Scalable SQL and NoSQL Data Stores
Rick Cattell Originally published in 2010, last revised December 2011
本文翻译仅限学习使用,严禁用于任何的商业用途
作者Rick Cattell是数据库领域的大佬常青树,本文更是高屋建瓴的概括了NoSQL数据库,回到过去,一起领略14年前大佬的文章,以下是译文部分
ABSTRACT
在本文中,我们研究了一些SQL和所谓的NoSQL数据存储,这些数据存储被设计用于在多台服务器上扩展简单的OLTP(在线事务处理)风格的应用负载。最初受Web 2.0应用程序的推动,这些系统旨在支持成千上万或数百万用户进行更新和读取,这与传统的数据库管理系统(DBMS)和数据仓库形成对比。
我们从以下方面对新系统进行了对比:
数据模型
data model一致性机制
consistency mechanisms存储机制
storage mechanisms持久性保证
durability guarantees可用性
availability查询支持
query support其他维度
这些系统通常会在某些维度上做出牺牲,例如放弃数据库范围内的事务一致性,以换取其他目标,例如更高的可用性和可扩展性。
注意:这些系统的参考文献未列出,但更多信息的URL可以在本文末尾的“系统参考”表中找到。 提醒:本文中的陈述基于的来源和文档可能并不可靠,描述的系统是“移动的目标”,因此某些陈述可能不正确。在依赖本文信息之前,请通过其他来源进行验证。尽管如此,我们希望这份全面的调查是有用的!请在作者网站cattell.net/datastores查看未来的更正。 披露:作者是Schooner Technologies的技术顾问委员会成员,并且有一家提供可扩展数据库咨询服务的业务。
1. OVERVIEW
概述 近年来,许多新系统被设计出来,在多个服务器上实现水平扩展能力,用于更好的进行简单的读写的数据库操作。相较之下,传统的数据库产品在这些应用上几乎没有或完全没有水平扩展的能力。本文考察并比较了各种新系统。
许多新系统被称为NoSQL数据存储。NoSQL的定义,即Not Only SQL或Not Relational,尚未完全达成共识。
本文的目的在于,即一般来说NoSQL系统具有六个关键特征:
能够在多台服务器上水平扩展
简单操作the ability to horizontally scale
simple operationthroughput over many servers能够在多台服务器上复制和分布(分区)数据
the ability to replicate and to distribute (partition) data over many servers
具有简单的调用级接口或协议(与
SQL绑定形成对比)a simple call level interface or protocol (in contrast to a SQL binding)
拥有比大多数关系型(
SQL)数据库系统的ACID事务更弱的并发模型a weaker concurrency model than the ACID transactions of most relational (SQL) database systems
高效利用分布式索引和
RAM进行数据存储efficient use of distributed indexes and RAM for data storage
能够动态添加数据记录的新属性
the ability to dynamically add new attributes to data records
这些系统在其他方面有所不同,本文将对这些差异进行对比。它们的功能范围从最简单的分布式哈希distributed hashing(如流行的开源缓存memcached所支持)到高度可扩展的分区表(如Google的BigTable [1]所支持)。实际上,BigTable、memcached和Amazon的Dynamo [2]提供了一种概念验证proof of concept,激发了我们在这里描述的许多数据存储系统:
Memcached 证明了内存索引可以高度可扩展,将对象分布和复制到多个节点。
Dynamo 首创了最终一致性概念,作为实现更高可用性和可扩展性的方法:获取的数据不能保证是最新的,但更新最终会传播到所有节点。
BigTable 证明了持久记录存储可以扩展到数千个节点,这也是大多数其他系统所追求的目标。
NoSQL系统的一个关键特征是无共享shared nothing的水平扩展——在多台服务器上复制和分区数据。这使它们能够支持每秒大量的简单读写操作。这种简单的操作负载传统上称为OLTP(在线事务处理online transaction processing),但在现代Web应用程序中也很常见。
这里描述的NoSQL系统通常不提供ACID事务属性:更新最终会被传播,但对读取的一致性只有有限的保证。一些作者提出了一个与ACID相对的BASE缩写:
BASE = 基本可用(Basically Available),软状态(Soft state),最终一致(Eventually consistent)
ACID = 原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)
其想法是,通过放弃ACID约束,可以实现更高的性能和可扩展性。然而,不同系统在放弃的程度上有所不同。例如,大多数系统称自己为最终一致性eventually consistent,这意味着更新最终会传播到所有节点,但其中许多系统也提供某种程度的一致性机制,例如多版本并发控制(MVCCmulti-version concurrency control)。
NoSQL的支持者经常引用Eric Brewer的CAP定理[4],该定理指出一个系统在以下三个属性中只能有两个:一致性consistency、可用性availability和分区容错性partition-tolerance。NoSQL系统通常放弃了一致性。然而,正如我们将看到的,这种权衡是复杂的。
新的关系型数据库管理系统(DBMS)也被引入,以提供比传统RDBMS更好的OLTP水平扩展能力。在考察NoSQL系统后,我们将研究这些SQL系统,并比较其方法的优缺点。SQL系统力求在不放弃SQL和ACID事务的情况下提供水平扩展能力。我们将在此讨论这些权衡。
在本文中,我们将新型SQL和NoSQL系统都称为数据存储data stores,因为“数据库系统”这个术语通常用于指代传统的DBMS。然而,我们仍将使用“数据库”一词来指代这些系统中存储的数据。所有的数据存储都有一个可以称之为数据库的管理单元:数据可以存储在一个文件中,或在一个目录中,或通过某种其他机制来定义一组应用程序使用的数据范围。即使数据库被分区并分布在多台机器上,每个数据库仍是一个独立的实体:在这些系统中(与某些关系型和面向对象的数据库不同),没有联合数据库federated database概念,允许多个独立管理的数据库表现为一个。大多数系统允许数据的横向分区,根据某个键将记录存储在不同的服务器上,这被称为分片sharding。其中一些系统还允许纵向分区vertical partitioning,即单条记录的不同部分存储在不同的服务器上。
1.1 Scope of this Paper
在继续之前,需要对水平扩展和简单操作进行一些定义澄清。这些定义是本文的重点。
简单操作是指键查找、读取和写入一条或少量记录的操作。这与复杂查询或连接、主要为读取的访问或其他应用负载不同。随着网络的发展,特别是Web 2.0网站的兴起,数百万用户可能同时读取和写入数据,简单数据库操作的可扩展性变得更加重要。例如,应用程序可能需要在多服务器的电子邮件、个人资料、网页发布、维基、客户记录、在线约会记录、分类广告等数据库中进行搜索和更新。这些通常都符合简单操作应用的定义:每次操作读取或写入少量相关记录。
水平扩展指的是能够将这些简单操作的数据和负载分布在多台服务器上,而服务器之间不共享RAM或磁盘。水平扩展horizontal scalability与垂直vertical扩展不同,垂直扩展是指一个数据库系统利用共享RAM和磁盘的多核和/或多个CPU。我们描述的一些系统同时提供垂直和水平扩展能力,而有效利用多个核心也很重要,但我们的主要关注点是水平扩展,因为能够共享内存的核心数量有限,而水平扩展通常被证明成本更低,使用的是通用服务器。需要注意的是,水平和垂直分区与水平和垂直扩展没有直接关系,除了它们在水平扩展中都有用之外。
[NOTE!]
