

I/O Patterns
Dinesh & Rakesh
March 1, 2024
演讲人介绍
Dinesh Kumar
Principal Architect @ Tessell
Active contributor to Opensource tools around PostgreSQL
Author of two PostgreSQL books
Rakesh
Solutions Architect @ Tessell
Extensively built products & platforms with PostgreSQL
What is I/O?
从高层次来看,I/O 操作是请求从磁盘读取数据(“输入”)或向磁盘写入数据(“输出”)的操作,通常以每秒操作数来衡量。
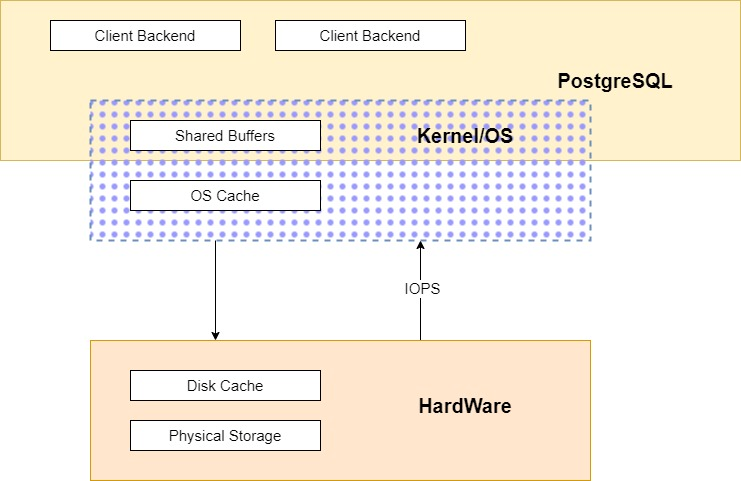
这张图是关于 PostgreSQL 数据库中的 I/O(输入/输出)流程的高级视图。下面是每个部分的分析:
客户端后端(Client Backend): 这些代表了与用户或应用程序的会话相对应的 PostgreSQL 服务器进程。每个客户端连接都会有一个独立的后端进程。
共享缓冲区(Shared Buffers): 这是 PostgreSQL 中内存中的一块区域,用于缓存数据库中的数据页。所有客户端后端都会共享这些缓冲区,以避免重复读取同一数据页。
内核/操作系统(Kernel/OS): 数据库系统与操作系统交互的层次。这里会涉及更多的缓存,比如操作系统级别的缓存(OS Cache)。
操作系统缓存(OS Cache): 这是操作系统管理的内存部分,用于缓存磁盘操作。有些情况下,数据可能会先在操作系统的缓存中被缓存,然后再根据需要写入磁盘。
磁盘缓存(Disk Cache): 磁盘缓存是磁盘硬件自带的缓存机制,用于暂存从磁盘读取或准备写入磁盘的数据。
物理存储(Physical Storage): 这表示实际存储数据的物理硬盘或任何其他形式的持久化存储。
IOPS: 这是衡量磁盘性能的一个关键指标,代表每秒输入输出操作的次数。这里它可能表示从数据库系统到物理存储层的 I/O 请求频率。
I/O Patterns
PostgreSQL 使用内存组件和后台进程的组合来管理其数据存储和检索。
Memory
shared_buffers - PostgreSQL 用于缓存数据块的内存空间。
wal_buffers - PostgreSQL 中用于缓存预写日志信息的缓冲区。
work_mem - 用于排序操作和哈希表的内存区域。
maintenance_work_mem - 用于维护操作,如创建索引和清理(vacuum)的内存区域。
autovacuum_work_mem - 自动清理工作进程的内存区域。
logical_decoding_work_mem - 用于 walsender 或复制连接的内存区域,将 WAL 转换为逻辑流。
temp_buffers - 临时对象创建时所使用的内存区域。
Processors
在 PostgreSQL 数据库中,不同的进程与特定的内存区域进行交互,以执行它们的任务:
客户端后端(Client Backend): 这是处理客户端请求的进程。它与以下内存组件有广泛的交互:
shared_buffers:用于缓存常用的数据块,减少磁盘 I/O。
wal_buffers:用于缓存预写日志信息,保证事务的持久性。
temp_buffers:用于存储临时表和临时查询结果。
work_mem:为排序操作和哈希表提供内存。
检查点器(Checkpointer): 负责定期将 shared_buffers 中的脏页(修改过的页)和 WAL 信息刷新到磁盘上,以确保数据的一致性和恢复能力。它与以下内存组件交互:
shared_buffers
wal_buffers
WAL 写入器(WAL Writer): 负责将 wal_buffers 中的数据定期写入磁盘上的 WAL 文件。这有助于减少事务提交时的磁盘 I/O。它与以下内存组件交互:
wal_buffers
维护工作者(Maintenance Workers): 执行数据库维护任务,如索引重建和空间回收。它与以下内存组件交互:
maintenance_work_mem
自动清理工作者(Autovacuum Workers): 自动执行清理操作,帮助回收已删除元组的空间,并优化数据库性能。它与以下内存组件交互:
autovacuum_work_mem
