

Postgresql的内存架构
内存作为磁盘和CPU之间的中间层,是系统性能的重要部分,了解PG的内存架构,有助于数据库的性能分析。
一个PG实例的内存主要分为两大部分,共享内存及每个后端进程的专有内存。
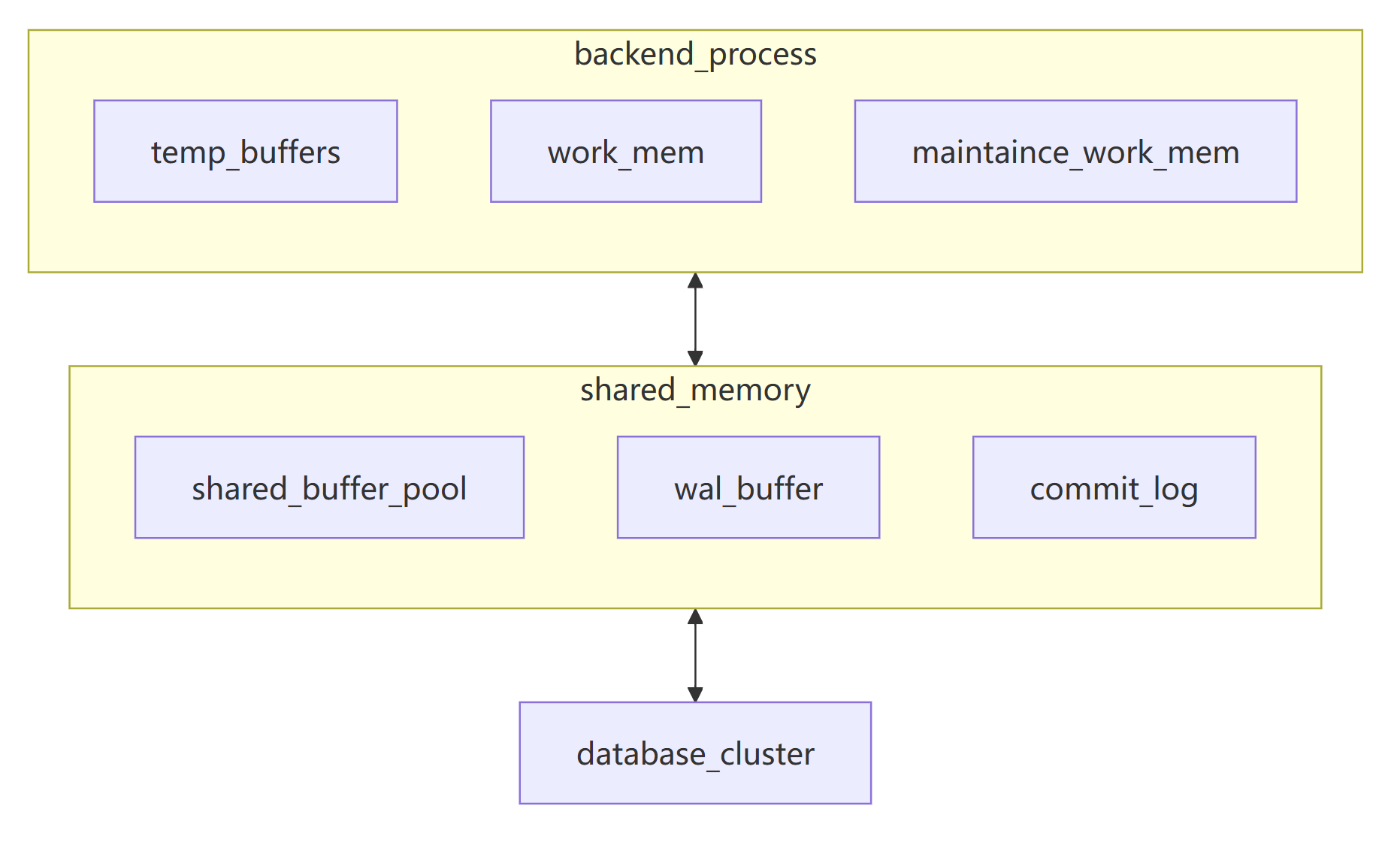
后端进程的内存
需要注意的是,上面图中的 temp_buffers,work_mem,maintaince_work_mem,这些都是参数(GUNS),是每个后端进程中都有可能使用到的按照任务类型进行分类的内存使用种类,它们之间并没有物理隔离。
在操作系统看来,一个 backend 本质就是一个 Linux 进程,典型内存布局大概是:

上面几个内存概念都是同一个 backend 进程的虚拟地址空间里的不同区域。在OS看来,后端进程的内存就是进程+映射进来的共享内存+其他内存种类。
PG后端进程有自己的内存上下文结构,这意味着和其他程序可以随意malloc/free不同,PG里的内存操作,就要按照PG的规则来,具体而言,PG提供了MemoryContext 层次结构,一棵树状的内存池。
其核心的头文件有两个 memutils.h和palloc.h。而实现则主要在mcxt.c(MemoryContext 通用框架)和aset.c(申请内存)
后端进程的内存上下文结构大体如下
TopMemoryContext ← 进程级,存活整个 backend 生命周期
├── ErrorContext ← 报错时格式化 error message
├── CacheMemoryContext ← relcache/syscache 等长期缓存
├── MsgContext / MessageContext ← 网络报文解析用 (每条报文重置)
├── TopTransactionContext ← 每个顶层事务/子事务使用
│ ├── QueryContext ← 每条 SQL 的解析/规划结果
│ │ └── ExecutorStateContext ← 执行器状态、算子中间结构等
│ └── PortalContext(s) ← 游标/extended query 用
└── 其它长生命期 context使用这种层次化内存管理的好处在于,普通程序如果用 malloc/free,很容易忘记 free 或 free 错对象。而PG MemoryContext把谁负责释放提升到语句级(statements)/事务级(transaction)和会话级(session)。SQL 执行完,语句级 context reset 一下,而不用关心里面具体分配了多少小对象。事务结束,则事务级 context delete 一下,子事务的内存会被一并处理。这样做的好处在于,内存泄漏风险大幅降低,错误回滚时也好处理:直接把某些层级的 context 全部删掉。而会话级/进程级内存则会一直存在,不被误删,这样可以减少重复销毁及创建带来的开销。
了解完后端进程的内存结构后,我们详细讨论一下上面的三种后端进程中的内存内容
temp_buffers
temp buffers是每个backend 的本地缓冲池Local Buffers,表示这个会话最多能有多少个 临时表页面 缓存在本地 buffer 里。
localbuf.c中实现了临时缓存区。当会话第一次真正用到临时表时,会调用 InitLocalBuffers(),依据 num_temp_buffers 申请一块大内存,其中包含LocalBufferDescriptors(每个 local buffer 的描述符)和LocalBufferBlocks(实际存放 8K 页的连续内存)。这块内存是通过 malloc 或 MemoryContextAllocHuge(TopMemoryContext) 拿的,跟 shared_buffers 完全分离。