水平扩展还是垂直扩展是个仁者见仁智者见智的事情,10年前限于算力,单节点堆积算力往往在成本上要远高于水平扩展,但是这几年这种情况有些转变,超级节点的出现又让这个问题峰回路转,而且单节点在项目开发和运维成本上要远低于集群化的项目,译者在此并不是反驳文中观点,而是说该文写于10年前,有时代背景的。
1.2 Systems Beyond our Scope
一些作者对NoSQL使用了广义定义,包括任何非关系型的数据库系统。具体来说,他们包括以下几种系统:
图数据库系统:如
Neo4j和OrientDB,提供对节点图及其相互引用的高效分布式存储和查询。面向对象的数据库系统:面向对象的DBMS(例如
Versant)也提供对象图的高效分布式存储,并将这些对象实现为编程语言中的对象。分布式面向对象存储:与面向对象的DBMS非常相似,如
GemFire这样的系统在多台服务器上内存中分布对象图。
这些系统是需要快速且广泛引用跟踪的应用程序的良好选择,尤其是数据可以放入内存的情况下。编程语言的集成也是很有价值的。不像NoSQL系统,这些系统通常提供ACID事务。许多此类系统也提供参考跟踪和分布式查询分解的水平扩展能力。然而,由于篇幅限制,我们在比较中省略了这些系统。对于这些系统的应用及其扩展优化,与我们在此涵盖的系统不同,这里主要以键查找和简单操作为主,而不是引用跟踪和复杂的对象行为。这些系统也可能在简单操作上具有可扩展性,但这是未来论文的主题,需要通过基准测试来证明。
数据仓库数据库系统提供水平扩展,但也超出了本文的讨论范围。数据仓库应用在一些重要方面有所不同:
它们执行复杂的查询,从多个不同的表中收集并连接信息。
读取与写入的比率很高:也就是说,数据库是只读的或以读取为主。
现有的数据仓库系统在水平扩展方面表现良好。由于数据更新不频繁,可以以有助于以扩展的方式组织或复制数据库。
1.3 Data Model Terminology
与关系型(SQL)数据库管理系统不同,NoSQL数据存储使用的术语往往不一致。为了本文的目的,我们需要一种一致的方式来比较数据模型和功能。
这里描述的所有系统都提供了一种存储标量值(如数字和字符串)以及BLOB(大对象)的方式。其中一些系统还提供了一种存储更复杂的嵌套或引用值的方法。所有这些系统都存储一组属性-值对,但使用不同的数据结构,具体如下:
元组
tuple:即关系表中的一行,其中属性名称在模式中预定义,且值必须是标量。值是通过属性名称引用的,这与通过位置序号引用的数组或列表不同。文档
document:允许值是嵌套的文档或列表,也可以是标量值,属性名称是在运行时为每个文档动态定义的。文档与元组的不同之处在于,属性没有在全局模式中定义,并且允许更广泛的值范围。可扩展记录
extensible record:是元组和文档之间的混合体,其中属性家族在模式中定义,但可以在每个记录的基础上添加新属性(在属性家族内)。属性可能是列表值。对象
object:类似于编程语言中的对象,但没有过程方法。值可以是引用或嵌套对象。
1.4 Data Store Categories
在本文中,数据存储根据其数据模型进行分类:
键值存储
Key-value Stores:这些系统基于程序员定义的键来存储值及其索引以进行查找。文档存储
Document Stores:这些系统存储文档,如前面所定义的。文档是可索引的,并提供简单的查询机制。可扩展记录存储
Extensible Record Stores:这些系统存储可扩展记录,可以在节点间进行垂直和水平分区。一些论文将这些称为“宽列存储”。关系型数据库
Relational Databases:这些系统存储(并索引和查询)元组。本文涵盖了提供水平扩展的新型关系型数据库管理系统(RDBMS)。
这四类数据存储将在接下来的四个部分中分别介绍。随后,我们将对这些系统进行总结和比较。
2. KEY-VALUE STORES
最简单的数据存储使用的模型类似于流行的memcached分布式内存缓存distributed in-memory cache,对所有数据只有一个键值索引。我们称这些系统为键值存储。与memcached不同,这些系统通常还提供持久化机制和其他附加功能,例如:复制、版本控制、锁定、事务、排序和/或其他功能。客户端接口提供插入、删除和索引查找功能。与memcached一样,这些系统都不提供二级索引或键。
2.1 Project Voldemort
Project Voldemort 是一个高级键值存储系统,由Java编写。它是开源的,并得到了LinkedIn的大量贡献。Voldemort 为更新操作提供了多版本并发控制(MVCC)。它以异步方式更新副本,因此不保证数据的一致性。然而,如果读取大多数副本,则可以保证数据是最新的。
Voldemort 支持一致性多记录更新的乐观锁定:如果更新与任何其他进程冲突,则可以回退。Dynamo [3]中使用的向量时钟提供了版本的排序。您还可以为put和delete操作指定要更新的版本。
Voldemort 支持数据的自动分片。通过一致性哈希将数据分布在节点环上:散列到节点K的数据会在节点K+1到K+n上复制,其中n是所需的额外副本数量(通常n=1)。使用良好的分片技术,“虚拟”节点的数量应远多于物理节点(服务器)。一旦数据分区设置完成,其操作是透明的。可以将节点添加或移除数据库集群,系统会自动适应。Voldemort 可以自动检测并恢复失败的节点。
Voldemort 可以将数据存储在RAM中,但也允许插入存储引擎。特别是,它支持Berkeley DB和随机访问文件存储引擎。除了简单的标量值,Voldemort 还支持列表和记录。
2.2 Riak
Riak 是由 Basho 于2009年年中开源的,使用 Erlang 编写。Basho 交替将 Riak 描述为“键值存储”和“文档存储”。在此,我们将其归类为一个高级键值存储,因为它缺乏文档存储的重要特性,但它(和 Voldemort)比其他键值存储具有更多的功能:
Riak 对象可以以 JSON 格式获取和存储,因此可以具有多个字段(类似于文档),并且对象可以分组到桶中,类似于文档存储所支持的集合,每个桶可以定义允许/必须的字段。
Riak 不支持除主键外的任何字段的索引。对于非主键字段,唯一可以做的操作是将它们作为 JSON 对象的一部分进行获取和存储。Riak 缺少文档存储的查询机制;唯一可以进行的查找是主键查找。
Riak 支持对象的复制和通过主键哈希的分片。它允许副本值暂时不一致。通过指定成功读取所需的响应副本数量和成功写入所需的响应副本数量,可以调整一致性。这是针对每个读取和每个写入操作的,因此应用程序的不同部分可以选择不同的权衡方式。
与 Voldemort 一样,Riak 使用一种MVCC(多版本并发控制)的衍生方式,当更新值时会分配向量时钟。向量时钟可用于确定对象何时是彼此的直接后代或共同父对象,因此Riak经常能够自我修复它发现不同步的数据。
Riak 的架构是对称且简单的。和 Voldemort 一样,它使用一致性哈希。系统中没有专门节点来跟踪状态:节点使用一种称为“gossip”的协议来跟踪哪些节点处于活动状态以及谁拥有哪些数据,并且任何节点都可以服务客户端请求。Riak 还包括一种map/reduce机制,可以在集群中的所有节点上分配工作。
Riak 的客户端接口基于 RESTful HTTP 请求。REST(表述性状态转移)使用统一的、无状态的、可缓存的客户端-服务器调用。此外,还提供了适用于 Erlang、Java 及其他语言的编程接口。
Riak 的存储部分是“可插拔”的:键值对可以存储在内存中、ETS 表、DETS 表或 Osmos 表中。ETS、DETS 和 Osmos 表均在 Erlang 中实现,具有不同的性能和特性。
Riak 的一个独特特性是它可以在对象(文档)之间存储“链接”,例如将作者对象链接到他们所写书籍的对象。链接减少了对二级索引的需求,但仍然无法进行范围查询。
以下是一个用 JSON 描述的 Riak 对象示例:
{
"bucket": "customers",
"key": "12345",
"object": {
"name": "Mr. Smith",
"phone": "415-555-6524"
},
"links": [
["sales", "Mr. Salesguy", "salesrep"],
["cust-orders", "12345", "orders"]
],
"vclock": "opaque-riak-vclock",
"lastmod": "Mon, 03 Aug 2009 18:49:42 GMT"
}请注意,主键是突出的,而其他字段是object部分的一部分。此外,还指定了桶、向量时钟和修改日期作为对象的一部分,并支持与其他对象的链接。
2.3 Redis
Redis 是一个键值数据存储系统,最初是由一个人开发的项目,但现在已经有多个贡献者参与,并作为BSD许可证的开源项目发布。它使用C语言编写。
Redis 服务器通过一种由各种客户端库实现的线协议访问(当协议更改时,这些库必须更新)。客户端在服务器之间进行分布式哈希。服务器在RAM中存储数据,但数据可以复制到磁盘以进行备份或系统关闭。添加更多节点时可能需要进行系统关闭。
与其他键值存储类似,Redis 实现了插入、删除和查找操作。与Voldemort类似,它允许将列表和集合与键关联,而不仅仅是Blob或字符串。它还包括列表和集合操作。
Redis 通过锁定来执行原子更新,并进行异步复制。据报道,它在一台8核服务器上支持每秒约100,000次的获取/设置操作。
[NOTE!]
