

PG的存储和文件系统
PG的目录结构
PG的目录结构这里分为两类,一类是源代码目录结构,就是git clone 下来的那棵树。还有一类就是数据目录结构(PGDATA),就是在初始化实例的时候生成的。
源代码目录结构
官方仓库 postgres/,其顶层大致如下
postgres/
configure # 配置脚本
src/ # 所有代码的主战场
doc/ # 文档
contrib/ # 扩展、示例模块
config/ # 各种模板配置
...
官方使用doxygen 工具把 src/ 列成了一个目录树。核心子目录包括:backend/、bin/、common/、fe_utils/、include/、interfaces/、pl/、port/、test/、tools/、timezone/、tutorial/ 等。
src/backend/ 服务端核心
此目录是后台进程的实现,其下有access/、catalog/、commands/、executor/、optimizer/、parser/、postmaster/、replication/、storage/、tcop/、utils/等子目录。
postmaster/
postmaster.c:多进程架构的大管家,负责监听端口、fork子进程(后端/worker)、处理 SIGHUP、日志重启等。此目录下还有
bgwriter.c,checkpointer.c这种核心后台进程的实现。tcop/
traffic cop,该目录下主要维护后端进程,
postgres.c:每个后端进程的主循环:读 SQL → 解析 → 计划 → 执行 → 返回结果。parser/
解析器,
gram.y、scan.l:bison/flex 生成语法树的地方。optimizer/
优化器,
plan/main.c、geqo/等:逻辑计划到物理计划、代价估算。executor/
执行器,
execProcnode.c等:SeqScan/IndexScan/HashJoin这些节点是怎么一层层ExecProcNode的。storage/
buffer/、file/、smgr/:buffer cache、文件 FD 管理、表文件的读写(md.c)utils/
放各种“工具类”:
utils/adt/:内建数据类型的操作函数(int4eq、textcat之类)。utils/mmgr/:内存上下文。utils/resowner/:资源所有者栈。utils/init/:库启动、数据库切换、GUC 初始化等。
src/include/ 头文件
这个目录对应 backend 的公共接口,比如 postgres.h、utils/rel.h、storage/bufmgr.h 等。很多 on-disk 结构(如 RelFileNode、PageHeaderData)都在这里,可以对照数据目录里的实际文件理解页格式。
src/bin/ 前端工具
这里就是我们常用的cli工具的实现位置了,里面包含psql/、initdb/、pg_ctl/、pg_dump/等。
src/bin/initdb/
initdb.c:初始化集群、创建数据目录的逻辑都在这。文件注释里写得很明白:创建一个包含所有数据的目录、创建全局表文件、控制文件,并初始化template0、template1、postgres三个数据库。src/bin/psql/:交互式命令行客户端。src/bin/pg_ctl/:起停、重启服务。
其他目录
除了上面的后端进程,后台进程,前端工具等实现目录外,还有以下常用目录:
src/common/:前后端共享的通用代码(字符串、排序、压缩等)。src/fe_utils/:前端工具共享的封装(连接处理、进度条等)。src/interfaces/:各语言接口,最常见的是libpq。src/pl/:内置过程语言实现,比如plpgsql/src/。src/test/:回归测试、性能测试框架。
数据目录
执行SHOW data_directory后,可以看到$PGDATA目录,即实例所在的目录路径,里面同时放配置文件和所有数据库的物理文件。
initdb -D /pgdata/pg11后,目录大致如下:
PGDATA/
PG_VERSION
postgresql.conf
postgresql.auto.conf
pg_hba.conf
pg_ident.conf
base/
global/
pg_wal/
pg_xact/
pg_multixact/
pg_subtrans/
pg_tblspc/
pg_commit_ts/
pg_logical/
pg_stat/
pg_twophase/
...
先看下数据目录下的顶层文件:
PG_VERSION:一行文本,写 PostgreSQL 大版本号,启动时会检查兼容性。postgresql.conf:主要配置文件;你也可以把配置文件和数据目录分离,用data_directory、config_file参数单独指定。postgresql.auto.conf:ALTER SYSTEM SET ...写入的配置,优先级比postgresql.conf高。pg_hba.conf/pg_ident.conf:客户端认证、用户映射。
再梳理关键子目录:
base/
base/ 下每个子目录的名字是一个 数据库 OID。比如 SELECT oid, datname FROM pg_database; 里某个库的 oid = 16384,那么 base/16384/ 就是这个库的默认表空间中的所有表和索引。默认表空间 pg_default 就对应 PGDATA/base。
一个表对应的文件路径可以通过 SQL 直接查:
SELECT pg_relation_filepath('public.my_table');
-- 返回如: base/16384/12345global/
global/ 对应系统表空间 pg_global,用来存放整个集群共享的系统表,比如 pg_database 等。这些表物理上不属于某个具体数据库,因此路径是 global/<relfilenode>,RelFileNode 里 dbNode=0。
pg_wal/
预写日志目录,这里存的是所有 WAL 段文件,是崩溃恢复、归档、流复制的核心。版本10 之前目录名是 pg_xlog,后来改成 pg_wal,为了减少 DBA 把它当普通“日志”乱删的误解。