temp_buffers 是 per-backend 的,每个连接最多有这么多 local buffer。还需要注意的是,第一次用临时表时才按 temp_buffers 一次性分配。这个区域仅对当前的后端进程可见,这意味着更好的隔离性。
work_mem
有一个比较容易搞错的概念,就是work_mem是每个后端进程使用的工作内存上限,这是错误的。正确的理解是每个后端进程中的每个算子、每次操作使用的工作内存上限。这意味着你观察到的后端进程很可能占用的工作内存不止配置中work_mem那么大,而是要乘以一个倍数。work_mem 不是一个固定的 pool,而是 每个 sort / hash / material / bitmap 等节点的内存预算。一条复杂 SQL 里可能有多个 sort/hash 节点,每个节点都可以各自吃到 work_mem。如果超了,就溢写磁盘临时文件(BufFile)。
work_mem主要存放排序及哈希的结果。排序 tuplesort.c/nodeSort.c。哈希 nodeHash.c/ nodeAgg.c。
这个参数往往和max_connection相关,这个内存区域和共享内存物理隔离,这意味着不合理的work_mem是会造成非常糟糕的后果。估算内存用量的时候要结合语句explain进行内存消耗计算,而不是仅仅使用max_connection × work_mem。实际上,保持较少的max_connection,和一个相对大些的work_mem是不错的选择,更多的连接交给pgbouncer这样的连接池去处理,数据库侧则集中力量处理当前进来的会话,降低响应时间,增加吞吐量。
maintance_work_mem
简而言之,维护操作专用的大号工作内存。VACUUM、CREATE INDEX、REINDEX 等维护命令的内存预算。
有维护类操作的时候,系统不会选择work_mem参数,而是选择maintance_work_mem,autovacuum 再覆盖一层 autovacuum_work_mem,也是同一套路。
往往维护操作需要手动执行,这个时候可以看情况手动调整会话中的这些参数,更快的完成操作。比如
set maintance_work_mem = '4GB'共享内存
postmaster 启动时用 CreateSharedMemoryAndSemaphores() 申请了一块连续的大段内存,再由各个子系统通过 ShmemInitStruct/ShmemInitHash 在里面切自己的“分区”。再由各个子系统通过 ShmemInitStruct/ShmemInitHash 在里面切自己的“分区”。所有的后端进程都会把这段内存attach到自己的地址空间。
从主入口的源码可以看出:
void
CreateSharedMemoryAndSemaphores(void)
{
Size size;
/* 计算整段 shared memory 总大小 */
size = CalculateShmemSize();
/* 调用 PGSharedMemoryCreate 向 OS 申请一段共享内存 */
PGSharedMemoryCreate(size, &shmid, &UsedShmemSegAddr);
/* 初始化 LWLock / Spinlock / 信号量 等同步原语 */
InitLWLocks();
CreateSharedMemoryLock();
...
}
先看计算大小的函数CalculateShmemSize
Size
CalculateShmemSize(void)
{
Size size = 0;
size = add_size(size, CreateSharedMemoryStateSize());
size = add_size(size, BufferShmemSize()); // shared_buffers
size = add_size(size, LockShmemSize()); // 锁管理