果然是10年前的文章,redis目前通过哈希环可以非常轻松的对集群进行扩缩了,而不是关闭系统来保证一致性。
2.4 Scalaris
Scalaris 在功能上与 Redis 类似。它是由柏林的祖斯研究所使用 Erlang 编写的,并且是开源的。在将数据分布到节点时,它允许将键范围分配给节点,而不仅仅是简单地将键散列到节点。这意味着对一个值范围的查询不需要访问每个节点,这也可能根据键的分布实现更好的负载平衡。
与其他键值存储一样,Scalaris 支持插入、删除和查找操作。它以同步方式进行复制(在操作完成之前必须更新所有副本),因此数据的一致性是有保证的。Scalaris 还支持具有ACID属性的多对象事务。数据存储在内存中,但通过节点故障的复制和恢复机制来确保更新的持久性。然而,如果发生多节点断电,将导致灾难性的数据丢失,同时虚拟内存限制设定了数据库的最大容量。
在 Scalaris 中,读取和写入操作必须在多数副本上完成后才算操作结束。Scalaris 使用节点环,这是一种不寻常的数据分布和复制策略,需要通过对数(N)次跳跃才能读取或写入一个键值对。
2.5 Tokyo Cabinet
Tokyo Cabinet/Tokyo Tyrant 最初是一个 sourceforge.net 项目,现在由 FAL Labs 授权并维护。Tokyo Cabinet 是后端服务器,Tokyo Tyrant 是用于远程访问的客户端库。两者都用 C 语言编写。
Tokyo Cabinet 服务器有六种不同的变体:内存或磁盘上的哈希索引、内存或磁盘上的B树、固定大小记录表和可变长度记录表。这些引擎在性能特征上显然有所不同,例如固定长度记录允许快速查找。尽管这些引擎支持的 API 略有差异,但它们都支持常见的获取、设置和更新操作。文档有些不清晰,但它们声称支持锁定、ACID 事务、二进制数组数据类型,以及更复杂的更新操作以原子方式更新数字或连接字符串。它们支持主从复制或双主异步复制。节点故障的恢复是手动的,并且不支持自动分片。
2.6 Memcached, Membrain, 和 Membase
开源的 memcached 分布式内存索引系统已经通过 Schooner Technologies 和 Membase 进行了增强,新增了类似其他键值存储的功能:持久性、复制、高可用性、动态扩展、备份等。在没有持久性或复制功能的情况下,memcached 实际上不能算作“数据存储”。然而,Membrain 和 Membase 确实符合这个定义,并且这些系统也与现有的 memcached 应用程序兼容。这种兼容性是一个吸引人的特性,因为 memcached 被广泛使用;需要更高级功能的 memcached 用户可以轻松升级到 Membase 和 Membrain。
Membase 系统是开源的,由 Membase 公司支持。它最具吸引力的功能可能是能够在运行系统中弹性地添加或移除服务器,同时移动数据并动态重定向请求。相比之下,大多数其他系统在弹性方面不如 Membase 方便。
Membrain 是按服务器授权的,由 Schooner Technologies 提供支持。它最具吸引力的功能可能是其对闪存的出色优化。通过将闪存作为更快的硬盘使用,其他系统无法获得闪存的性能提升;重要的是,系统应将闪存视为真正的“第三层”,不同于 RAM 和硬盘。例如,许多系统在缓冲和缓存硬盘页面时存在大量开销,而在使用闪存时这种开销是没有必要的。Schooner 的网站上发布的基准测试结果显示,与一些竞争对手相比,特别是在数据溢出 RAM 的情况下,性能提高了许多倍。
2.7 Summary
所有的键值存储系统都支持插入、删除和查找操作。这些系统都通过在节点之间分布键来实现可扩展性。
Voldemort、Riak、Tokyo Cabinet 和增强型 memcached 系统可以将数据存储在 RAM 或磁盘上,并支持存储扩展。其他系统将数据存储在 RAM 中,并将磁盘作为备份,或依赖于复制和恢复机制,因此不需要备份。
Scalaris 和增强型 memcached 系统使用同步复制,而其他系统使用异步复制。
Scalaris 和 Tokyo Cabinet 实现了事务支持,而其他系统没有。
Voldemort 和 Riak 使用多版本并发控制(MVCC),而其他系统使用锁机制。
Membrain 和 Membase 基于流行的 memcached 系统构建,增加了持久性、复制和其他功能。与 memcached 的向后兼容性为这些产品带来了优势。
3. DOCUMENT STORE
正如第一部分讨论的那样,文档存储支持比键值存储更复杂的数据。文档存储这个术语可能会让人困惑:虽然这些系统确实可以存储传统意义上的“文档”(如文章、Microsoft Word文件等),但在这些系统中,文档可以是任何类型的“无指针对象”,这与我们在第一部分中的定义一致。与键值存储不同,这些系统通常支持二级索引和每个数据库中的多种类型的文档(对象),以及嵌套文档或列表。与其他NoSQL系统类似,文档存储不提供ACID事务属性。
3.1 SimpleDB
SimpleDB 是亚马逊的专有云计算服务的一部分,与其弹性计算云(EC2)和基于其简单存储服务(S3)的 SimpleDB 一同推出。SimpleDB 自2007年起开始使用。顾名思义,它的模型非常简单:SimpleDB 对文档提供选择(Select)、删除(Delete)、获取属性(GetAttributes)和设置属性(PutAttributes)操作。与其他文档存储不同,SimpleDB 不允许嵌套文档nested documents,因此比其他文档存储更简单。
像我们讨论的大多数系统一样,SimpleDB 支持最终一致性,而非事务一致性。它也像大多数其他系统一样,进行异步复制。
与键值数据存储不同,也与其他文档存储类似,SimpleDB 支持在一个数据库中进行多重分组:文档被放入域(domains)中,每个域支持多个索引。用户可以枚举域及其元数据。选择(Select)操作在一个域上执行,基本上采用如下形式,指定对属性的约束条件的合取:
select <attributes> from <domain> where <list of attribute value constraints>不同的域可能存储在不同的亚马逊节点上。
当任何文档的属性被修改时,域索引会自动更新。根据文档,不清楚 SimpleDB 是否会自动选择要索引的属性,或者是否索引所有属性。在任何情况下,用户都无法做出选择,索引的使用在 SimpleDB 查询处理中是自动进行的。
SimpleDB 不会自动将数据分区到多个服务器上。如果不在意获取最新版本,可以通过读取任意副本来实现一定程度的水平扩展。但是,写操作无法扩展,因为它们必须异步发送到域的所有副本。如果用户需要更好的扩展性,则必须手动进行分片。
SimpleDB 是亚马逊提供的“按需付费”专有解决方案。它目前有一些内置的限制,有些限制相当苛刻:最大域大小为10 GB、最多支持100个活跃域、查询时间限制为5秒等。亚马逊不允许在自己的服务器上运行 SimpleDB 的源代码或二进制代码。SimpleDB 的优势在于亚马逊提供的支持和文档。
3.2 CouchDB
CouchDB 自2008年初成为 Apache 项目以来一直在开发。它使用 Erlang 编写。
CouchDB 的文档“集合”类似于 SimpleDB 的域,但 CouchDB 的数据模型更为丰富。集合是 CouchDB 中唯一的模式,必须在集合中的字段上显式创建二级索引。文档的字段值可以是标量(文本、数值或布尔值)或复合(文档或列表)。
查询是通过 CouchDB 所谓的“视图”完成的,视图使用 JavaScript 定义,用于指定字段约束。索引是 B 树,因此查询结果可以按顺序排列或按值范围显示。查询可以使用 map-reduce 机制并行分布在多个节点上。然而,CouchDB 的视图机制比声明性查询语言对程序员的要求更高。
与 SimpleDB 类似,CouchDB 通过异步复制来实现可扩展性,而不是通过分片。如果不在意获取最新的值,读取可以访问任何服务器,而更新必须传播到所有服务器。然而,一个名为 CouchDB Lounge 的新项目已被构建,用于在 CouchDB 之上提供分片功能,详情见: http://code.google.com/p/couchdb-lounge/
与 SimpleDB 类似,CouchDB 不保证一致性。但与 SimpleDB 不同的是,每个客户端都能看到数据库的一致视图,并且具有可重复读取的特性:CouchDB 对单个文档实现了多版本并发控制(MVCC),每个文档版本都会自动创建一个序列 ID。如果在文档被提取后有人更新了它,CouchDB 会通知应用程序。应用程序可以尝试合并这些更新,也可以重试其更新并覆盖旧版本。
CouchDB 还提供系统崩溃时的持久性。所有更新(文档和索引)在提交时都会通过将数据写入文件的末尾刷新到磁盘。(这意味着需要定期进行压缩。)默认情况下,它在每次文档更新后都会刷新到磁盘。结合 MVCC 机制,CouchDB 的持久性在文档级别提供了 ACID 语义。
客户端通过 RESTful 接口调用 CouchDB。它为多种语言(如 Java、C、PHP、Python、LISP 等)提供了库,这些库可以将本地 API 调用转换为 RESTful 调用。此外,CouchDB 还提供了一些基本的数据库管理功能。
3.3 MongoDB
MongoDB 是一个 GPL 开源的文档存储系统,由 C++ 编写,受 10代版本 支持。它与 CouchDB 有一些相似之处:提供集合上的索引,无锁操作,并提供文档查询机制。然而,它们之间也存在一些重要差异:
MongoDB支持自动分片,将文档分布在多个服务器上。MongoDB中的复制主要用于故障转移,而不像CouchDB那样用于(脏读)扩展性。MongoDB不提供传统 DBMS 的全局一致性,但可以在文档的最新主副本上实现局部一致性。MongoDB支持动态查询,并自动使用索引,类似于关系型数据库管理系统(RDBMS)。在CouchDB中,数据是通过编写 map-reduce 视图来进行索引和搜索的。CouchDB在文档上提供多版本并发控制(MVCC),而MongoDB提供字段级的原子操作。
MongoDB 提供字段级原子操作,如下:
update命令支持“修改器”,用于对单个值进行原子更改:$set设置一个值,$inc增加一个值,$push将一个值追加到数组,$pushAll将多个值追加到数组,$pull从数组中删除一个值,$pullAll删除多个值。由于这些更新通常是“就地”发生的,因此避免了返回服务器的开销。使用“更新如果当前”约定来仅在字段值与给定的先前值匹配时更改文档。
MongoDB支持findAndModify命令,可以执行原子更新并立即返回更新后的文档。这对于实现需要原子性的队列和其他数据结构非常有用。
MongoDB 的索引通过 ensureIndex 调用显式定义,任何现有的索引都将自动用于查询处理。要查找去年发布且价格低于100美元的所有产品,可以编写如下查询:
db.products.find(
{released: {$gte: new Date(2009, 1, 1)},
price: {$lte: 100}})如果在查询的字段上定义了索引,MongoDB 将自动使用它们。MongoDB 还支持 map-reduce,以实现跨文档的复杂聚合。