pg_xact/
事务提交状态,原来的pg_clog。这个目录存的是事务提交/回滚状态位图(所谓 CLOG,现在叫 pg_xact)。物理上是一个“按页滚动”的小文件系统,由通用的 SLRU 子系统 管理。
pg_multixact/
多事务锁,又叫共享行锁。用于记录 多事务共享锁(多个事务对同一行加共享锁)的状态,防止把一堆事务 ID 塞到一行里。同样由 SLRU 管理,对应源码 multixact.c。多更新、大量共享锁的场景下,你会看到 pg_multixact/members 等文件不断增长,清理时机也在这段代码里控制。
pg_subtrans/
子事务关系。记录子事务到父事务的映射,在异常、回滚时用来快速找到整棵子事务树。对应源码 subtrans.c,也是 SLRU 的一个实例,目录就是 pg_subtrans/。
pg_commit_ts/
事务提交时间戳。可选功能,如果开启了 track_commit_timestamp,每个事务的提交时间会记录在这里。源码 commit_ts.c,同样是 SLRU + 独立目录。
pg_tblspc/
表空间软链接。每个用户自定义表空间,会在这个目录下放一个 符号链接,名字是 tablespace 的 OID,指向你 CREATE TABLESPACE 时指定的物理目录。物理目录下面还会有一个版本子目录,如 PG_16_202405081/,再下面才是各个数据库 OID 的子目录。源码层面仍然用 RelFileNode.spcNode + 这个链接,把路径组合成: pg_tblspc/<spc_oid>/<version_dir>/<db_oid>/<relfilenode>。
pg_logical/
逻辑复制、解码数据。这里存 logical replication / decoding 的持久化状态,复制槽(slots)以及snapshot / mapping 等元数据。参考源码slot.c。
pg_stat/
持久化统计信息。pg_stat 里放的是 pg_statistic、pg_stat_* 视图背后的一些持久化统计快照,比如 global.stat、db_*.stat。pgstat.c,启动时从这里读入统计,定期刷回磁盘。
pg_twophase/
两阶段提交状态。存储所有 已准备但未提交 的 2PC 事务(PREPARE TRANSACTION)。每个事务一个文件,里面是需要恢复/提交/回滚时重放的操作描述。twophase.c 会在这里读写文件。
base/pgsql_tmp
临时文件以及各表空间的pgsql_tmp。排序 / HashAgg / HashJoin 等运算超出 work_mem 时,就会在PGDATA/base/pgsql_tmp/ 或表空间目录下的 pgsql_tmp/ 建临时文件。文件名里带有后台进程 PID 和序号,例如 pgsql_tmp12345.0。源码在 fd.c / buffile.c 一带,通过 pg_tempfile 这一类接口创建。
PG中的存储对象
segment
在Postgresql的存储架构中,段(segment)本质上就是把一个逻辑上的大对象(表/索引/wal/SLRU)的物理文件拆分成多个固定大小的文件块,每个块就是一个segment file。
由于单个文件无法无限长,所以才有了段这样的概念。操作系统和文件系统都对单个文件大小有限制,在极大文件的管理和性能上都不是很友好。PG中的某个表动辄数GB,有些甚至TB级别,如果使用一个超大的单独文件进行存储,移动和拷贝都会非常吃力,其他相对应的备份/监控等工具也都消化不了。所以PG采用了一个折中处理的办法:一个逻辑关系(表/索引)在物理上拆成多个段文件(segment file),每个段文件的大小固定在1GB。我们在base目录下常常可以看到 段文件12345,12345.1,12345.2等等,每个文件1GB。
表/索引段的命名方式
PG内部使用一个RelFileNode的数据结构来描述某个表/索引在磁盘上的位置,spcNode是表空间OID,dbNode是数据库OID,relNode这个表/索引的文件节点号,就是relfilenode。其路径就是
$PGDATA/base/<db_oid>/<relfilenode>可以使用以下语句查询某个对象的relfilenode
select pg_relation_filepath('public.mytables');WAL段
除了表/索引,还有一类WAL段非常重要。它位于$PGDATA/pg_wal下,每个WAL也是固定大小的文件,默认是16MB,PG11及以上版本可以在编译的时候设置的更大。文件名称是一串24位的16进制串
00000001 00000000 0000000A
时间号 log号 seg号概念上,wal流是顺序IO,其落盘文件不可能无限增大,所以也会被分为一段一段,每一段被称为WAL segment。分段的目的,除了崩溃恢复的时候定位加快,归档/恢复(PITR)/切换都很方便。
SLRU段
在pg_xact,pg_subtrans,pg_multixact,pg_commit_ts等目录中,事务状态被等元数据被划分为页(page),再按照一定页面数量组成文件段。这些目录下每个文件对应一个SLRU segment。文件名称通常是十进制数字,0000,0001,0002,代表这个SLRU的第几片。具体的逻辑实现在slru.c中,pageno(逻辑页号) \rightarrow segno = pageno/SLRU\_PAGES\_PERSEGMENT,再映射到dir/segno这样一个文件中。
段的大小
你可能会有疑问,为什么表/索引的文件段是1GB,而wal段是16MB,他们的默认值为什么不是更大或者更小?
总结一句话就是这是数十年社区经验的总结。段太小,则段的数量会被更多的切分,
open()/close(),文件句柄,inode管理,fsync等开销都会变多。但是又不能太大,历史上很多工具都是有大小上限的,32bit FS/工具在单个文件超过2GB/4GB的时候就会出现各种奇怪问题,一些备份/压缩/监控任务也会压力山大。或者你可以把这些默认大小当成历史包袱,多一分则压力大,少一分则乱。一个合适的大小,往往是实践反复打磨的结果,面对这些内容要有敬畏心,尤其在魔改的时候。
page