size = add_size(size, ProcArrayShmemSize()); // 活动事务数组
size = add_size(size, XLOGShmemSize()); // WAL 缓冲
size = add_size(size, CLOGShmemSize()); // 事务提交状态缓存
...
size = add_size(size, AddinShmemSize()); // 插件申请的 shmem
return size;
}
这里你能看到几个关键模块:Buffer、Lock、ProcArray、WAL、CLOG、Addin(扩展)...
接下来就是创建共享内存了,PGSharedMemoryCreate在不同平台对应不同实现。
PGShmemHeader *
PGSharedMemoryCreate(Size size, int *shmid, void **shimaddr)
{
/* shmget(size) 申请一段系统 V 共享内存 */
id = shmget(IPC_PRIVATE, size, IPC_CREAT | IPC_EXCL | S_IRUSR | S_IWUSR);
/* shmat() 把这段内存映射到当前进程地址空间 */
ptr = shmat(id, RequestedAddress, 0);
/* 在开头放一个 PGShmemHeader 头部 */
hdr = (PGShmemHeader *) ptr;
hdr->totalsize = size;
hdr->freeoffset = MAXALIGN(sizeof(PGShmemHeader));
...
return hdr;
}
以后所有模块再在这段内存里“分配子块”,都是从这个 PGShmemHeader 的 freeoffset 往后挪。
那么共享内存内部是怎么分区的?PG 在共享内存中维护了一个目录,叫做ShmemIndex,这里可以理解为名字:地址+大小的哈希表。
在 CreateSharedMemoryAndSemaphores() 之后,会调用 InitShmemAllocation,其中会创建ShmemIndex
void
InitShmemAllocation(void)
{
PGShmemHeader *hdr = ShmemSegHdr; // 就是 PGSharedMemoryCreate 返回的那块头
ShmemSegBase = (char *) hdr; // 基地址
ShmemBase = (void *) hdr;
/* 第一块:ShmemIndex 哈希表本身 */
ShmemIndex = ShmemInitHash("ShmemIndex",
SHMEMINDEX_NSLOTS, SHMEMINDEX_NSLOTS,
&info, HASH_ELEM | HASH_BLOBS);
}
ShmemInitHash 本身也是调用 ShmemAlloc() 在共享内存里申请一块空间,然后建立 hash 表结构,用于记录后续所有 named 区域。
那么各模块如何登记自己的共享内存呢?以 Buffer 管理为例,InitBufferPool()
v14及其之后版本使用的是 BufferManagerShmemInit()
void
InitBufferPool(void)
{
bool found;
BufferDescriptors = (BufferDesc *)
ShmemInitStruct("Buffer Descriptors",
NBuffers * sizeof(BufferDesc),
&found);
BufferBlocks = (char *)
ShmemInitStruct("Buffer Blocks",
NBuffers * (Size) BLCKSZ,
&found);
...