MongoDB 使用一种类似二进制 JSON 的格式存储数据,称为 BSON。BSON 支持布尔型、整数、浮点数、日期、字符串和二进制类型。客户端驱动程序将本地语言的文档数据结构(通常是字典或关联数组)编码为 BSON,并通过套接字连接发送到 MongoDB 服务器(与 CouchDB 通过 HTTP REST 接口以文本形式发送 JSON 相对比)。MongoDB 还支持用于大二进制对象(如图像和视频)的 GridFS 规范。这些对象以块的形式存储,可以流式传输回客户端,以实现高效传输。
MongoDB 支持主从复制,具有自动故障转移和恢复功能。复制(和恢复)是在分片级别完成的。集合通过用户定义的分片键自动分片。复制是异步的,以获得更高的性能,因此在崩溃时某些更新可能会丢失。
3.4 Terrastore
Terrastore 是另一个较新的文档存储系统,基于 Terracotta 分布式 Java 虚拟机集群产品构建。像许多其他 NoSQL 系统一样,Terrastore 的客户端访问基于 HTTP 操作来获取和存储数据。Java 和 Python 客户端 API 也已经实现。
Terrastore 会自动将数据分区到服务器节点上,并且可以在添加或移除服务器时自动重新分配数据。与 MongoDB 类似,它可以基于谓词执行查询,包括范围查询;与 CouchDB 类似,它包含用于更高级的数据选择和聚合的 map/reduce 机制。
与其他文档数据库一样,Terrastore 是无模式的,不提供 ACID 事务支持。与 MongoDB 相似,它在每个文档的基础上提供一致性:读取操作将始终获取文档的最新版本。
Terrastore 支持复制和切换到热备用服务器的故障转移。
3.5 Summary
除了属性(仅是一个名称,未预先指定)、集合(仅是文档的分组)以及集合上定义的索引(显式定义,SimpleDB 除外)外,文档存储是无模式的。它们的数据模型存在一些差异,例如 SimpleDB 不允许嵌套文档。
这些文档存储非常相似,但使用了不同的术语。例如,SimpleDB 的域(Domain)= CouchDB 的数据库(Database)= MongoDB 的集合(Collection)= Terrastore 的桶(Bucket)。SimpleDB 将文档称为“项目”(items),而 CouchDB 中的属性是一个字段,MongoDB 或 Terrastore 中的属性是一个键。
与键值存储不同,文档存储提供了一种基于多个属性值约束来查询集合的机制。然而,CouchDB 不支持非过程化的查询语言:这对程序员提出了更多的工作要求,并需要显式地利用索引。
文档存储通常不提供显式锁定,其并发性和原子性特性比传统的符合 ACID 标准的数据库要弱。它们在提供的并发控制程度上有所不同。
所有系统都可以将文档分布到多个节点上,但可扩展性有所不同。所有系统都可以通过读取(可能)过期的副本来实现可扩展性。MongoDB 和 Terrastore 可以在不妥协的情况下获得可扩展性,并且可以通过自动分片和文档的原子操作扩展写操作。CouchDB 可能在新的 CouchDB Lounge 代码的帮助下实现这种写操作的可扩展性。
在本文发表前的最后时刻补充说明:CouchDB 和 Membase 公司现已合并,形成 Couchbase。他们计划将各自产品的“最佳特性”进行合并,例如 CouchDB 更丰富的数据模型,以及 Membase 的速度和弹性可扩展性。详情请参阅 Couchbase.com。
4. EXTENSIBLE RECORD STORES
可扩展记录存储
可扩展记录存储似乎是受到了 Google 成功推出 BigTable 的启发。其基本数据模型是行和列,其基本的可扩展性模型是将行和列都拆分到多个节点上:
行通过对主键进行分片而分布在多个节点上。通常采用范围
range分片而不是哈希hash函数分片。这意味着对值范围的查询不必访问每个节点。表的列通过使用列组
column groups分布在多个节点上。这似乎增加了新的复杂性,但实际上,列组只是客户指示哪些列最好存储在一起的一种方式。
如前所述,这两种分区(水平和垂直)可以同时用于同一个表。例如,如果一个客户表被划分为三个列组(例如,将客户姓名/地址与财务信息和登录信息分开),则每个列组在按客户 ID 对行进行分片时会被视为一个独立的表:同一个客户的列组可能在同一个服务器上,也可能不在同一服务器上。
在可扩展记录存储中,列组必须预先定义。然而,这并不是一个大的限制,因为可以随时定义新属性。行类似于文档:它们可以具有可变数量的属性(字段),属性名称必须唯一,行被分组到集合(表)中,并且单个行的属性可以是任何类型。(但是请注意,CouchDB 和 MongoDB 支持嵌套对象,而可扩展记录存储通常只支持标量类型。)
尽管大多数可扩展记录存储系统都是以 BigTable 为蓝本,但目前看来没有任何可扩展记录存储系统的可扩展性接近 BigTable 的水平。BigTable 用于多种用途(例如,Google 提供的许多服务,而不仅仅是网络搜索)。值得阅读 BigTable 论文【1】以了解可扩展性挑战的背景。
[NOTE!]
经典的google三件套,bigtable, Google-GFS, MapReduce.
当前的大数据时代就是这三篇论文引爆的
4.1 HBase
HBase 是一个由 Java 编写的 Apache 项目,其设计直接借鉴了 BigTable:
HBase 使用 Hadoop 分布式文件系统替代 Google 文件系统。它将更新放入内存中,并定期将其写入磁盘上的文件。
更新操作会写入数据文件的末尾,以避免磁盘寻道。文件会定期压缩。更新还会被写入预写日志(Write Ahead Log)的末尾,以便在服务器崩溃时进行恢复。
行操作是原子的,具有行级锁定和事务支持。HBase 提供可选的更广范围事务支持,这些事务使用乐观并发控制,如果与其他更新发生冲突,则中止。
分区和数据分布是透明的,不像某些 NoSQL 系统那样需要客户端哈希或固定键空间。HBase 支持多主模式,避免单点故障。MapReduce 支持使得操作可以高效分布。
HBase 的日志结构合并文件索引支持快速范围查询和排序。
提供了 Java API、Thrift API 和 REST API,并最近添加了 JDBC/ODBC 支持。
HBase 的初始原型于 2007 年 2 月发布。其对事务的支持在 NoSQL 系统中非常具有吸引力且不常见。
4.2 HyperTable
HyperTable 是一个用 C++ 编写的项目,由 Zvents 开源。虽然其受欢迎程度还没有明显提升,但百度成为该项目的赞助商,这应有助于其推广。
HyperTable 与 HBase 和 BigTable 非常相似。它使用可以具有任意数量“列限定符”的列族,并在数据上使用 MVCC(多版本并发控制)的时间戳。它需要一个底层的分布式文件系统(如 Hadoop)和一个分布式锁管理器。表根据键范围在服务器上进行复制和分区。更新在内存中进行,然后刷新到磁盘。
HyperTable 支持多种编程语言的客户端接口,并使用名为 HQL 的查询语言。
4.3 Cassandra
Cassandra 在其数据模型和基本功能上与其他可扩展记录存储类似。它有列组,更新会缓存在内存中然后刷新到磁盘,磁盘表示会定期压缩。它也支持分区和复制。故障检测和恢复完全是自动的。然而,Cassandra 的并发模型比其他一些系统更弱:没有锁定机制,副本是异步更新的。
Cassandra 与 HBase 一样,用 Java 编写,并在 Apache 许可下使用。由 DataStax 提供支持,最初由 Facebook 在 2008 年开源。它由一名 Facebook 工程师和一名 Dynamo 工程师设计,被描述为 Dynamo 和 BigTable 的结合体。Cassandra 被 Facebook 及其他公司使用,因此代码相对成熟。
客户端接口是使用 Facebook 的 Thrift 框架创建的: http://incubator.apache.org/thrift/
Cassandra 自动将新可用的节点加入集群,使用 phi 累积算法检测节点故障,并使用类似 gossip(八卦)的算法以分布式方式确定集群成员身份。Cassandra 增加了“超级列”的概念,为列组内的分组提供了另一个层次。数据库(称为 keyspaces)包含列族。一个列族包含超级列或列(不混合两者)。超级列包含列。与其他系统一样,任何行可以具有任何列值组合(即,行是可变长度的,不受表模式限制)。
Cassandra 使用有序哈希索引,这应该能够提供哈希和 B 树索引的大部分优势:你可以知道哪些节点可能包含某个特定值范围,而不需要搜索所有节点。然而,排序仍然会比 B 树慢。
据报道,Cassandra 在 Facebook 的生产环境中已扩展到大约 150 台机器,现在可能更多。作为一个开源项目,Cassandra 似乎也在获得很大的推动力。
对于 Cassandra 的最终一致性模型不足的应用场景,“法定读取”大多数副本的方法提供了一种获取最新数据的方式。Cassandra 的写操作在列族内是原子的。它还支持版本控制和冲突解决。
4.4 Other Systems
雅虎的 PNUTs 系统也属于“可扩展记录存储”类别。然而,它不在本文的评论范围内,因为它目前仅在雅虎内部使用。我们也没有评审 BigTable,尽管其功能可以通过 Google Apps 间接获得。PNUTs 和 BigTable 都包含在本文末的对比表中。
4.5 Summary
可扩展记录存储大多以 BigTable 为蓝本。它们彼此相似,但在并发机制和其他特性上有所不同。
Cassandra 注重“弱”并发(通过多版本并发控制,MVCC),而 HBase 和 HyperTable 则强调“强”一致性(通过锁定和日志记录)。
5. SCALABLE RELATIONAL SYSTEMS
与其他数据存储不同,关系型数据库管理系统(RDBMS)具有完整的预定义模式、SQL 接口和 ACID 事务。传统上,RDBMS 的可扩展性不如前面描述的一些数据存储系统。大约五年前,MySQL Cluster 看起来最具可扩展性,但与标准的 MySQL 相比,其每个节点的性能并不高。
最近的进展正在改变这种情况。MySQL Cluster 的性能进一步提高,同时出现了几款新产品,特别是 VoltDB 和 Clustrix,它们承诺在每个节点上都具有良好的性能和可扩展性。看起来某些关系型 DBMS 将提供与 NoSQL 数据存储相当的可扩展性,但有两个前提条件:
使用小范围操作:正如我们提到的,跨越多个节点的操作(例如在多个表上进行的连接操作)在分片情况下的扩展性不佳。
使用小范围事务:同样,跨多个节点的事务将非常低效,因为需要通信和两阶段提交的开销。
需要注意的是,NoSQL 系统通过使执行大范围操作和事务变得困难或不可能,从而避免了这两个问题。相反,一个可扩展的 RDBMS 并不需要排除大范围的操作和事务:如果用户使用这些操作,它们只是在这种情况下对用户进行惩罚。因此,可扩展的 RDBMS 相较于 NoSQL 数据存储具有优势,因为它提供了高级 SQL 语言和 ACID 属性的便利性,并且仅在这些操作跨节点时才会有性能代价。因此,本文将可扩展的 RDBMS 作为一种可行的替代方案进行讨论。
[NOTE!]