在文件段下一层的存储单位就是页面(page/block),需要注意的是Linux默认的页面大小是4KB,而Postgresql默认的页面大小是8KB。每个页面内部又被分为: 页头->行指针(itemid数组)->空闲区->元组数据->特殊区(多用于索引)
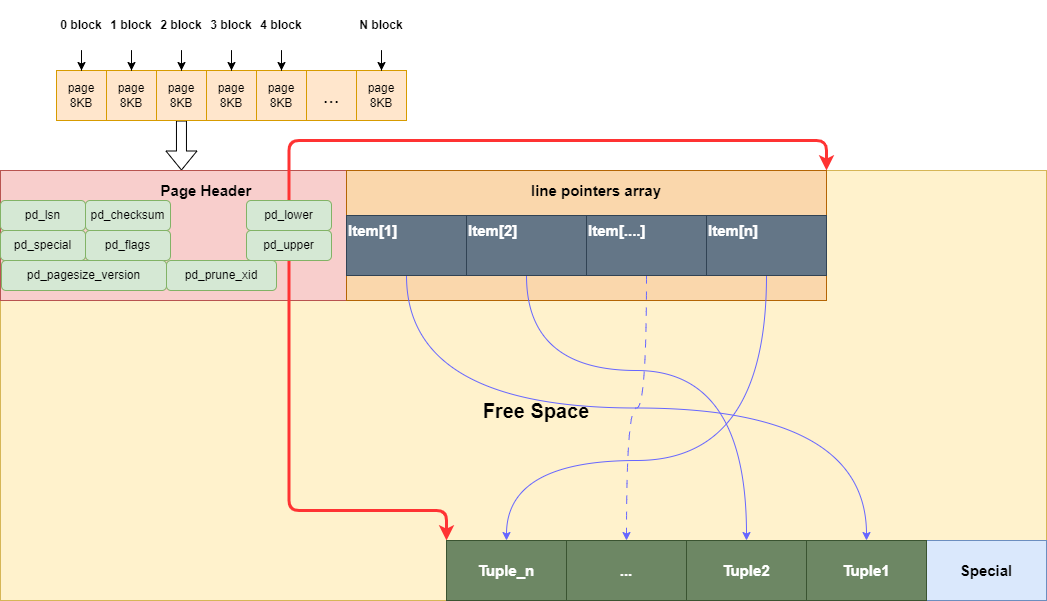
一张表/索引是磁盘上若干个段文件,每个segment又被切割为多个页面/块,默认8KB。这些页面用block number编号,从0开始计数一直向后,知道段文件的末端。页面作为Postgresql中的基本交换单元,非常重要。
Postgresql的页面主要可以划分为几层:
Page Header
和大部分的头部信息一样,页头中存放的都是这个页面的元信息以及重要的指针,具体有如下几种元信息:
pd_lsn
这个页最后一次修改对应的 WAL LSN,就是日志序列号(Log Sequence Number)。数据库崩溃恢复的时候,会按照页面的LSN号判断哪些WAL重放到哪里,哪些是新页面,哪些是旧页面。
pd_checksum
开启
data_checksums时,这里存页校验和。读页时会用它检查页有没有损坏。如果损坏,会在审计日志中有以下类似的内容:ERROR: invalid page in block 123 of relation base/16384/12345: checksum mismatchPG系统 不会自己去跳过这个 page 继续读,也不会自动从别处拷一份来替换。需要DBA手动介入处理(备库取表,reindex之类)。
pd_flags
页面标志位,主要功能有2个,有没有空槽位以及有没有 all-visible 之类的信息(借助VM)
pd_special
special 空间的起始偏移。heap 页一般 =
BLCKSZ(说明尾部没预留特殊区),索引页会往后挪一点,在尾部预留一块给 黑盒数据(opaque data),一块对通用的存储层来说,看不透,不理解的区域,只有具体的索引访问方法(B-Tree/GiST/GiN/SpGiST)才知道里面是什么。头部的这个指针指向的就是页面尾部的这一区域。pd_pagesize_version
页大小与版本信息(组合字段)
pd_prune_xid
这个页上还有潜在可清理的死元组时,记录相关 XID,帮助判定是否需要 prune/vacuum。
line pointers array
页面的data record的指针目录,每个指针对应一个槽位,编号从1开始,每个ItemID都有一个指向元组的目录项:
lp_off:该元组在页内的偏移;lp_len:元组长度;lp_flags:这个槽位的状态(正常/已删除/重定向等)。
每张表上的ctid(block_num, offset)中的offset,实际上指的就是ItemId的编号,可以粗略的理解为行号。ItemId 数组从页头往后长,每多一条记录,就在数组尾部再占一个固定大小的 slot。即使元组被删除,ItemId 也可能保留为 DEAD / REDIRECT 等状态,用于 HOT 链、vacuum 等。
页面内扫描所有元组时,不会直接扫元组区域,而是先按顺序扫 ItemId 数组(1..N),看看哪些槽位有效,再沿着偏移去读 tuple 。
Free Space
这部分比较好理解,就是页面内的剩余空间
可连续自由空间 = pd_upper - pd_lower这就是 FSM 里的这一页大约还有多少 free space 的来源。
需要注意的是,一个页面的剩余空间,还有一部分来自于dead tuple 在vacuum操作后留下的空洞,这部分空间会被复用。
VACUUM / autovacuum期间,pruneheap.c会进行页内清理以及HOT 链修剪。找出对所有事务都不可见、且索引也不再需要的 tuple,把对应 ItemId 标成 LP_DEAD 或 LP_UNUSED。对 HOT 链做 redirect / 合并等处理。在合适的时候调用 PageRepairFragmentation() 做页内挤一挤(vacuum full)。把还活着的 tuple 搬到页尾,排成连续的一块,更新每个 ItemId 的偏移,把 pd_upper 往后挪(靠近 pd_special),让中间形成一块连续的 free space(pd_upper - pd_lower 增大)。
HOT 链修剪
把一条 UPDATE 产生的“版本链”里已经没用的旧版本剪掉、缩短这条链,同时尽量回收页内空间。
HOT = Heap Only Tuple,只在 heap 页里排队、不改索引。
UPDATE t SET data = ... WHERE k = 1;表 t 上有一个索引 idx,只有 k字段上包含索引idx。假设这条 UPDATE 语句没改索引列(k 没变),PostgreSQL 将不会去更新索引,从而避免写很多 index page。取代的办法是,在 同一页上插入一个新版本 tuple。然后把旧 tuple 的 t_ctid 指向新 tuple 的 ctid。在索引的视角看来,索引里那条 entry 仍然指向“根版本”(root tuple),执行器拿到这条 heap tuple 后,会顺着 t_ctid 一直跟到当前可见最新版本。
Item[1] -> Tuple v1 (root, 有索引指向)
|
v (t_ctid)
Tuple v2 (heap-only)
|
v
Tuple v3 (heap-only, 当前最新)
这样做的好处是UPDATE 不改索引,写得更少,页内 locality 也好,代价是:有时候要顺着链多跳几步,才能找到最新可见 tuple,这个代价相较于修改索引当然显得微不足道。
当某个页上的 HOT 链越长、旧版本越来越多时,里面有些版本已经对所有事务都不可见(dead),继续留着它们,只会占用空间并且让后续访问多走几步。这种场景下,就需要页内清理(heap_page_prune_opt())来清理这些赘肉了。这个方法主要就干两件事,标记 & 删除:剪掉彻底没用的旧版本,缩短链:让从根走到“第一个还活着的版本”的路径更短。简化就是减枝+整理。
如果整个链上的所有版本都对所有事务不可见,Prune 会把对应的 ItemId 都标成 LP_DEAD / LP_UNUSED,这条 HOT 链就彻底消失了。索引那条 entry 未来在 VACUUM INDEX 里也会被清理掉。页内腾出一大块空间(后面可能配合 PageRepairFragmentation 挤到一起)。将来扫索引时不会再遇到这条链。