WAL 发送器(WAL Senders): 主要用于复制,将 WAL 数据流发送到备用服务器或者逻辑复制槽。它与以下内存组件交互:
logical_decoding_work_mem
配置了简单的 PostgreSQL 主从实例,以识别 PostgreSQL 引擎中的 I/O 模式。
我们广泛使用了:
strace
PostgreSQL I/O 目录表
PostgreSQL 日志,来理解 I/O 是如何在用户操作中移动的。
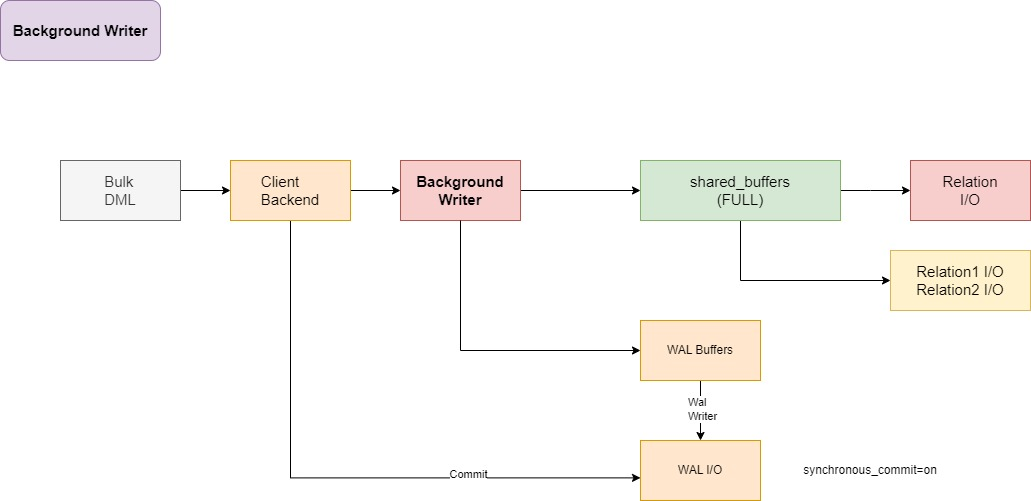
Single DML
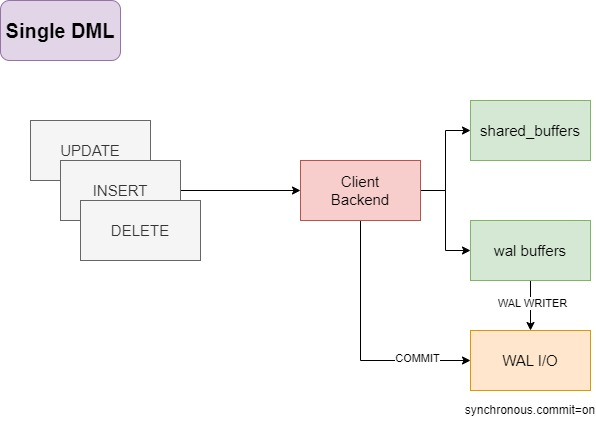
组件说明
单个 DML(Single DML): 这代表一个单独的数据操作,如 INSERT、UPDATE、DELETE 等。
客户端后端(Client Backend): 这是处理单个 DML 请求的 PostgreSQL 服务进程。它与 shared_buffers 进行交互来缓存数据,与 wal_buffers 交互来缓存 WAL 记录。
共享缓冲区(shared_buffers): 这里存储的是 PostgreSQL 用于缓存表数据的内存结构,可以减少磁盘 I/O 的需求。
WAL 缓冲区(wal_buffers): 这是专门用来缓存即将写入 WAL 文件的数据的内存区域。
提交(commit): 当事务提交时,会触发 WAL I/O。如果 synchronous_commit 设置为 on,那么在事务被认定为成功之前,相关的 WAL 必须被写入存储。
WAL 写入器(WAL Writer): 这个进程负责将 WAL 缓冲区的内容写入磁盘。
WAL I/O: 这代表实际的 I/O 操作,即将 WAL 数据从缓冲区写入到磁盘上的 pg_wal 文件中。此外,如果涉及到的表的空间状态发生变化,那么相关的空间映射(如 free space map)也会被更新。
在这里,客户端后端连接在完成事务后执行了一个简单的 WAL I/O 操作,更新了事务的提交/回滚状态。
先写入 pg_wal 文件。
然后更新关系的空间映射(relation_fsm,即 free space map)。
Bluk Insert
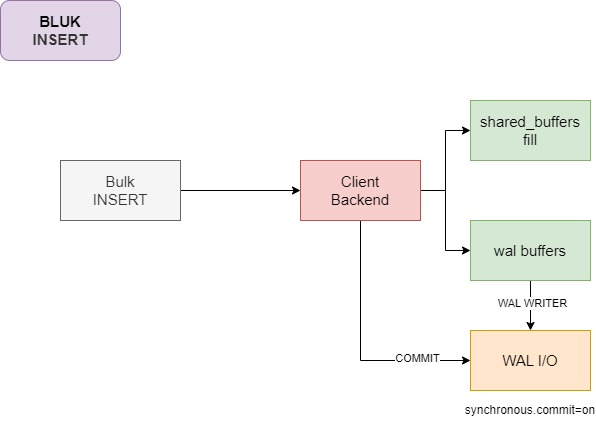
各个组件与上面大同小异,不做复述
不过在刷写WAL日志中多了一步切换
写入 pg_wal 文件。
切换 WAL日志。
更新 relation_fsm(空闲空间映射)。
为什么shared_buffer会被填充
在批量插入操作期间,PostgreSQL 的 shared_buffers 被填充是因为这是数据库缓存表数据和索引数据的主要区域。这里有几个原因:
缓存最近的数据: PostgreSQL 会尝试缓存最近查询或修改过的数据。在批量插入期间,新的数据块会被加载到
shared_buffers中,因为这些数据块是最近被修改的。性能优化: 将数据保持在内存中可以加速后续的读取操作,因为从内存读取数据远比从磁盘快。即使是对于写操作,数据库也会从
shared_buffers中读取数据页,以便在执行写操作前进行修改。减少磁盘 I/O: 如果
shared_buffers足够大,批量插入期间可能会完全在内存中处理,这可以减少立即发生的磁盘写操作,因为只有当shared_buffers满了或者发生检查点(checkpoint)时,脏页(修改后的数据页)才会刷新到磁盘。事务完整性: 即使是在批量插入的情况下,PostgreSQL 还是需要保证事务的原子性和持久性。这就要求所有变更都要记录在 WAL 中,并且涉及的数据页需要在提交前被载入到
shared_buffers。
总的来说,shared_buffers 被填充是 PostgreSQL 正常操作的一部分,即使在批量插入的场景下也是如此。它确保了数据库能够以最优的性能执行操作,并维护数据的一致性和持久性。
Any DML
在关闭异步提交后,WAL 写入器将会完成所有的 I/O 操作。
写入 pg_wal
进行新 WAL 日志的切换
在这里,所有的 WAL I/O 都由 WAL 写入器负责。
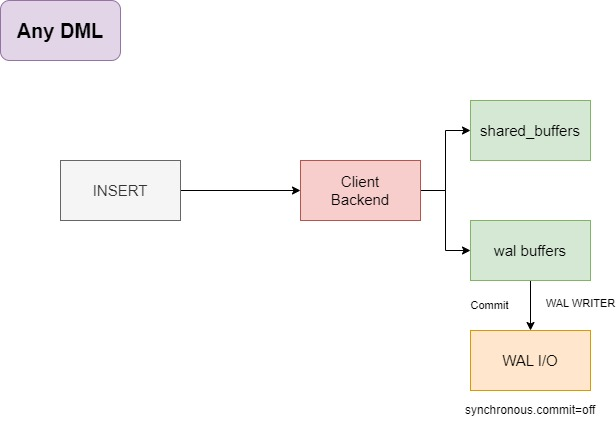
而在异步提交打开后
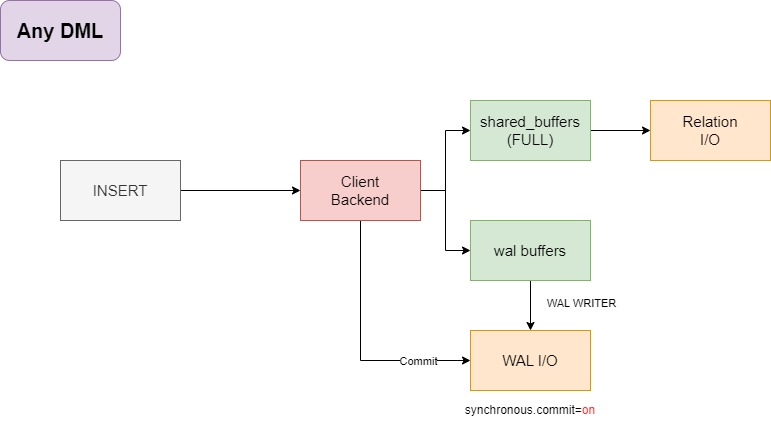
客户端后端进程将做更多的事情,更多的 I/O 操作
将脏缓冲区刷新到底层Relation中
WAL I/O操作
Temp Table
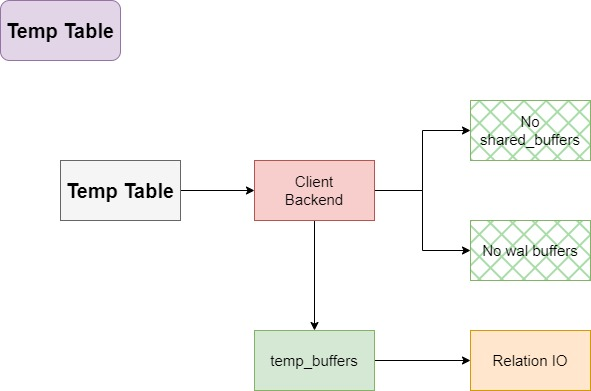