从这段上看,mysql是分布式数据库的先行者,postgresql是后来居上而已。
在项目开发和商业策略看,跟随战术往往更为成功。:D
5.1 MySQL Cluster
MySQL Cluster 自 2004 年起成为 MySQL 发布版的一部分,其代码源自爱立信更早的一个项目。MySQL Cluster 通过用名为 NDB 的分布式层替换 InnoDB 引擎来工作。它由 MySQL(现为 Oracle)提供,并且是开源的。一个专有的 MySQL Cluster Carrier Grade 升级提供了管理和自动化管理功能。
MySQL Cluster 采用了“无共享”架构,将数据分片到多个数据库服务器上。每个分片都有备份,以支持恢复。它还支持双向地理复制。
MySQL Cluster 支持内存和基于磁盘的数据存储。内存存储允许实时响应。
尽管 MySQL Cluster 目前似乎能够扩展到比其他 RDBMS 更多的节点,但据报道在几十个节点后会遇到瓶颈。MySQL Cluster 的开发工作仍在继续,因此这种情况可能会有所改进。
5.2 VoltDB
VoltDB 是一个新型的开源 RDBMS,旨在提供高性能(每节点)以及可扩展性。
其可扩展性和可用性特性与 MySQL Cluster 以及本文中的 NoSQL 系统具有竞争力:
表被分区到多个服务器上,客户端可以调用任意服务器。对于 SQL 用户来说,分布是透明的,但客户可以选择分片属性。
或者,某些选定的表可以在服务器上复制,例如用于快速访问主要为读取的数据。
无论如何,分片都会被复制,以便在节点崩溃时可以恢复数据。还支持数据库快照(连续或定期)。
目前有些功能仍然缺失,例如在线模式更改有限,异步广域网复制和恢复尚未实现。然而,VoltDB 具有一些有前景的特性,这些特性可能在单节点性能上带来数量级的优势。VoltDB 消除了 SQL 执行中的几乎所有“等待”,从而实现了非常高效的实现:
系统设计用于适合服务器上(分布式)RAM 的数据库,因此系统无需等待磁盘。索引和记录结构是为 RAM 而设计的,而不是磁盘,磁盘缓存/缓冲的开销也被消除了。如果虚拟内存超出 RAM,则性能会非常差,但通过合理的 RAM 容量规划可以获得显著的增益。
每个分片的 SQL 执行是单线程的,使用无共享架构,因此不存在多线程锁定的开销。
所有 SQL 调用都是通过存储过程完成的,每个存储过程都是一个事务。这意味着,如果数据被分片以允许在单个节点上执行事务,则不需要锁,因此也没有锁等待。事务协调也被避免了。
存储过程被编译成可与 NoSQL 系统的访问级别调用相媲美的代码。它们可以在一个节点和副本节点上以相同的顺序执行。
VoltDB 认为这些优化大大减少了支持给定应用负载所需的节点数量,同时对数据库设计的限制适中。它们已经在其网站上报告了一些令人印象深刻的基准测试结果。当然,最高性能要求数据库工作集适合分布式 RAM,或可能扩展到 SSD。有关 VoltDB 和类似系统架构问题的更多讨论,请参阅【5】。
5.3 Clustrix
Clustrix 提供的产品与 VoltDB 和 MySQL Cluster 类似,但 Clustrix 节点作为机架安装设备出售。他们声称可扩展到数百个节点,具有自动分片和复制(在 4:1 读/写比率下,20 个节点上达到 350K TPS 和 1.6 亿行)。故障转移是自动的,节点故障恢复也是自动的。他们还使用固态硬盘来提高性能(类似于 Schooner 的 MySQL 和 NoSQL 设备)。
与其他关系型产品一样,Clustrix 支持完全符合 ACID 的 SQL 事务。数据分布和负载均衡对应用程序开发者是透明的。有趣的是,他们还设计了与 MySQL 的无缝兼容性,支持现有的 MySQL 应用程序和前端连接器。这可能会在采用专有硬件方面给他们带来很大优势。
5.4 ScaleDB
ScaleDB 是一个正在开发的 MySQL 新衍生版本。与 MySQL Cluster 类似,它替换了 InnoDB 引擎,并使用多服务器集群来实现可扩展性。ScaleDB 的不同之处在于它要求跨节点共享磁盘。每个服务器必须能够访问每个磁盘。然而,这种架构在 Oracle RAC 上并未表现出良好的可扩展性。
ScaleDB 的分片是自动的:可以随时添加更多服务器。服务器故障处理也是自动的。ScaleDB 将负载重新分配到现有服务器。
ScaleDB 支持 ACID 事务和行级锁定。它具有多表索引(这是由于共享磁盘而成为可能的)。
5.5 ScaleBase
ScaleBase 采用了一种新颖的方法,试图通过完全基于 MySQL 之上的层来实现水平扩展,而不是修改 MySQL。ScaleBase 包含一个部分 SQL 解析器和优化器,将表分片到多个单节点 MySQL 数据库上。截至本文撰写时,关于这个新系统的信息有限。它目前是一个商业产品的测试版,不是开源的。
将分片作为 MySQL 之上的一层引入带来了一个问题,因为事务无法跨 MySQL 数据库。ScaleBase 提供了一个分布式事务协调选项,但高性能选项仅在单个分片/服务器内提供 ACID 事务。
5.6 NimbusDB
NimbusDB 是另一个新的关系型系统。它使用 MVCC 和基于分布式对象的存储。SQL 是访问语言,具有面向行的查询优化器和 AVL 树索引。
MVCC 提供了无需锁定的事务隔离,允许大规模并行处理。数据按行逐行水平分割为分布式对象,允许多站点、动态分布。
5.7 Other System
Google 最近在 BigTable 之上创建了一个名为 Megastore 的层。Megastore 增加了许多功能,使 BigTable 在许多方面更接近(可扩展的)关系型 DBMS:跨节点的事务、用类似 SQL 的语言定义的数据库模式,以及允许某种有限连接能力的层次路径。Google 还实现了一个在 BigTable 上运行的 SQL 处理器。尽管 Megastore/BigTable "NoSQL" 和可扩展的关系型系统之间仍然存在许多差异,但差距似乎正在缩小。
Microsoft 的 Azure Tables 产品使用分区键、行键和时间戳为读取和写入提供水平扩展。表存储在“云”中,可以同步多个数据库。没有固定的模式:行由属性-值对列表组成。由于本文原版的时间限制,Azure 未在此处涵盖。
主要的 RDBMS(DB2、Oracle、SQL Server)也包含了一些水平扩展功能,既有无共享,也有共享磁盘架构。
5.8 Summary
MySQL Cluster 使用“无共享”架构来实现可扩展性,与本节中的大多数其他解决方案一样,并且它是这里最成熟的解决方案。
VoltDB 看起来很有前途,因为它具有水平扩展性以及自下而上的重新设计,以提供非常高的每节点性能。Clustrix 也看起来很有前景,支持固态硬盘,但它基于专有软件和硬件。
关于 ScaleDB、NimbusDB 和 ScaleBase 的信息有限;它们还处于早期阶段。
理论上,只要应用程序避免跨节点操作,RDBMS 应该能够实现可扩展性。如果这在实践中得到证明,那么 SQL 的简便性和 ACID 事务将使其在大多数应用程序中比 NoSQL 更具优势。
[NOTE!]
6. USE CASES
没有一个数据存储能适用于所有情况。用户对功能的优先级取决于应用程序的不同需求,以及所需的可扩展性类型。虽然全面的选择数据存储的指南超出了本文的范围,但在本节中,我们将探讨一些适合不同数据存储类别的应用示例。
[NOTE!]