还有一种情况是,链上的前几段死掉,但是后面还有活着的版本
v1 (dead) -> v2 (dead) -> v3 (LIVE) -> v4 (LIVE 最新)prune同样也会干两件事情:重定向根槽位(LP_REDIRECT),把 ItemId 的 root 改成一条重定向,root 不再指向 v1,而是重定向到 v3,或者干脆让根槽位本身直接指向 v3。标记前面的 v1、v2 为 DEAD / UNUSED,等待空间整理时回收。变化后的链条:
Item[1] -> redirect -> Tuple v3 -> v4
(索引指向 root 槽位)这样一来,从索引过来,只需要root → redirect → v3 → v4,而不是再绕过一堆已经死掉的 v1、v2。页内也少了几条废版本,后面整理空间更容易。这就是HOT 链修剪(prune HOT chain)。
Tuples
元组区域位于pd_upper以下,pd_special 以上。Item[slot] 里有一个 lp_off,指向该 tuple 在页内的偏移,这个偏移的位置就是你看到的一个完整的 heap tuple(行头 + 列数据)。
lp_off
↓
+-------------------------------+
| HeapTupleHeaderData (行头) |
+-------------------------------+
| 列1 | 列2 | 列3 | ... | 列N |
+-------------------------------+
(都在页的 tuple 区里,从页尾往前长)都在页的 tuple 区里,从页尾往前长
行头信息
行头结构在源码里叫 HeapTupleHeaderData,逻辑上可以分四类信息:
事务相关字段:控制可见性
链指针:HOT / UPDATE 链
格式 & 状态标志:infomask / infomask2
布局信息:t_hoff + null bitmap
1. 事务版本信息
xmin
插入这个版本的事务 ID,表示从哪个事务开始,这个 tuple 存在于世界上。
xmax
对 DELETE:删它的事务写在这里。对 UPDATE:新版本出现时,旧版本的 xmax 记录更新事务。
t_field3
有时用作 cid(命令号,用于自事务内的可见性判断)。有时用作 xvac 等。
MVCC就是围绕这几个东西在转,某个快照看到这个tuple时候,会判断xmin 对我来说是不是已提交?xmax 是否为空 / 还未提交 / 已提交但在我之后?再结合 infomask 里的 hint bits,把已提交/已回滚的信息缓存下来,加速判断。
2. 链指针
也就是我们常说的ctid,ctid = (block, offset),指向这个元组的 当前版本。
对于从未被 UPDATE 过的行而言,ctid 就是自己:(本页, 本槽位)。对于 UPDATE 过的行,旧版本的 ctid 指向新版本,新版本再更新,链条继续往后串,这就是 HOT 链 / 版本链。索引 entry 永远指向链头那个 root 槽位,执行器拿到 root 以后根据 ctid 跳到真正可见的版本。
3. 状态标志及格式位图
t_infomask / t_infomask2这两个 16bit 字段里塞了一堆标志位,大致分三大类:
格式特征
HASNULL:这行有没有 NULL 列;HASVARWIDTH:有没有变长列;HASEXTERNAL:有没有 TOAST(页外存储)字段;HASOID:有没有 OID(老表可能有)
可见性 & 事务状态的
hint bitsXMIN_COMMITTED / XMIN_INVALID:xmin 的事务已经确定是提交 / 回滚了;XMAX_COMMITTED / XMAX_INVALID:xmax 对应事务已提交 / 已回滚等;还有锁相关标志(行级锁、共享锁等)。
这些 hint bits 是为了加速可见性判断,看 hint 就能知道这行早就 提交了,无需再查
clog。锁和多事务等辅助信息
标记这个 tuple 上是否有行锁。是否有多事务(多 session 共同锁定)等等。
你可以把这两个字段理解为这一行的格式特征 & 一些 MVCC 状态压缩成一串 bit,方便快速判断是不是常见的一些情况。
5. t_hoff + null bitmap
t_hoff(heap tuple header offset),表示从 tuple 起始位置到第一列数据开始的偏移,行头长度 + null bitmap + 可选 OID 等,都包含在这个偏移里,不同表,因为列数不同、有没有 OID 不同,t_hoff 也不同。
null bitmap)(t_bits[]),如果表中存在 任何一个可以为 NULL 的列,就会有这段。每一列对应一个 bit,1 = 这个列 不为 NULL,0 = 这个列为 NULL,后面的实际数据里 不会为它分配字节。bitmap 紧跟在 infomask2 后,长度 = ceil(natts / 8) 字节。
有了 t_hoff + null bitmap,PG 才知道从哪里开始是列数据,哪些列根本没有实际数据(NULL,只占一个 bit,不占字节)。后面列值的读取需要结合类型长度、对齐要求等来计算 offset。
行头后的列数据
每个列的存储形式大概分两类,固定长度类型和变长类型。定长类型长度固定,布局时需要按对齐规则(align)插进去,比如 4 字节对齐、8 字节对齐。定长类型包含int4、int8、float8、timestamp(有些平台)、bool 等。变长类型通常是 varlena 格式,前面带一个长度头(1/4 字节),后面跟实际内容,长度头里面还会携带 TOAST 的信息(压缩?页外?短格式?)。变长类型包括text、bytea、varchar、jsonb、数组等。有 NULL 的列 没有实际数据字节,只在 null bitmap 里记一个 0,实际并不分配字节。
对齐和列偏移计算
在页内存放 column 时,PG 会遵循类型的对齐要求。比如 int4 通常 4 字节对齐,int8/timestamp 有些平台 8 字节对齐。在行头后,PG 会这样安排,从 t_hoff 偏移开始放列1数据(int4),4字节,然后补齐到 4 的倍数(如果需要),再放 text 的 varlena。再根据 smallint 的对齐规则放列3。