客户端后端进程处理临时relation文件。
没有 WAL 数据,因此不支持复制。
临时表的作用域为事务,即临时relation对象可以在 COMMIT 后被删除。
由于临时表不是常规表,并且存在于一个特殊的schema中,所以没有其他 I/O 操作,如自动清理(autovacuum)、检查点(checkpointer)。
Query
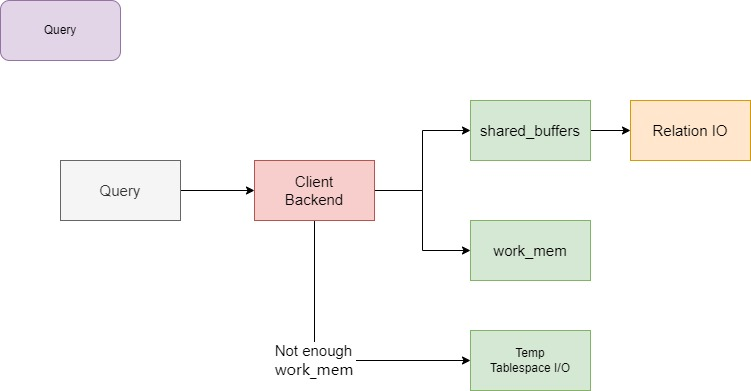
当找到足够的 work_mem 时,客户端后端以及后台并行工作进程会创建临时文件。
pg_stat_database 功能有助于识别 I/O。
pg_stat_database 是 PostgreSQL 中的一个系统视图,它提供了数据库级别的统计信息,可以帮助你识别和监控数据库的 I/O 活动。这个视图包含多个与 I/O 相关的统计列,比如:
blk_read_time:表示从磁盘读取数据块所花费的时间,以毫秒为单位。
blk_write_time:表示将数据块写入磁盘所花费的时间,以毫秒为单位。
blks_read:表示从磁盘上读取的数据块数。
blks_hit:表示在 shared buffers 中找到的数据块数,从而避免了磁盘读取。
通过检查这些列,你可以获得数据库 I/O 负载的一个概念。例如,如果 blk_read_time 或 blks_read 的值很高,这可能表明有大量的磁盘读取活动,这可能是磁盘性能瓶颈的迹象。相对地,如果 blks_hit 的值远远高于 blks_read,这表明大多数数据请求都能够从 shared buffers 中满足,这是一种理想的情况,因为内存访问比磁盘访问要快得多。
进一步的分析,如比较 blks_read 和 blks_hit 的比率,可以帮助你决定是否需要调整 shared_buffers 的大小或考虑其他优化数据库性能的方法。如果系统频繁地从磁盘读取数据(即 blks_read 较高),增加 shared_buffers 的大小可能会有所帮助,因为它可以增加内存中缓存的数据量,从而减少对磁盘的读取需求。
同样,pg_stat_database 视图还可以帮助识别是否有过多的临时文件生成,这可能是因为 work_mem 设置得太小。如果查询操作超出了 work_mem 所设置的内存限制,PostgreSQL 就会使用磁盘上的临时文件来处理查询。这会在 temp_bytes 和 temp_files 的统计数据中反映出来,表明 I/O 负载中有一部分是由于临时文件的读写造成的。
总而言之,通过监控 pg_stat_database 提供的指标,你可以对 PostgreSQL 的 I/O 活动有一个实时的了解,并根据这些数据进行适当的性能调整。
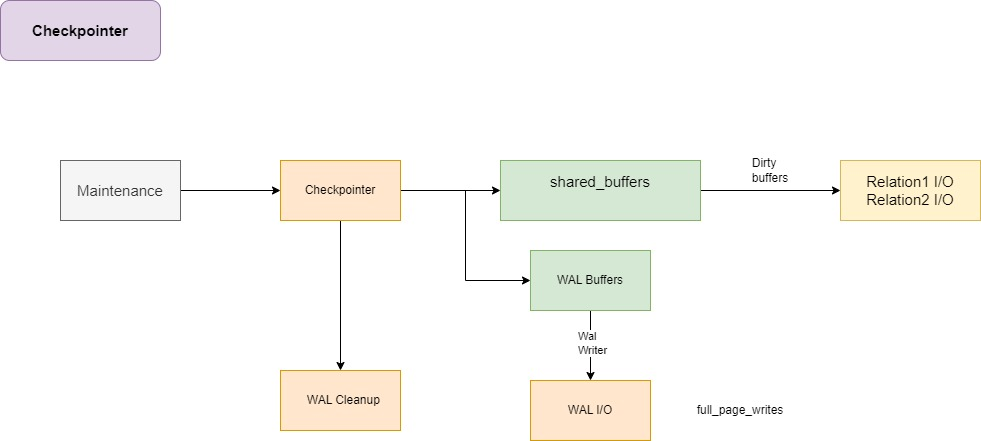
Maintenance
维护进程
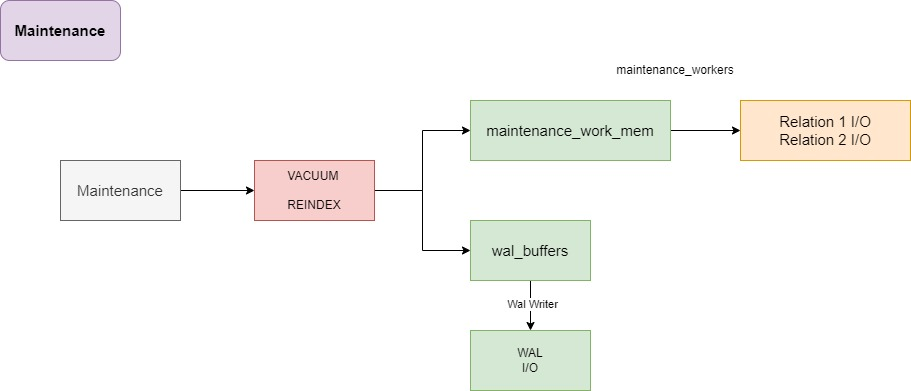
vacuum的主要步骤
清理死亡元组
执行事务冻结
更新可见性映射(vm)
更新空闲空间映射(fsm)
reindex的主要步骤
锁定索引:
REINDEX命令首先锁定要重建的索引以防止任何写操作。删除旧索引: 删除旧的索引数据,为创建新的索引结构腾出空间。
创建新索引: 基于原始表的数据,创建一个新的索引结构。这个过程会扫描整个表,并将找到的每一行插入到新的索引中。
验证索引: 对新建立的索引进行检查,确保它正确地反映了表中的数据。
切换索引: 当新索引建立并验证无误后,系统将替换旧的索引。这个步骤可能会短暂地阻塞对表的读写操作。
释放锁定: 一旦新索引就位,相关的锁会被释放,表和新索引都可以重新开始接收查询和更新操作。
清理: 清除与旧索引相关的任何资源和文件。
pg_stat_user_tables和pg_stat_progress_vacuum
pg_stat_user_tables 和 pg_stat_progress_vacuum 是 PostgreSQL 提供的两个系统视图,它们可以帮助你监控和理解数据库维护活动中的 I/O 操作,尤其是与清理(vacuum)和索引重建等维护任务相关的 I/O。
pg_stat_user_tables
这个视图提供了用户表级别的统计信息,与维护 I/O 相关的主要列包括:
n_tup_ins,n_tup_upd,n_tup_del:分别显示了表中插入、更新、删除的元组数量。n_tup_hot_upd:显示"热更新"(HOT)的元组数量,即不需要更新索引的更新操作。n_live_tup,n_dead_tup:分别显示活动元组和死亡元组的数量,死亡元组是指已被删除或已被更新(旧版本)的元组,这些元组可以在清理操作中被移除。last_vacuum,last_autovacuum,last_analyze,last_autoanalyze:显示最后一次手动或自动清理和分析的时间戳。vacuum_count,autovacuum_count,analyze_count,autoanalyze_count:显示了各种维护操作的执行次数。
通过监视上述统计信息,可以观察到维护操作的频率和时机,以及这些操作如何可能影响 I/O 负载。例如,一个高数量的 n_dead_tup 通常会触发自动清理,这可能会增加 I/O 负载。
pg_stat_progress_vacuum
这个视图则提供了正在进行的清理操作的实时进度信息,它的一些列可以帮助识别当前清理操作的 I/O 活动:
pid:正在执行清理的后台进程的进程ID。phase:当前清理操作的阶段,比如 "initializing", "scanning heap", "vacuuming indexes", "cleaning up indexes" 等。heap_blks_total:需要扫描的堆(表)块总数。heap_blks_scanned:已经扫描的堆块数。heap_blks_vacuumed:已经清理的堆块数。index_vacuum_count:已清理的索引数量。max_dead_tuples:在开始清理时评估的死亡元组的最大数量。num_dead_tuples:已经找到的死亡元组数量。
这些信息可以告诉你当前清理操作的工作量和进度,有助于理解数据库的 I/O 模式。例如,如果清理操作正在处理大量的死亡元组,这可能表明较高的 I/O 活动。同时,了解清理进度有助于预测维护操作何时完成,以及它们可能对数据库性能产生的影响。
通过定期查询这两个视图,你可以获得对数据库维护操作(特别是清理操作)对 I/O 的影响的深入了解,并据此进行调优和容量规划。
Background Write
后台写进程
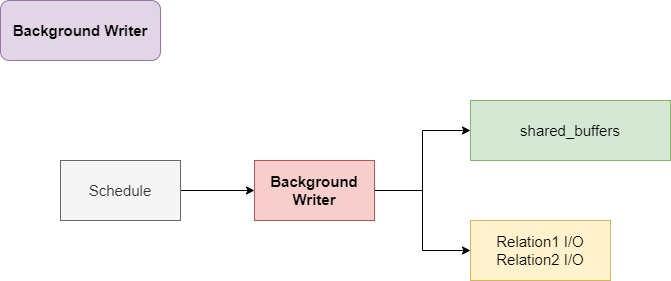
后台写进程(Background writer)为客户端后端和检查点器(Checkpointer)进程提供了缓解,防止IO尖刺。
它根据最近最少使用(LRU)策略定期清理脏缓冲区。
pg_stat_bgwriter 是一个系统目录表,它有助于识别 I/O。
在计算机科学中,最近最少使用(LRU, Least Recently Used)是一种常见的页面替换算法,用于管理内存中的缓存。PostgreSQL的后台写进程(Background Writer)就使用了类似的策略来管理其 shared_buffers 中的数据页。
当 shared_buffers 中的数据页被修改(比如,由于INSERT、UPDATE或DELETE操作)后,这些页就会被标记为“脏”页,意味着它们与磁盘上的数据不同步,需要在某个时间点写回到磁盘。
PostgreSQL的后台写进程使用类似LRU的策略按以下方式工作:
周期性检查: 后台写进程周期性地检查
shared_buffers中的脏页。确定哪些页是"脏"的: 进程检查哪些页被标记为脏,这表示它们自从被加载或者上次写入以来已经被修改过。
基于使用情况决定写回策略: 使用LRU策略,后台写进程会优先考虑最近最少使用的脏页写回磁盘。因为它们很可能是"最冷"的数据页,被再次访问的概率较低。
写回磁盘: 选定的脏页会被写回到磁盘上,以减少客户端后端和检查点器在高峰时需要写入的数据量。
释放或重用缓存空间: 一旦脏页被写回磁盘,它们的内存空间可以被清理并用于缓存其他数据页。
这种方法的好处是它可以将写入操作分散在较长的时间段内进行,减少了在事务提交或检查点发生时的I/O峰值,从而优化了整体的系统性能。
在 PostgreSQL 中,后台写进程的行为可以通过调整配置参数(如 bgwriter_lru_maxpages 和 bgwriter_lru_multiplier)来控制。通过监控 pg_stat_bgwriter 视图,管理员可以看到后台写进程写回磁盘的页数、清理脏页的频率等统计信息,这有助于了解和调整数据库的 I/O 行为。
在 PostgreSQL 中,bgwriter_lru_maxpages 和 bgwriter_lru_multiplier 是两个重要的配置参数,用于调整后台写进程(Background Writer)的行为,特别是在处理最近最少使用(LRU)算法清理脏页时。了解和调整这些参数可以帮助优化数据库的 I/O 性能。
