的查询速度快,缺点则是数据和代码是耦合的,维护难度依旧高居不下。网络模型使用图结构表示数据关系,但是需要鉴别的是,这并不是现在图数据库的雏形,网络模型CODASYL,使用指针式集合(owner_member的set type)把记录连城网状,直觉上看很像“图”(graph),但是是导航式,过程式的数据模型,和今天的图数据库(property graph/RDF )不同。
关系模型的兴起是在层次模型和网络模型应用之后,数据库技术逐渐成熟,但是查询灵活性差,操作复杂等问题,这些问题都迫使一种新的模型出现来解决。1970年,祖师爷科德(E.F.Codd)提出了关系模型的理论,这个理论基于集合论和关系代数。随后逐步出现了一些依据此理论进行实现的数据库类型。一个模型的成功必然需要从理论走向大规模应用,不断打磨和升级改造。1994年C. Mohan提出了ARIES(Algorithms for Recovery and Isolation Exploiting Semantics)论文,详细对数据库管理,故障恢复以及并发控制提供了关键性的技术基础,我们现代关系型数据库的许多关键性概念,都可以从这篇论文中找到雏形。
随着时代发展,还有一些现代类型的数据库比如Nosql,图数据库,向量数据库等,包括日志即数据库的Amazon Aurora这里不再详细讨论,这些新型的数据库类型有些屹立不倒,有些则出生不到1年就销声匿迹。关系型数据库截至现在,还是数据库世界中的主流和重点,而且关系型这个概念正在主键模糊化,许多数据库实现都具备了非关系型的扩展功能,数据生态正在一步步的走向大一统。
PostgreSQL的背景与定位
postgresql官网的一句话介绍是,The world's most advanced open source database,世界上最先进的开源数据库。1986年,UC Berkeley大学发起POSTGRES项目,由Michael Stonebraker领导。最初仅仅是一个面相对象的数据库管理系统。直到1995年,这个项目被开源(Postgres95),这是一个重大的里程碑事件。1996年,重命名为PostgreSQL,支持SQL标准,转型为一个开源关系数据库。到目前为止,postgresql拥有广大而活跃的社群。在功能上支持插件,用于自定义的数据类型,最大限度的支持了SQL标准。

PostgreSQL的主要特性
开源和社区支持
完全免费,遵循PostgreSQL许可协议。
活跃的全球社区,快速响应安全问题和新需求。
丰富的数据类型
标准数据类型:整型、字符型、日期型。
扩展数据类型:JSON/JSONB、数组、地理空间数据(PostGIS)。
强大的功能
支持事务和MVCC(多版本并发控制)。
高级索引:GIN、GiST、BRIN等。
支持外部数据源访问(FDW)。
灵活的扩展性
自定义函数与过程:支持PL/pgSQL、Python等多种语言。
插件生态:如PostGIS、TimescaleDB。
高性能与高可靠性
WAL日志机制确保数据安全。
支持流复制、逻辑复制,满足多种高可用场景。
Postgresql发行时间线

PostgreSQL 每个主版本的支持周期为 5 年:
第 1 年:提供功能更新和错误修复。
第 2~5 年:提供安全补丁和错误修复。
超过 5 年后,该版本进入 终止支持(EOL,End-of-Life) 状态,不再提供任何更新。
PostgreSQL 的版本命名方法经历了一个重要的变化:
PostgreSQL 10 之前(包括 9.x 系列):使用
X.Y.Z的格式。X:主版本号(例如9)。Y:次版本号(例如6表示9.6系列)。Z:补丁版本号,用于修复错误或安全问题(例如9.6.20)。
PostgreSQL 10 及以后:仅使用两位数字
X.Y表示版本号。X:主版本号(例如10)。Y:次版本号,用于表示错误修复或安全更新的版本(例如10.21)。
主版本号变更表示功能和特性的大规模更新。可能引入重大变化(如性能优化、新增功能、旧功能废弃等)。
次版本号变更表示该主版本的错误修复、安全补丁或小幅优化。通常是向后兼容的。
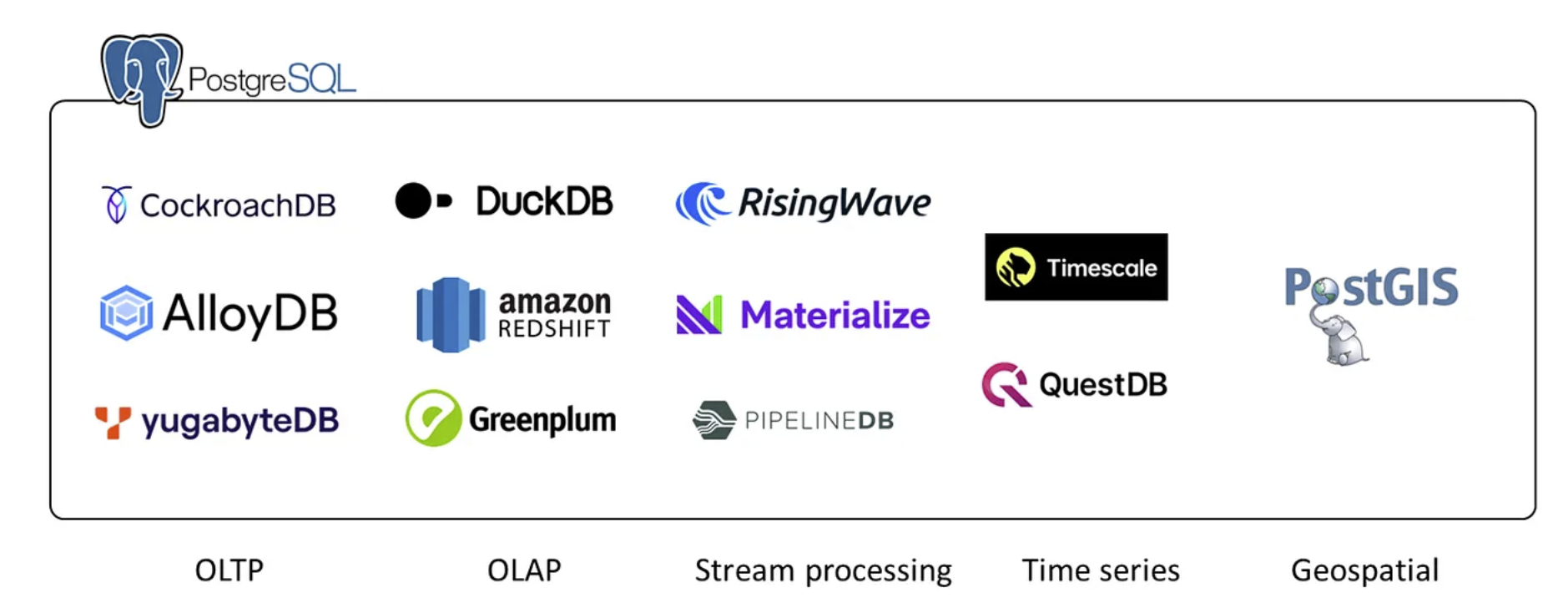
PostgreSQL 生态系统:在 PostgreSQL 之上开发的系统或与 PostgreSQL 线兼容的系统。