列1:int4 -> 4字节对齐
列2:text -> varlena,对齐一般 4字节
列3:smallint -> 2字节对齐为了在需要时快速计算列 offset,PG 在内存级的 HeapTuple 结构里有一套 attcacheoff 缓存,避免每次都按类型/对齐重算一遍。
TOAST
当某些变长列(比如 text)太大时,PG 会把它们 TOAST 出去(页外存储)。tuple 里只保留一个“小指针”,指向 toast 表里的真正数据,这个小指针还是以 varlena 格式存储,infomask 里会置上 HASEXTERNAL 标志。这样,页内 tuple 不会被一个超大 text 把 8KB 撑爆,同一个大字段在某些更新场景下还可以复用 toast 行。
物理放置和逻辑访问
插入路径
插入新 tuple 时,大致流程是:
在 FSM 找一个有足够 free space 的 page
在该 page 内,用
PageAddItemExtended()计算 tuple 需要的大小(对齐后),在 page 的 tuple 区,从pd_upper往上挖出这么大一块,把HeapTupleHeaderData + 列数据一股脑 memcpy 进去。建立一个新的 ItemId(lp_off指向刚写入的 tuple 首地址,lp_len为长度),更新pd_upper/pd_lower。
删除/更新路径
DELETE / UPDATE(旧版本),只是把行头的 xmax / infomask 改一下,以及索引里可能标个 killed flag,不会立刻把 tuple 从页里物理搬走。于是,这条 tuple 仍然占着原本那块空间,只是从 MVCC 角度看,对所有事务可能已经 dead。对页内 free space 来说,这部分是 “潜在可回收空间”,但还没变成连续的 free space。
当 prune/vacuum 判断这些旧版本彻底无用了,就会把对应 ItemId 标成 LP_DEAD / LP_UNUSED,在有需要的时候(比如 free space 很碎时),调用 PageRepairFragmentation(),把“还能用的 tuple”打包搬到底部,让中间腾出一块连续 free space,之后会更新 pd_upper,这样 free space 真正就涨出来了。
ItemId 负责指路,逻辑顺序不等于物理顺序
因为有插入 / 删除 / prune / defrag,tuple 区里的元组物理顺序会乱。旧 tuple 在左边、新 tuple 往右边挤,中间还可能有迁移后的 tuple。但是在逻辑永远遵守:
for slot = 1..maxoff:
if Item[slot] is NORMAL:
follow lp_off -> 读这个 tuple也就是说,Item[1] 指向的物理空间不一定等于 Tuple1 靠左的那块空间
tuples的内容有些多而杂,总结一下:
页的目录区里有一个 Item[slot],里面记着
lp_off/lp_len;lp_off指向页内 Tuple 区 的某个偏移;从这个偏移开始,是一段完整的 heap tuple:
先是 HeapTupleHeaderData(xmin/xmax/ctid/infomask/null bitmap/t_hoff);
然后按对齐规则依次排所有
非 NULL的列数据(定长 + 变长/varlena/TOAST 指针);
所有这些 tuple 都是从页尾往前长,中间腾出来一块
free space;删除/更新只是在行头打 MVCC 标记,不马上搬走;
prune + defrag 才会把死元组挪走、compact 一下 tuple 区,把中间 free space 挤成一块,反映到
pd_upper上。
Special
special 区就是 每种访问方法(主要是索引)自己的私有尾巴。bufmgr、通用存储层只知道它从哪开始,但是不关心它长什么样子。只有 B-Tree / GiST / GIN / SP-GiST / BRIN 各自的代码知道怎么用。
Heap 页基本不用 special 区。对普通 heap 数据页来说,初始化时会把 pd_special 设成 BLCKSZ,也就是说:整个页尾没有额外保留空间,tuple 区从下往上长,free space 在中间,直到顶到 pd_upper <= pd_special。可以理解为在堆页面内,special 区一般是空的占位符,不用管。
B-Tree是一类常用的索引,它的每个 page 的尾部 special 区里有一块,BTPageOpaqueData通常包含以下字段:
btpo_prev/btpo_next左兄弟页 / 右兄弟页的 BlockNumber。B-Tree 横向链表(同一层页之间)就靠这俩维系。
btpo_level当前页所在层级。0 = 叶子页,1 = 叶子上面一层的内部页,2 = 再上一层以此类推。
btpo_flags一串标志位,这是根页吗?这是右端页吗?(upper bound)。这是元数据页 / deleted page 吗?
可能还有一些
version / vacuum相关的预留字段
还有其他种类的索引,都是以自有的方式去访问special区域。有兴趣的可以读读源码:GISTPageOpaqueData,GINPageOpaqueData。
这个区域存在的好处在于,不混在 Item/tuples 里,避免布局碎片。ItemId + tuple 区是通用的一套结构,关系型 heap、各种索引都依赖这套布局,调整 tuple 布局(插入/删除/压缩)会频繁搬数据。special 区放在固定的页尾,不会被普通 tuple 的插入/删除影响,不需参与 page 内碎片整理,对不同 访问方法 来说,sizeof(opaque) 是固定的,pd_special 也稳定。
附录
SLRU
在PG的数据目录结构的讨论中,我们在多个子目录介绍中提到了SLRU,我们就在这里把它掰开揉碎了。
其学名是
Simple LRU buffering for wrap-around-able permanent metadata
SLRU 是什么?它解决什么问题?