bgwriter_lru_maxpages
bgwriter_lru_maxpages 参数控制在后台写进程唤醒时最多可以写回多少页。每次后台写进程唤醒时,它会检查 shared_buffers 中的脏页,并根据 LRU 策略决定哪些页需要被写回磁盘。这个参数的值就是限制每次唤醒时能处理的最大页数。如果设置得太低,可能导致脏页不被及时写回,从而影响性能;如果设置得太高,可能会导致短时间内大量的磁盘 I/O,也可能对性能产生负面影响。
默认情况下,bgwriter_lru_maxpages 的值通常设为较小的数值,如 100,以避免在单次清理操作中产生过多的磁盘写操作。
bgwriter_lru_multiplier
bgwriter_lru_multiplier 是一个乘数,用于根据数据库负载动态调整后台写进程的活动。这个参数基于系统负载(主要是脏页的增长速度)来调整后台写进程在每次唤醒时应该写回的页面数量。
这个乘数将应用于一个计算出的基线值(基于系统活动和脏页数量),最终确定实际写回的页面数量。例如,如果 bgwriter_lru_multiplier 设置为 2.0,并且基于当前系统活动计算得出每次需要清理 50 页,那么实际上会尝试清理 100 页。
通过调整这个乘数,你可以使后台写进程更为积极地响应系统负载变化,尤其是在脏页快速增长时,可以更快地将它们写回磁盘,从而释放 shared_buffers 中的空间,减少因为缓存压力而引起的性能下降。
总结
调整这些参数时,需要根据你的具体数据库负载和硬件性能来决定。监控工具(如 pg_stat_bgwriter 视图)可以提供有关后台写进程效率和当前数据库脏页状态的信息,帮助数据库管理员做出更好的配置决策。在实际环境中,可能需要根据观察到的性能表现来多次调整这些参数,以找到最优的设置。
Checkpointer
pg_stat_bgwriter 是一个表,有助于识别 I/O。
它记录了从磁盘页到 WAL 的信息,在检查点之后该页首次修改时进行记录。
pg_stat_bgwriter 是 PostgreSQL 中一个非常有用的视图,它提供了后台写进程(Background Writer)的统计信息,帮助数据库管理员了解和监控后台写进程对磁盘 I/O 的影响。这个视图包含了关于数据写入、缓存管理和系统性能的各种指标,使得数据库维护和优化变得更加可控和高效。
主要列和它们的含义
checkpoints_timed: 统计自数据库启动以来,定时触发的检查点(checkpoint)的数量。检查点是 PostgreSQL 定期进行的一种操作,用以确保所有之前的事务修改都已经写入硬盘。
checkpoints_req: 统计自数据库启动以来,由于数据库缓冲区满而强制触发的检查点数量。
checkpoint_write_time: 显示所有检查点过程中写入磁盘的总时间(以毫秒为单位)。这包括写数据和事务日志的时间。
checkpoint_sync_time: 显示所有检查点过程中同步所有数据文件到磁盘所消耗的总时间(以毫秒为单位)。
buffers_checkpoint: 显示在检查点期间写入磁盘的缓冲区数量。
buffers_clean: 显示后台写进程清理(即写回磁盘)的缓冲区总数。
maxwritten_clean: 如果后台写进程在尝试写入时发现没有更多的脏缓冲区可写,则会发生"maxwritten_clean"事件,此列统计了这种事件的发生次数。
buffers_backend: 显示由普通数据库操作(如用户查询)直接写入磁盘的缓冲区数量。
buffers_backend_fsync: 显示执行 fsync 操作(用于将内存中的数据同步到硬盘)的次数,通常在缓冲区被后端进程修改后发生。
buffers_alloc: 显示自数据库启动以来分配的缓冲区总数。
通过监控这些指标,管理员可以获得关于系统如何处理缓冲区、检查点频率以及磁盘写入活动的详细信息。这些数据对于调整配置参数(例如后台写进程的行为)、诊断性能问题以及确保系统稳定性都非常有用。例如,频繁的检查点可能指示 shared_buffers 设置过低,或者 bgwriter_lru_maxpages 和 bgwriter_lru_multiplier 需要调整以更有效地管理脏缓冲区。