博览众长,各取所长,这才是一个合格DBA的格局,厚此薄彼多更多的时候是政治手段而不是技术角度考虑问题。
6.1 Key-value Store Example
如果你的应用程序简单,只有一种对象类型,并且只需要基于一个属性查找对象,键值存储通常是一个不错的解决方案。键值存储的简单功能可能使其使用起来最为简便,特别是当你已经熟悉 memcached 时。
例如,假设你有一个 Web 应用程序,当用户登录时需要执行许多 RDBMS 查询来创建个性化页面。假设执行这些查询需要几秒钟,而用户的数据很少更改,或者你知道数据何时更改,因为更新通过相同的接口完成。那么,你可能希望将用户的个性化页面作为一个对象存储在键值存储中,以便在响应浏览器请求时以高效的方式发送,并通过用户 ID 为这些对象建立索引。如果你将这些对象持久化存储,那么你可以避免许多 RDBMS 查询,仅在用户数据更新时重构对象。
即使在像 Facebook 这样的应用中,用户的主页根据用户自己和其他人所做的更新而更改,也可以在用户登录时仅执行一次 RDBMS 查询,并在该会话的其余时间内仅显示该用户所做的更改(不显示其他用户的更改)。然后,一个简单的键值存储仍然可以用作关系数据库缓存。
你也可以通过创建自己维护的额外键值索引,使用键值存储基于多个属性进行查找。但是,此时你可能更需要转向文档存储。
6.2 Document Store Example
文档存储的一个良好应用示例是具有多种不同类型对象的应用程序(例如,在机动车辆管理局(DMV)的应用程序中,有车辆和驾驶员),并且你需要基于多个字段查找对象(例如,驾驶员姓名、驾照号码、所拥有的车辆或出生日期)。
一个重要的因素是你需要什么级别的并发保证。如果你可以容忍一个“最终一致性”模型,具有有限的原子性和隔离性,那么文档存储应该能很好地工作。这可能在 DMV 应用程序中是这样,例如,你不需要知道驾驶员在过去一分钟内是否有新的交通违规行为,并且两家 DMV 办公室同时更新同一驾驶员记录的可能性很小。但如果你要求数据是最新的且原子一致的,例如,如果你想在三次错误尝试后锁定登录,那么你需要考虑其他替代方案,或使用诸如仲裁读取(quorum-read)之类的机制来获取最新数据。
6.3 Extensible Record Store Example
可扩展记录存储的用例与文档存储类似:多种类型的对象,基于任意字段的查找。然而,可扩展记录存储项目通常针对更高的吞吐量,并可能在保证更强的并发性方面具有优势,但其复杂性稍高于文档存储。
假设你正在为一个类似 eBay 的应用程序存储客户信息,并希望对数据进行水平和垂直分区:
你可能希望按国家对客户进行集群,以便有效搜索一个国家内的所有客户。
你可能希望将很少更改的“核心”客户信息(如客户地址和电子邮件地址)放在一个地方,并将某些频繁更新的客户信息(如正在进行的当前出价)放在不同的地方,以提高性能。
虽然你可以在文档存储的基础上自己执行这种水平/垂直分区,通过为多个维度创建多个集合来实现,但使用像 HBase 或 HyperTable 这样的可扩展记录存储最容易实现这种分区。
6.4 Scalable RDBMS Example
关系型数据库管理系统的优点是众所周知的:
如果你的应用程序需要包含不同类型数据的许多表,关系模式定义可以集中并简化数据定义,而 SQL 大大简化了跨表操作的表达。
许多程序员已经熟悉 SQL,并且许多人认为使用 SQL 比 NoSQL 系统提供的低级命令更简单。
事务大大简化了并发访问的编码。ACID 语义使开发者无需处理锁定、过时数据、更新冲突和一致性问题。
目前有更多的工具可用于关系型 DBMS,用于报告生成、表单等。
一个关系型数据库的良好示例是更复杂的 DMV 应用程序,例如用于执法的查询接口,可以互动地搜索车辆颜色、制造商、型号、年份、部分车牌号,和/或对车主的约束(例如居住县、发色和性别)。ACID 事务也可能对一个从许多地点进行更新的数据库非常有用,前面提到的工具也会非常有价值。定义通用的关系模式和管理工具对于有许多程序员参与的项目也非常宝贵。
当然,这些优势依赖于关系型 DBMS 能够扩展以满足你的应用需求。最近关于 VoltDB、Clustrix 和最新版本的 MySQL Cluster 的基准测试结果表明,关系型 DBMS 的可扩展性在大幅提升。再次强调,这假设你的应用程序不要求跨越许多节点的更新或连接;那样的事务协调和数据移动成本会非常高。然而,NoSQL 系统通常不提供跨节点的事务或查询连接的可能性,因此在这方面你并没有什么损失。
7. CONCLUSIONS
本文讨论了二十多种可扩展的数据存储系统。几乎所有这些系统都是不断变化的目标,其文档有限且有时相互矛盾,因此本文在撰写时可能已经过时甚至不准确。然而,我们将在本节尝试提供一个快照总结、比较和预测。请将其视为进一步研究的起点。
7.1 Some Predictions
以下是关于未来几年我们讨论的系统可能会发生的事情的一些预测:
许多开发者愿意放弃全局 ACID 事务,以获得可扩展性、可用性和其他优势。NoSQL 系统的流行已经证明了这一点。用户可以容忍航空公司超售以及在订单完成前购物车中的商品售罄时订单被拒绝的情况。世界并不是全局一致的。
NoSQL 数据存储不会是“昙花一现”。这些系统的简单性、灵活性和可扩展性填补了市场空白,例如,适用于具有数百万读/写用户和相对简单数据模式的网站。即使关系型数据库的可扩展性得到了改善,NoSQL 系统在某些应用程序中仍具有优势。
新的关系型 DBMS 也将占据可扩展数据存储市场的重要份额。如果事务和查询通常限于单个节点,这些系统应该能够扩展【5】。在需要 SQL 或 ACID 事务的情况下,这些系统将是首选。
许多可扩展的数据存储系统暂时不会被证明“企业就绪”。即使它们满足需求,这些系统也是新的,还没有达到已有十多年历史的数据库产品的稳健性、功能和成熟度。早期用户已经看到了一些因可扩展数据存储故障而导致的网站中断,而许多大型网站仍然通过现有的 RDBMS 产品进行分片来构建自己的解决方案。不过,鉴于大量精力投入其中,其中一些新系统将迅速成熟。
我们描述的系统之间将发生重大整合。每个类别中可能只有一两个系统成为领导者。市场和开源社区不太可能支持本文研究的众多产品和项目。风险投资和关键参与者的支持可能是这种整合的一个因素。例如,在文档存储方面,MongoDB 今年获得了大量投资。
[NOTE!]
全部命中了,14年后再看,不得不叹服作者的眼光和格局!
7.2 SQL vs NoSQL
SQL(关系型)与 NoSQL 的可扩展性是一个有争议的话题。本文反对两个极端观点。以下是支持这种立场的一些背景信息。
支持关系型数据库优于 NoSQL 的论点如下:
如果新的关系型系统能够做到 NoSQL 系统能够做的一切,并且具有类似的性能和可扩展性,并且具有事务和 SQL 的便利性,为什么还要选择 NoSQL 系统?
在过去 30 年中,关系型 DBMS 一直占据并保持了大部分市场份额,相对于其他竞争者如网络型、对象型和 XML DBMS。
成功的关系型 DBMS 已经被构建用于处理其他特定的应用负载:只读或主要为读的数据仓库、多核多磁盘 CPU 上的 OLTP、内存数据库、分布式数据库,以及现在的水平扩展数据库。
虽然我们在 SQL 产品本身中没有看到“一刀切”,但我们确实看到了一个通用的接口,SQL、事务和关系模式在培训、连续性和数据交换方面具有优势。
支持 NoSQL 的反论点如下:
我们尚未看到有力的基准测试显示 RDBMS 能够实现与 NoSQL 系统(如 Google 的 BigTable)相当的扩展性。
如果你只需要基于单一键查找对象,那么键值存储是足够的,并且可能比关系型 DBMS 更容易理解。同样,对于简单应用程序上的文档存储,你只需为你所需的复杂性级别付出学习曲线。
某些应用程序需要一个灵活的模式,允许集合中的每个对象具有不同的属性。虽然某些 RDBMS 允许有效地“打包”缺少属性的元组,并允许在运行时添加新属性,但这种情况并不常见。
关系型 DBMS 使“昂贵”的(多节点多表)操作“过于容易”。NoSQL 系统使得这些操作对程序员来说是不可能或显而易见昂贵的。
尽管 RDBMS 多年来保持了主要市场份额,但其他产品在需要特定功能的领域(例如,带有 BerkeleyDB 产品的索引对象,或带有面向对象 DBMS 的图跟踪操作)中建立了较小但不容忽视的市场。
这两个论点的各自立场都有其合理性。
7.3 Benchmarking
鉴于可扩展性是本文及我们讨论的系统的焦点,在我们的分析中存在一个“巨大缺口”:缺乏用来证实许多可扩展性主张的基准测试。如我们所指出的,某些系统报告了基准测试结果,但几乎没有任何基准测试是在多个系统上运行的,并且这些结果通常是由该系统的支持者报告的,因此对其客观性总是存在疑问。
在本文中,我们尝试仅基于架构论证进行最佳比较。然而,非常希望获得一些有用的客观数据来比较这些架构:
架构之间的权衡
trade-offs不清楚。瓶颈bottlenecks是在磁盘访问、网络通信、索引操作、锁定还是其他组件?许多人希望看到新的关系型系统能否像 NoSQL 系统一样扩展的支持或反驳论点。
其中一些系统是新的,可能需要数年的调整才能实现可扩展性主张。它们也可能存在漏洞。哪些系统真正成熟?