PostgreSQL 有大量跟事务有关的元数据,比如:
每个 XID 的提交/回滚状态(pg_xact / 旧名 CLOG)
子事务 → 顶层事务 ID 映射(pg_subtrans)
MultiXact 的 offset、members(pg_multixact)
提交时间戳(pg_commit_ts)
可串行化事务冲突跟踪(pg_serial)
LISTEN/NOTIFY 队列(pg_notify)
这些数据都拥有以下特点:
按事务 ID / MultiXact ID 索引(要支持 32 位 wraparound)
访问频率高,必须有缓存
但本身不是“普通表里的行”,不适合放在 shared_buffers 管理
所以 PG 实现了一个通用小框架:SLRU(Simple LRU)缓存:
内存里:维护一组固定数量的 page 缓冲区 + LRU 替换。磁盘上:对应数据存成一堆分段文件,放在 pg_xact/、pg_subtrans/、pg_multixact/... 这些目录里。各种子系统(clog/subtrans/multixact/commit_ts/notify/serial)都复用这套框架,每个实例有自己的目录 & 控制结构。你可以把 SLRU 理解为:专门为了“事务元数据”准备的一套 mini buffer pool。
SLRU 实例及其对应目录
访问流程
在 executor 里扫描一行,要判断 xmin/xmax 是否对当前快照可见,会触发一系列调用:
首先会查看 HeapTupleHeader 里的 xmin / xmax,如果是普通事务 XID,会调用 TransactionLogFetch(xid) 查看提交状态,间接访问 pg_xact 对应的 SLRU。如果涉及 子事务(比如 savepoint 后 rollback 部分),需要从 pg_subtrans 读出子事务的顶层事务 ID。通过 SubTransGetTopMostTransaction(xid) → SimpleLruReadPage_ReadOnly() 查 pg_subtrans 的 SLRU page。这一步在子事务多的时候会出现 wait_event = SubtransSLRU 之类的锁等待。如果行上有 共享锁 / 外键 等 MultiXact 记录。先通过 pg_multixact/offsets 找到成员列表位置,再到 pg_multixact/members 拿到多个事务的 XID 列表。
所以,看起来你只是 SELECT / UPDATE 一行,底层却可能在多个 SLRU 实例之间读来读去。
冻结与膨胀
因为事务 ID 是 32 位的,会 wraparound,所以pg_xact / pg_subtrans / pg_multixact 等 SLRU 的数据,也都是环形空间里的滑动窗口。VACUUM FREEZE 除了避免 wraparound,其实还有一个作用:让旧事务的数据可以安全丢弃,从而截断 SLRU 文件。当 oldestXmin / oldestMultiXactId 变化时,对应 SLRU 会截断前面的页,防止 pg_xact / pg_multixact 目录无限长大。如果 autovacuum 跟不上,多事务(MultiXact)使用又很重,会看到 pg_multixact 非常大、伴随高 IO 和 MultiXact...SLRU 的等待。
在PG13+之后的版本,可以用系统视图 pg_stat_slru 来看每类 SLRU 的统计:
SELECT name,
blks_hit,
blks_read,
(blks_read::numeric / NULLIF(blks_hit + blks_read,0)) AS miss_ratio
FROM pg_stat_slru
ORDER BY miss_ratio DESC NULLS LAST;
miss_ratio 高的,再结合 workload 分析,考虑调大对应的 *_buffers。
查询pg_stat_activity.wait_event_type = 'LWLock' 时,wait_event 字段里会出现
ClogSLRU/XactSLRUSubtransSLRUMultiXactOffsetSLRU/MultiXactMemberSLRUCommitTsSLRU/NotifySLRU/SerialSLRU
如果这种等待事件的记录很多,这个时候需要检查SLRU, 看是否缓存太小。滥用 savepoint / EXCEPTION(大量子事务)以及大量并发的 SELECT ... FOR SHARE/UPDATE / 外键检查(MultiXact 压力)都会造成等待事件的增多。
pg_multixact目录的大小要特别盯住,autovacuum 跟不上,就要优化。降低长事务 / 长期占锁,调整 autovacuum_freeze_* / autovacuum_multixact_* 参数,或者从业务上减少大规模读后锁行的模式。
SLRU 和 shared_buffers 的关系
SLRU 目前是独立于 shared_buffers 的一套结构,shared_buffers 用 clock-sweep / 2Q 等算法,管理用户表/索引的数据页。SLRU 是“simple LRU + 自己的一套页数组 + 自己的 LWLock”。
算法
这里主要包含以下三个概念
PostgreSQL shared_buffers中使用的 clock-sweep,一种近似于LRU算法的实现。顺带还有2Q
PG管理自身元信息的缓冲区 SLRU算法
一种被称作环形缓冲区(ring buffer)的数据结构,很多算法都是在这个数据结构上跑的
clock-sweep
LRU,Least Recently Used,最近最少使用算法需要每次访问都要把该页移到队头,同时找牺牲页时从队尾拿。这是这个算法的理想状态。在数据库几万甚至几十万 buffer 的规模下,如果维护一个严格的双向链表,频繁加锁 + 调整链表指针成本会变得很贵。那么clock-sweep算法就应用而生了。
clock-sweep的核心思想是,把所有 buffer 看成一个环(数组),拿一根指针(clock hand)在环上转圈,用一个小计数 usage_count 来近似最近是不是被用过。可以理解为在环形结构上的简化 LRU。
对于每个buffer而言,clock-sweep算法维护两样东西,usage_count:一个很小的整数(比如 0~5,具体实现略有差异),pin count / is dirty / is valid 等状态。一个计数,一个计状态。当访问命中一个buffer的时候
if usage_count < MAX_USAGE:
usage_count++意思就是,最近这个buffer被引用,所以使用计数+1,这意味着该buffer对驱逐的抵抗力又增加了一层。
需要找一个牺牲页(evict)时,指针从当前位置开始向前扫(顺着数组 / 环形链表走)。对当前指向的 buffer 做检查,如果 usage_count > 0,说明最近用过,usage_count--(给它一次机会),指针移动到下一个 buffer;如果 usage_count == 0,如果没被 pin,且脏页能被刷盘/已经干净,那就选它做 victim;否则跳过,继续转。如果扫了一圈还没找到,就再扫一遍(这时大部分 usage_count 都被减到 0 了),总能选到一个。简单理解就是,先把所有页的 usage_count 减到 0,然后从中找一个没被占用的下手。
clock-sweep不用维护复杂链表;就是一维数组 + 一个指针,简洁意味着开销稳定、实现简单,近似 LRU,命中率大多场景够用。缺点在于不是精确 LRU,尤其是模式比较怪时(比如全表扫描 + 热点小表混在一起),很难精确区分数据热点。环很大时,扫描一圈可能开销不小,这对于垂直扩展PG架构是个挑战,当然,PG 里还有各种优化,比如分多条策略队列、freelist 等。
或许有些疑惑,为什么要有BM_MAX_USAGE_COUNT = 5这样一种设置呢?不但有上限,而且还是非常小的数字5呢?