full_page_writes 是 PostgreSQL 配置参数之一,对数据库的安全性和性能有重要影响。这个参数控制着 PostgreSQL 是否在每次写入时都将整个数据页写入 WAL(Write-Ahead Logging),而不仅仅是数据页中改变的部分。
工作原理
当 full_page_writes 设置为 on(默认设置),PostgreSQL 在检查点前的第一次修改每个数据页时,会将整个数据页的内容写入 WAL。这是为了防止所谓的 "部分写" 故障,即在写入磁盘时由于故障导致只有部分数据页内容被更新,从而产生数据损坏。
为什么需要 full_page_writes
避免部分写损坏: 数据库系统在写入大于操作系统文件系统块大小的数据页时,可能会发生只有部分数据页被物理写入的情况。如果在这种部分写入的页上发生系统崩溃,那么在恢复时,这些页可能包含不一致的数据。通过在 WAL 中记录完整的页,PostgreSQL 可以在恢复时确保数据的完整性和一致性。
系统崩溃恢复: 在系统崩溃后进行恢复时,如果
full_page_writes为on,PostgreSQL 可以使用 WAL 文件中记录的完整页面信息来恢复到最后一致的状态,这有助于确保数据完整性。
性能考量
虽然 full_page_writes 增加了数据安全性,它也可能对性能产生影响,因为写入整个页面到 WAL 需要更多的 I/O 带宽和存储空间。因此,一些具备高可靠性硬件和对性能有极端要求的环境可能会考虑在安全的维护窗口期间关闭此功能。
配置建议
对于大多数生产环境,推荐保持
full_page_writes为开启状态,以保障数据完整性。在进行大规模数据导入或其他批量操作时,如果确定系统的硬件可靠性高(如使用 UPS 的电源保护和高端存储系统),可以临时关闭
full_page_writes以提高性能。定期评估和监测数据库的性能和完整性,根据实际需求调整此参数。
总的来说,full_page_writes 是一个重要的安全特性,它帮助确保在面临系统故障时,数据页的完整性和一致性能够被保持。
Walsender

如果内存不足,那么数据将溢出到磁盘(WAL日志打爆磁盘)。
pg_stat_replication_slots 是一个目录表,有助于识别溢出的字节。
从 PostgreSQL 16 版本开始,可以从副本平衡这些 I/O。
在 PostgreSQL 中,如果 WAL (Write-Ahead Logging) 缓冲区内存不足,即 WAL 缓冲区已满而无法立即处理更多的写入请求时,系统会将额外的 WAL 数据溢出到磁盘。这个过程是 PostgreSQL 数据库管理系统中事务日志管理的一部分,确保了数据库的数据一致性和恢复能力。下面是详细的步骤说明:
步骤 1: WAL 缓冲区填满
WAL 缓冲区是一块内存区域,用于暂存即将写入磁盘的 WAL 记录。当数据库进行写操作(如 INSERT、UPDATE、DELETE)时,相关的 WAL 记录首先被写入到这个缓冲区中。如果在 WAL 缓冲区被写满之前无法写入磁盘(例如,由于 I/O 系统繁忙或磁盘写入速度慢),缓冲区可能会填满。
步骤 2: 触发 WAL 写入
当 WAL 缓冲区达到其容量极限时,PostgreSQL 会触发一个操作将缓冲区中的数据写入到磁盘上的 WAL 文件中。这通常是由 WAL Writer 后台进程负责执行。WAL Writer 定期运行,将缓冲区中的数据异步写入磁盘。
步骤 3: 数据溢出到磁盘
如果 WAL 缓冲区满了且当前的 WAL Writer 周期还未开始写入磁盘,系统必须将超出缓冲区容量的 WAL 记录直接写入磁盘。这种直接写入磁盘的操作会减慢整体系统性能,因为每个写入操作都需要同步完成,而不能利用缓冲区提供的批量写入优势。
步骤 4: 检查点和 WAL 切换
定期,PostgreSQL 会执行检查点操作,这时会强制将所有剩余的 WAL 记录从缓冲区刷写到磁盘,并且如果需要,还会切换到一个新的 WAL 文件。检查点有助于减少数据库恢复时间,因为它标记了一个已知的良好状态,从这个状态开始恢复操作会更快。
步骤 5: 监控和调整
数据库管理员可以通过查看 pg_stat_bgwriter 和其他相关的统计视图来监控 WAL I/O 活动和性能。如果经常发生内存不足导致数据溢出到磁盘的情况,可能需要调整 WAL 缓冲区大小(wal_buffers 参数),或者优化磁盘 I/O 性能,以避免这种性能瓶颈。
总之,WAL 日志内存不足导致数据溢出到磁盘的情况是一个需要密切监控和适时调整的问题,确保数据库操作的高效和稳定。调整和优化这些参数可以显著改善系统的响应时间和可靠性。
Logger