哪些系统在哪些负载上表现最佳?开源项目能否产生高性能系统?
目前最好的基准测试可能来自 Yahoo! Research【2】,比较了 PNUTS、HBASE、Cassandra 和分片 MySQL。他们的基准测试,YCSB,被设计为代表 web 应用程序,代码可供他人使用。基准测试的第 1 层衡量原始性能,显示随着服务器负载增加的延迟特征。第 2 层测量扩展性,显示随着添加服务器系统的扩展能力,以及系统适应新服务器的速度。
在本文中,我想发出“可扩展性基准测试的呼吁”,建议 YCSB 作为比较的良好基础。即使 YCSB 基准测试由不同的团队运行,无法完全复制 Yahoo 指定的相同硬件,结果仍将具有信息性。
7.4 Some Comparisons
鉴于不断变化的环境,本文不试图论证特定系统的优劣,超出已提出的评论范围。然而,对显著特征的比较可能会有所帮助,因此我们以一些比较作为结束。
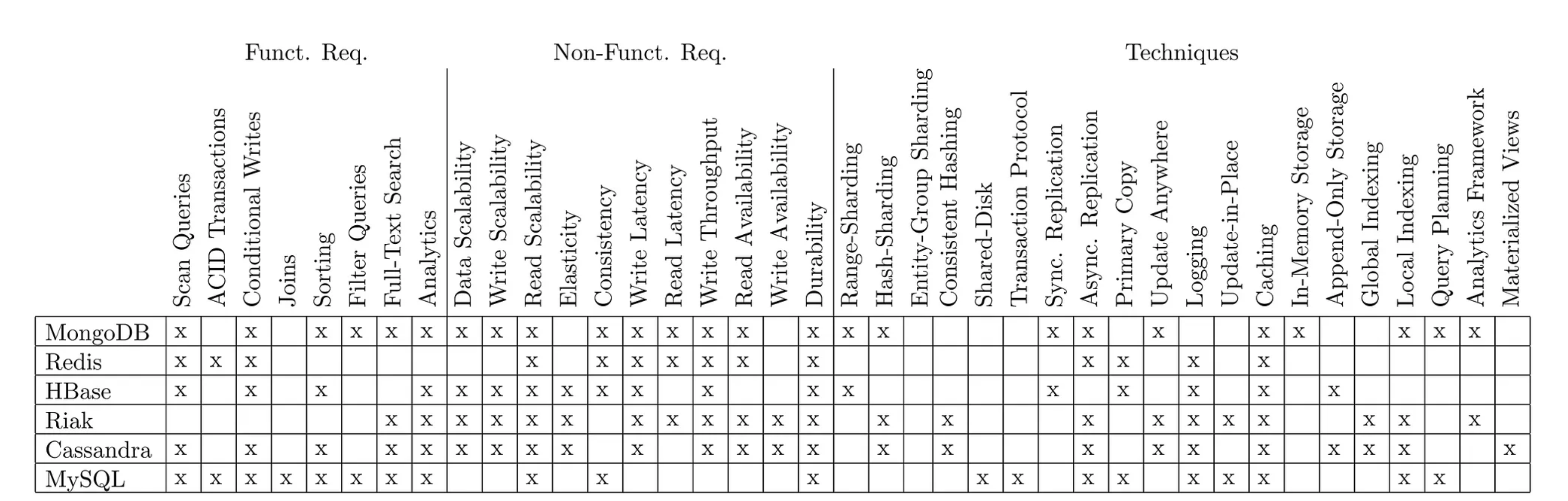
表 1 比较了这些系统的并发控制、数据存储介质、复制和事务机制。这些特征很难在简短的表格条目中概括而不过于简化,但我们进行了如下比较:
对于并发控制:concurrency
locking:某些系统提供了一种机制,允许一次只有一个用户读取或修改实体(对象、文档或行)。在 MongoDB 的情况下,提供了字段级别的锁定机制。
MVCC:某些系统提供多版本并发控制,保证数据库的读取一致视图,但如果多个用户同时修改同一实体,则会产生多个冲突版本。
None:某些系统不提供原子性,允许不同用户并行修改同一对象的不同部分,并且不能保证读取时获取的版本。
ACID:关系型系统提供 ACID 事务。一些较新的系统通过预分析事务来避免冲突,在无死锁和无锁等待的情况下实现这一点。
对于数据存储data storage,一些系统设计用于 RAM 存储,可能带有快照或复制到磁盘,而其他系统设计用于磁盘存储,可能在 RAM 中缓存。基于 RAM 的系统通常允许使用操作系统的虚拟内存,但当它们超出物理 RAM 时,性能显得非常差。一些系统具有可插拔的后端,允许使用不同的数据存储介质,或者要求使用标准化的底层文件系统。
复制replication可以确保镜像副本始终保持同步(即,它们是锁步更新的,直到两个副本都被修改后操作才算完成)。或者,镜像副本可以在后台异步更新。异步复制允许更快的操作,特别是对于远程副本,但在崩溃时可能会丢失一些更新。某些系统同步更新本地副本,并异步更新地理上远程的副本(这可能是远程数据的唯一实际解决方案)。
事务transaction在某些系统中受支持,而在其他系统中不受支持。一些 NoSQL 系统提供了介于两者之间的功能,其中“本地”事务仅在单个对象或分片内支持。
表 1 比较了这些系统在这四个维度上的特征。
Table 1. System Comparison (grouped by category)
System | Conc Control | Data Storage | Replication | Tx |
|---|---|---|---|---|
Redis | Locks | RAM | Async | N |
Scalaris | Locks | RAM | Sync | L |
Tokyo | Locks | RAM or disk | Async | L |
Voldemort | MVCC | RAM or BDB | Async | N |
Riak | MVCC | Plug-in | Async | N |
Membrain | Locks | Flash + Disk | Sync | L |
Membase | Locks | Disk | Sync | L |
Dynamo | MVCC | Plug-in | Async | N |
SimpleDB | None | S3 | Async | N |
MongoDB | Locks | Disk | Async | N |
CouchDB | MVCC | Disk | Async | N |
Terrastore | Locks | RAM+ | Sync | L |
HBase | Locks | Hadoop | Async | L |
HyperTable | Locks | Files | Sync | L |
Cassandra | MVCC | Disk | Async | L |
BigTable | Locks + stamps | GFS | Sync + Async | L |
PNUTs | MVCC | Disk | Async | L |
MySQL Cluster | ACID | Disk | Sync | Y |
VoltDB | ACID, no lock | RAM | Sync | Y |
Clustrix | ACID, no lock | Disk | Sync | Y |
ScaleDB | ACID | Disk | Sync | Y |
ScaleBase | ACID | Disk | Async | Y |
NimbusDB | ACID, no lock | Disk | Sync | Y |
另一个需要考虑的因素是代码的成熟度,这在表格中是无法客观量化的。正如前面提到的,许多我们讨论的系统只有几年历史,可能会不太可靠。因此,如果现有的数据库产品能够满足您的应用需求,它们通常是更好的选择。
最重要的因素可能是实际的性能和可扩展性,正如在基准测试讨论中所指出的那样。基准测试的参考信息将随着其可用性更新到作者的网站 cattell.net/datastores。本论文的更新和修正也将在该网站发布。未来两年内,可扩展数据存储的格局可能会发生重大变化!
8. 致谢
感谢 Len Shapiro、Jonathan Ellis、Dan DeMaggio、Kyle Banker、John Busch、Darpan Dinker、David Van Couvering、Peter Zaitsev、Steve Yen 和 Scott Jarr 对本文早期草稿的意见和建议。然而,本文的所有错误归我所有!此外,还要感谢 Schooner Technologies 对本文的支持。
9. 参考文献
F. Chang et al., “BigTable: A Distributed Storage System for Structured Data”, Seventh Symposium on Operating System Design and Implementation, November 2006.
B. Cooper et al., “Benchmarking Cloud Serving Systems with YCSB”, ACM Symposium on Cloud Computing (SoCC), Indianapolis, Indiana, June 2010.
B. DeCandia et al., “Dynamo: Amazon’s Highly Available Key-Value Store”, Proceedings of the 21st ACM SIGOPS Symposium on Operating Systems Principles, 2007.
S. Gilbert and N. Lynch, “Brewer’s Conjecture and the Feasibility of Consistent, Available, and Partition-Tolerant Web Services”, ACM SIGACT News 33, 2, pp 51-59, March 2002.
M. Stonebraker and R. Cattell, “Ten Rules for Scalable Performance in Simple Operation Datastores”, Communications of the ACM, June 2011.