原因在于,特别热的页会被访问很多次,usage_count 能涨到几百、几千,clock-sweep 每转到它一次,只能 usage_count-- 一下,也就是说,要想真正有机会把这页淘汰掉,需要把它的 usage_count 一点点减到 0,当 shared_buffers 很大、很多页都很热时,找一个可淘汰页的成本 ≈ NBuffers \* 平均 usage_count,会非常夸张。PG 社区的 slide 就直接写过:最坏情况是 O(NBuffers * max_usagecount)。于是PG的做法别让 usage_count 长得没完没了,给一个小上限,5 就够了。
这样一来,即使某页超级热,把 usage_count 顶到 5,也就是最多能“躲过”整个 buffer cache 被扫 5 圈,再不被访问的话,也会慢慢减回 0,然后被淘汰。
为什么选择5呢?我们可以讲5次扫描看成如下状态
0:马上可以淘汰
1:很冷
2–3:中等热点
4–5:非常热门
这个粒度已经足够 clock-sweep 区分常用页和一次性页了,再多几个档位,大多数 负载下命中率收益有限。再往上加只会增加 CPU 成本。上限越大,最坏情况下 clock-sweep 为了把一页从 max 减到 0,需要扫的圈数越多。有些意见甚至任务目前的5已经有些大了,经常看到所有页都是 5,然后算法表现像昂贵的随机替换。
综合下来,max_usage_count=5这个设置,是一个经验性的折中方案,足够区分冷热,热门页可以挺过多轮淘汰,同时又能把 clock-sweep 的最坏成本限制在 5 × NBuffers 这个级别,不至于爆炸。
第二个贴士是,这个转圈扫描的操作,什么时候会被触发。
其实也简单,和人一样,肚子饿了就要吃饭,PG系统需要一个新的buffer,但是手上又没有可用的buffer的时候,就会触发扫描。具体情况就是 buffer miss发生的同时,freelist也空了。
PG 的 shared_buffers 本质是一个大数组,逻辑上当成表盘,有个全局原子变量 nextVictimBuffer,就是 clock hand,下一个要考虑的 buffer 位置。从 nextVictimBuffer 开始往前走,一直走到找到一个可以淘汰的 buffer,refcount == 0(没人 pin)而且usage_count == 0(最近不怎么用),以上两个条件有一个不符合就继续走、绕一圈,必要时做多圈,把 usage_count 一路减到 0。具体源码参考 StrategyGetBuffer()和ClockSweepTick。
在实例刚启动时,很多 buffer 还没用过,大部分 miss 都能从 freelist 拿空槽位,不太需要扫描。跑到一段时间后,shared_buffers 里基本全是曾经被用过的页,freelist 越来越少,同时每次 miss 都需要选择牺牲者,自然就频繁走 clock-sweep。
有持续新页面进入的情况下也会导致扫描操作增加,进而引起负载升高。不断全表扫描 / 大范围顺序扫大表(虽然有 buffer ring 减轻,但总有一部分会落在主 cache),持续往大表末尾插入(不断扩展新 block),大量随机访问很大的 B-tree,很多页都是第一次访问。
热页面太多,这种极端情况下,就是负载让每个页都变成 usage_count 接近 5。每次 clock-sweep 扫过去,可能要走好几圈才能找到真正 usage_count=0 的 victim。CPU就纯纯的被浪费了。这就是上面说过的,max_usage_count=5太大了,空费了很多CPU资源。
2Q
结算2Q算法前,要先了解一个概念,就是一次性扫描污染,我们先假设一个理想的简单 LRU 缓存:
缓存容量:只能装 3 页
当前热点工作集:页
A、B实际的访问情况如下:绝大多数时间,都在反复访问页面A,B。偶尔会有一张巨大的表被全表扫描,(C,D,E,F,G...)。每页只读一次。
在简单的LRU策略下,最近访问过的页面会排在队头,最久没用的在队尾,队尾页面等待淘汰。上面的情况则可以概括如下:
访问序列
A,B,A,B...A,B, C,D,E,F,G...., A,B,A,B...第一段缓存内的三个槽实际是
[A,B,NULL]缓存是够用的,除过第一次有磁盘IO外,其他时候都是缓存命中的。
这个时候第二段来了,就是一次大扫描。按照LRU算法,缓存内的过程如下:
访问C
[A,B,C]访问D
[B,C,D]A页面被淘汰
访问E
[C,D,E]B页面被淘汰。
下面的过程类推,一路下来,原本常驻的页面A,B都被冲走了。直到顺序扫描完毕,热点A,B页面才能回到buffer内。
这样做的结果就是访问A的时候,它已经不在缓存内,需要再次和磁盘产生交互。更糟糕的是,如果访问发生大表顺序扫描期间,会反复的争抢缓存槽位置,多次的和磁盘产生交互。这实质上是将热页面硬生生的变成了冷页面。这就是所谓的一次性扫描污染了缓存(Cache Pollution)
数据库系统中特别容易出现这种缓存污染的场景,比如小表/热索引是常用的热数据,批处理报表,全表统计往往都是周期很长的一次性大表顺序扫描,OLAP全表扫描完毕后,OLTP业务开始访问,又要将小表和热索引再次加载入缓存。解毒方法就是2Q算法。