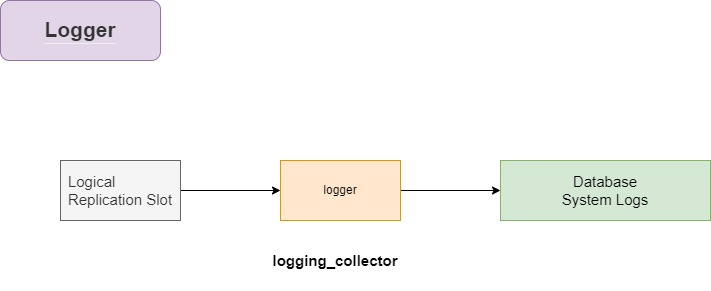
具体内容如下:
数据库系统活动
自动清理统计
检查点统计
等待锁,死锁
日志轮转
运行缓慢的查询
生成大量临时文件的查询
CSV/JSON 日志格式
在 PostgreSQL 中,逻辑复制槽、日志记录器(logger)以及数据库系统日志的概念涉及到数据复制和日志管理的多个层面。logging_collector 在这些组件协同工作的过程中扮演着重要角色,负责收集和管理日志数据。下面将详细说明这些组件的作用及 logging_collector 的运行方式:
逻辑复制槽(Logical Replication Slot)
逻辑复制槽是 PostgreSQL 中用于逻辑复制的一种机制,它保留了发送给复制订阅者的 WAL 日志信息,确保即使在复制订阅者暂时断开连接的情况下,所需的数据也不会从主服务器上删除。这样可以保证订阅者在重新连接时能够接收到所有缺失的数据更改。
日志记录器(Logger)
日志记录器是 PostgreSQL 系统中负责日志记录的组件,它可以记录查询、错误、警告和其他系统消息。日志记录器的行为(如何记录、记录什么内容、记录到哪里等)可以通过 PostgreSQL 的配置文件(通常是 postgresql.conf)中的多个日志相关的设置进行配置。
数据库系统日志
数据库系统日志包含了数据库操作的详细记录,如事务处理、系统错误、警告消息以及其他重要的系统信息,对于数据库的维护和故障排查至关重要。
logging_collector 的运行
当 logging_collector 设置为开启(on)时,PostgreSQL 会启动一个独立的日志收集进程。这个进程负责从 PostgreSQL 的标准错误输出中捕获日志输出,并将其重定向到配置中指定的日志文件。这包括:
重定向日志输出: 所有从数据库系统、逻辑复制槽和其他数据库活动产生的日志都会被捕获,并根据配置(如日志格式、日志级别等)进行处理。
管理日志文件: 日志收集器根据配置管理日志文件的创建、写入、轮转和删除。例如,可以配置日志文件每天轮转一次,或在文件达到特定大小时轮转。
优化性能: 由于日志收集操作是由一个独立的进程管理,它帮助减轻了主数据库进程的负担,允许数据库更专注于处理查询和事务。
通过以上机制,logging_collector 在 PostgreSQL 的日志管理体系中起到了核心作用,它不仅保证了日志数据的完整性和可用性,也支持了高效的日志处理和存储。对于维护大型数据库系统或进行故障诊断,合理配置和使用 logging_collector 是非常重要的。
Replica
在一个独立的备节点实例上的后台进程包括:
检查点器(checkpointer)
后台写入器(bgwriter)
启动恢复(startup recovering)
WAL 接收器流(walreceiver streaming)
日志记录器(logger)
在 PostgreSQL 的副本节点上,多个后台进程协同工作,以确保数据的一致性和持续同步。以下是每个进程的作用及它们如何在副本节点上协同工作:
1. 检查点器(Checkpointer)
检查点器在副本节点上的作用与在主节点上类似,负责定期将内存中的数据和状态信息刷新到磁盘上,帮助减少在发生故障时所需的恢复时间。检查点的创建确保了在特定时间点的数据的持久性,即使系统崩溃也能从检查点恢复。
2. 后台写入器(Bgwriter)
后台写入器负责将修改过的缓冲区(脏页)周期性地写回磁盘,减轻检查点时的I/O负载,并帮助管理内存。在副本节点上,它同样帮助维护数据库的性能,通过减少需要在恢复或检查点期间进行的写操作。
3. 启动恢复(Startup Recovering)
启动恢复进程在副本节点上尤为重要,因为它负责应用主节点上的 WAL 记录来更新副本节点的状态,确保副本节点与主节点保持数据一致性。这个进程在副本启动时启动,并持续运行直到副本与主节点同步。
4. WAL 接收器流(Walreceiver Streaming)
WAL 接收器是副本节点特有的进程,负责从主节点接收 WAL 数据。这些数据是通过流复制实时发送的,WAL 接收器将接收到的 WAL 数据写入本地的 WAL 文件中,供启动恢复进程读取并应用到数据库中。
5. 日志记录器(Logger)
日志记录器在副本节点上的作用与在主节点上相同,负责记录各种事件,如错误、警告、操作信息等。日志对于监控副本状态、诊断问题及审计等都是必不可少的。
协同工作机制
这些进程之间的协同工作确保了副本节点的数据一致性和系统的高可用性:
WAL 接收器接收来自主节点的 WAL 数据,并将其保存在本地。
启动恢复进程读取这些 WAL 记录,应用它们以更新副本节点的数据库状态,使其与主数据库同步。
检查点器和后台写入器负责管理磁盘上的数据,优化 I/O 操作,确保数据的持久化和高效存储。
日志记录器提供操作的可追踪性和系统状态的可视化,帮助管理和调试。
通过这种方式,副本节点能够有效地保持与主节点的数据一致性,同时提供数据冗余和故障恢复能力。
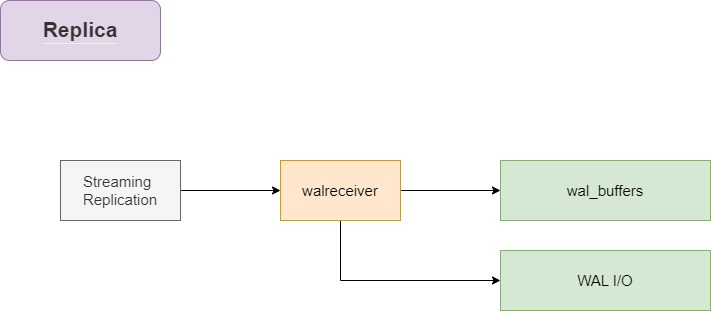
从 walsender 接收到的变更流将被推送到 wal_buffers 和 WAL 文件中。
在副本中不存在 walwriter 进程,walreceiver 进程承担了创建 WAL 文件的角色。
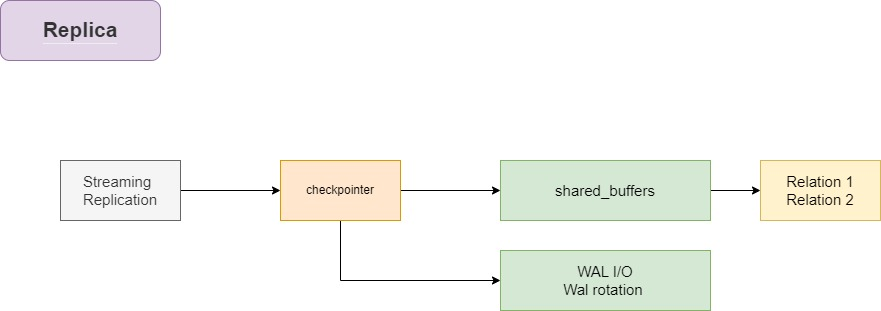
在备节点上,检查点被称为重启点。
只有定时的重启点,才会将数据从共享缓冲区刷新到底层relation对象中。
这些重启点有助于恢复中断的恢复过程。
postgres=# select count(*) from pg_buffercache where isdirty is true;
count
-------
312
(1 row)
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CHECKPOINT ;
CHECKPOINT
postgres=# select count(*) from pg_buffercache where isdirty is true;
count
-------
312
(1 row)
这一系列的 PostgreSQL 命令及其输出显示了一个有趣的现象,这涉及到在副本数据库中管理脏缓冲区(即已修改但尚未写入磁盘的缓冲区)。下面是这些命令和结果的解释:
查询脏缓冲区的数量:
select count(*) from pg_buffercache where isdirty is true;这个查询返回的结果是 312,表示在执行查询时共有 312 个脏页存在于缓冲区中。
查询数据库是否处于恢复模式:
SELECT pg_is_in_recovery();结果
t(true) 表示数据库当前处于恢复模式。在 PostgreSQL 中,副本数据库常常处于恢复模式,因为它们是通过应用从主节点接收的 WAL 日志来同步数据的。执行检查点:
CHECKPOINT;在主数据库中,
CHECKPOINT命令会触发脏页被写入到磁盘,并清理 WAL 日志。然而,在副本中,检查点被称为重启点,并不总是执行与主节点相同的操作。再次查询脏缓冲区的数量:
select count(*) from pg_buffercache where isdirty is true;结果仍然是 312,显示尽管执行了
CHECKPOINT命令,脏页的数量并未减少。
解释
在副本节点上,CHECKPOINT(在副本上称为重启点)通常不会像在主节点上那样强制将所有脏页刷新到磁盘。这是因为副本节点的数据同步是通过应用 WAL 日志来完成的,而不是直接通过 SQL 命令修改数据。因此,在副本上执行 CHECKPOINT 不会引发脏页的写入操作,因此脏页的计数在执行检查点后保持不变。
这种行为有助于副本节点专注于通过 WAL 日志高效地同步数据,而不是处理常规的 I/O 操作,从而维持其作为高可用性解决方案的性能和稳定性。
2024-02-25 20:02:58.110 GMT [150861] LOG: restartpoint complete: wrote 49513 buffers (37.8%); 0 WAL file(s) added, 1 removed, 20 recycled; write=53.971 s, sync=0.004 s, total=54.053 s; sync files=15, longest=0.002 s, average=0.001 s; distance=347850 kB, estimate=347850 kB; lsn=8/400000C8, redo lsn=8/274F4E30
postgres=# select count(*) from pg_buffercache where isdirty is true;
count
-------
0
(1 row)
备节点的重启点完成后,副本的共享缓冲区中的脏缓冲区被清除了。
这说明备节点的checkpoint不会被手动触发