10. 系统参考
以下表格提供了本文涉及的所有数据库管理系统和数据存储的网络信息来源,甚至包括那些只是边缘提及的系统,按系统名称的字母顺序排列。表格还列出了许可模式(专有、Apache、BSD、GPL),这在取决于您的应用程序时可能是重要的。
(请注意,这部分提到了一个表格,但并未提供详细的内容。如果您需要进一步的细节,可能需要访问原始论文或网站。)
System | License | Website for More Information |
|---|---|---|
Azure | Prop | |
Berkeley DB | BSD | |
BigTable | Prop | |
Cassandra | Apache | |
Clustrix | Prop | |
CouchDB | Apache | |
Dynamo | Internal | |
GemFire | Prop | |
HBase | Apache | |
HyperTable | GPL | |
Membase | Apache | |
Membrain | Prop | |
Memcached | BSD | |
MongoDB | GPL | |
MySQL Cluster | GPL | |
NimbusDB | Prop | |
Neo4j | AGPL | |
OrientDB | Apache | |
PNUTs | Internal | |
Redis | BSD | |
Riak | Apache | |
Scalaris | Apache | |
ScaleBase | Prop | |
ScaleDB | GPL | |
SimpleDB | Prop | |
Terrastore | Apache | |
Tokyo | GPL | |
Versant | Prop | |
Voldemort | None | |
VoltDB | GPL |
[NOTE!]
滚滚长江东逝水,浪花淘尽英雄。文中的不少产品已经被遗忘在了历史的角落里,有些则如日中天。
本文成于14年前,相关产品也发生了许多变化,希望大家抱着学习而不是挑刺的心态看文章。
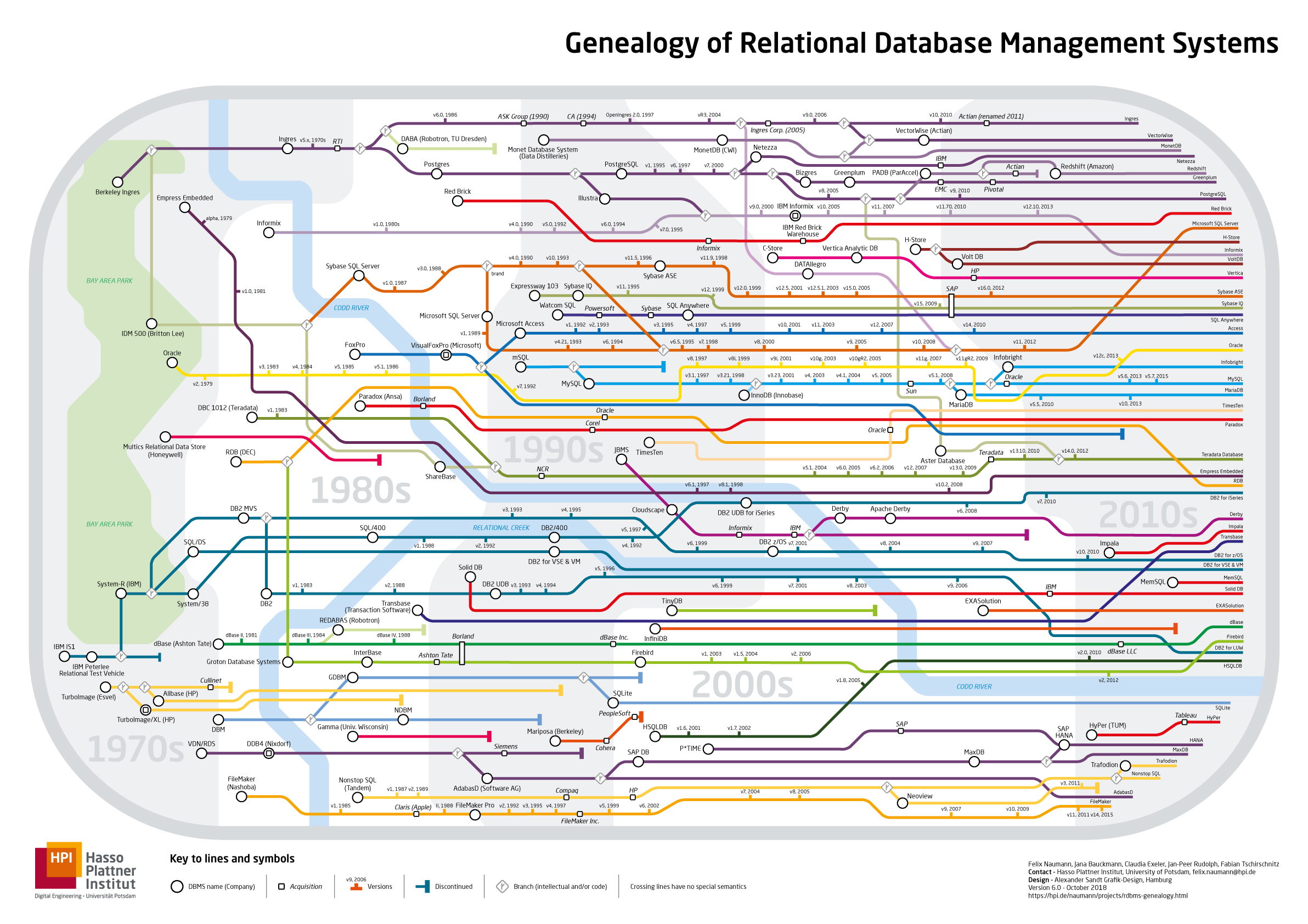
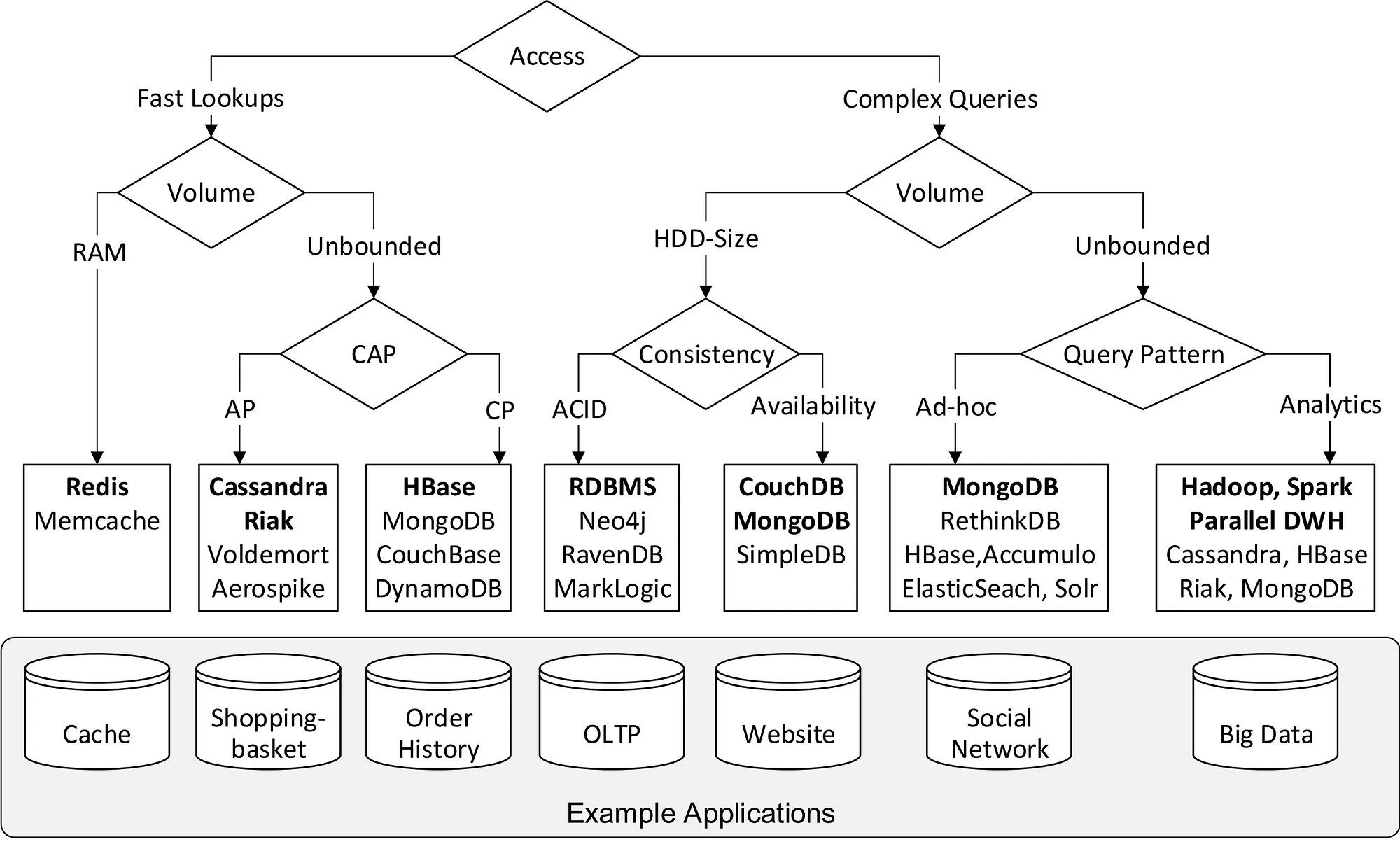
最后附上两张图
一张是关系型数据库的演化史,一张是NoSQL的分类图
另外,本文对NoSQL的重要分支,图数据库只是一笔带过了,没有深入的去讨论,这点也很可惜。