2Q 是另一类比较经典的替换算法,用来解决简单 LRU 被一次性扫描污染的问题。其核心思想是把缓存分成两个队列(有的还有第三个):
Q1:新访问对象/只访问一两次的页面
Q2:保存被多次命中的热点页面
第一次进入缓存的页面会被分配到Q1,如果在Q1期间再次被访问则会被升级放入到Q2中。淘汰的时候会优先从Q1尾部进行,这样一次性扫描污染就会在Q1队列被消化掉,不会对Q2队列中的热点页面进行驱逐。
这个思想在内核,其他类型的数据库上都有实现。一些变种,比如ARC也类似,理解原理即可,实现细节兴趣可以查看源代码。
SLRU
附录的第一节已经介绍了SLRU,这种区别于SHARED_BUFFER的小规模精确LRU的算法特点如下:
buffer数量较小(10-100页),各个实例独立,互不影响(pg_xact,pg_subtrans,pg_multixact)。
简单直接,就是维护一个最近使用计数器
一个典型的Simple LRU逻辑一致如下:
数据结构上,Simple LRU维护着一个固定大小的数组slots[N],每个槽存储一个页面(page)。除此外,slot还存储着page_number这个页面是第几号(逻辑编号)。lru_count,最近访问的时间戳。dirty/in_use/io_in_progress等其他flag。
选择牺牲对象的办法也简单直接,由于N不大,线性扫描即可,跳过标志位是in_use/io_in_progress的slot。在剩下的里面找到lru_count最小的一个。和clock-sweep相比,SLRU更适合几百个的slot,线性扫描的成本非常低,命中行为更接近真正的LRU。
ring buffer
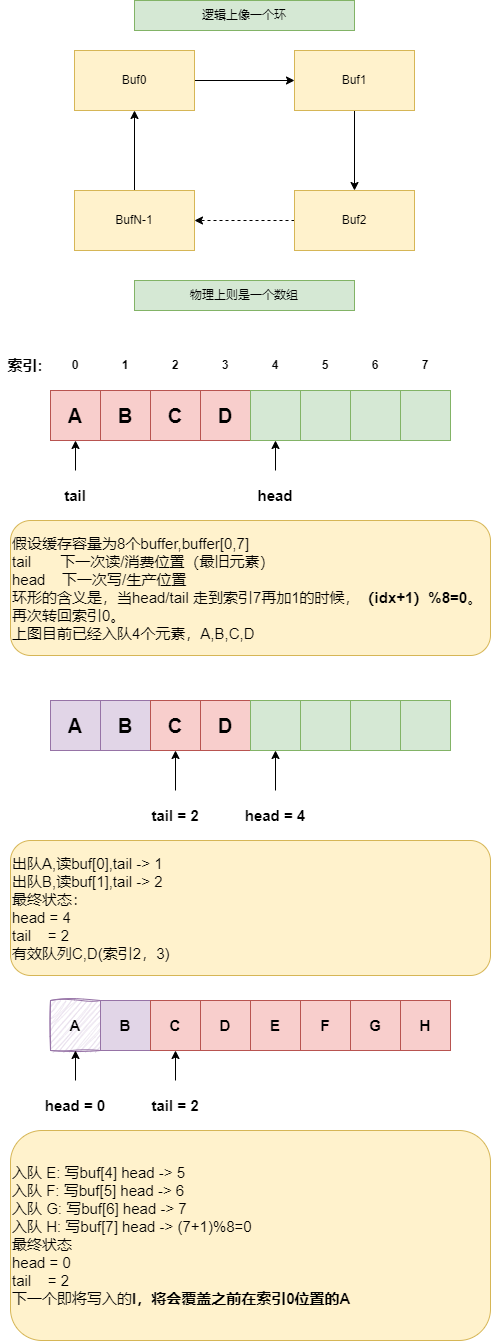
环形缓冲区是一种基础数据结构,底层是一个固定长度的数组 buf[N],有两个索引,head负责下一次写入(生产)的下标,tail负责下一次读出(消费)的下标。每次移动head/tail都是取模(index+1)\% N,就和钟表的指针一样,逻辑上都是绕一圈。它是一个FIFO队列的实现,广泛用于驱动/网卡收发队列,日志缓冲区,音视频及流数据消费。
环形缓冲区的操作如下:
入队(enqueue)
首先判断队列是否已经充满,常见的方法是,(head + 1) \% N == tail,则表示满(少用一个槽区分,或者另存一个
count)。如果不满则 buf[head]=value,同时索引前移head = (head+1) \%N。出队(dequeue)
判断队列是否为空,head == tail或count == 0,如果不为空,value = buf[tail],同时 tail = (tail + 1) \% N。
这种数据结构的好处在于,不需要移动元素,单生产者和消费者可以做到无锁(head 和tail分别由不同的线程独占更新),效率较高。访问模式是缓冲友好的(cache-friendly,顺序访问数组)。
环形缓冲区满了一般有以下操作策略:
满了就阻塞等待
这是典型的
生产者-消费者队列,最常见,最科学的用法。这种策略不丢数据,也不能覆盖数据。同理环形缓冲区空了,消费者线程也要等待
not_empty。是不是有些熟悉?信号量的实现就是这个策略。
满了就覆盖最旧的数据
如果新数据比旧数据更重要,而且允许丢弃一些旧数据,只要不阻塞生产线程,有些生产者甚至不允许阻塞,比如中断处理,实时音频回调。具体的操作是,
tail向前挪一格,head写入新数据。这种策略下,生产者永远不被阻塞,代价就是数据可能被覆盖,消费者看到的是最近一段时间的窗口。我们看到的各类实时监测曲线,最多显示近期的N个点,旧的直接滚出环形缓冲区。
满了就丢掉
更极端的一种策略,满了就直接drop,生产者继续干自己的事情。典型的场景就是日志系统里,瞬间的暴增往往是重复的,上层可以容忍部分丢失。同样的,这种策略不会阻塞生产者,但是也不会覆盖旧数据,仅仅是drop生产者现有的新数据。
满了触发扩容/回退逻辑
这个策略已经超出纯ring buffer的概念,只是一种策略,在环形缓冲区满了,临时扩容一个更大的缓冲区,或者把剩下的数据写入到磁盘中,变相的做一个慢队列。还有一种更严格的办法是向生产者返回错误码,上游根据错误做降级操作。
结合shared_buffer的clock-sweep实现,PG的ring buffer更像满了就覆盖旧数据这种策略。
在顺序扫描/VACUUM/bulkwrite这样的模式下,PG会给这个进程一个buffer access strategy,BULKREAD策略内部使用一个环形缓冲区,固定数量的buffer slot,专用于扫描。这个环形缓冲区位于shared_buffer中,目的是限制这个大型顺序扫描对全局buffer池的影响,避免热点页面被冲掉。扫描分配N个buffer组成一个ring,每次读取新块就占用ring里面的下一个buffer,把就内容覆盖掉。由于是一个进程在调用这个环形缓冲区,所以不存在环形缓冲区满了之后的各种生产线程的策略,它的循环逻辑是,扫描器处理完当前buffer里面所有的buffer,然后释放这个buffer头部的pin flag,ring指针走到下一个槽位,将其复用来读下一个block。