}
等级过程如下:
在 ShmemIndex 里查找名字为
"Buffer Descriptors"的条目,如果没有,就分配size字节、记录在 ShmemIndex 中,found = false;如果有,就直接返回之前分配的地址(用于子进程 attach 时),found = true。实际分配使用
ShmemAlloc():从PGShmemHeader.freeoffset往后挪。
类似的,其他子系统的初始化模块中有
LockShmemInit()(在 lock.c)里有:
ShmemInitStruct("LOCK hash", ...)
ProcArrayShmemInit()(在 procarray.c)里有:
ShmemInitStruct("Proc Array", ...)
XLOGShmemInit()(在 xlog.c)里有:
ShmemInitStruct("XLOG Ctl", ...)
整段共享内存内部,其实是很多块通过名字登记的结构体/数组。每个模块用固定的字符串名当 key,通过 ShmemIndex 找到自己的那块区域。

PG的双缓存机制
Postgresql在Linux系统上采用双缓存机制,PG 自己的 shared_buffers(共享缓冲区),以及内核的 OS page cache(页缓存)。这意味着,同一表页面,常常会在两层各存一份,看来重复存储。但是期间各自承担的责任,生命周期和算法完全不同。
建设我们的系统是Linux,磁盘格式采用ext4,PG则默认bufferd/IO。
读路径
后端进程需要读取一个页面的时候,即执行器中的SeqScan/IndexScan节点要读页面时,会调用buffer manager,根据 (relfilenode, forknum, blocknum) 在 BufferDescriptors 里查找这个块是否已经在 shared_buffers。
找到了 → 直接用,这一步完全在 PG 内部内存,不经过 OS 读磁盘,就是我们常说的软查询。
没找到 → 需要把这个块从磁盘读进来。具体过程如下
buffer manager 会选一个
shared_buffers里的空闲或可替换的 buffer slot,把这个 slot 和目标(rel, block)绑定,然后调用smgrread()→ 最终落到pread()/read()系统调用。
接下来,PG 的DBsystem和OSsystem会产生交互,具体就是read() 调用发生时,
如果OS page cache中已经存在这个文件块,内核直接把 page cache 里的数据拷贝一份到 PG 的
shared_buffers对应 buffer 中。这就是双缓存的一份在 PG,一份在 OS。如果 OS page cache中没有,内核从磁盘读这个块到自己的页缓存,然后再从页缓存拷贝一份到 PG 的 shared_buffers 页面,以后别的进程(甚至别的程序)访问这个文件块,也能命中 OS 页缓存。
读路径一定会经过 OS page cache,那是 read() 的默认行为。PG 的 shared_buffers 是在此之上的第二层专用缓存,主要解决的是 PG 自己的并发控制与可见性问题。
写路径
写的过程稍微复杂点,但思路还是“两层缓冲 + WAL 保证持久性”。
当你执行 UPDATE/INSERT/DELETE,后端先把需要修改的页面读到 shared_buffers,在 shared_buffers 中 直接改那块内存(行记录、元组头、可见性位等),把该 buffer 标记为 dirty(脏页)。同时生成对应的 WAL record,写入 WAL buffers,然后刷 WAL(具体策略根据 synchronous_commit等参数决定)。这个时候,脏页存在于shared_buffers,对应的 WAL log 已经(或即将)刷入 WAL 物理文件(通常 fsync 在另一套 I/O 路径里)。
后端本身一般不立即把脏页写回数据文件,而是靠后台进程bgwriter进行刷写,它会周期性扫描 shared_buffers,挑一些脏页提前写出,目的是 平滑写 I/O,避免 checkpoint 时一次性刷太多造成抖动。另外一个刷写进程是checkpointer,到了 checkpoint 时刻(checkpoint_timeout 或 WAL 条数阈值等),必须保证之前某个 LSN 前的所有脏页都已经被写出并 fsync,会较集中地对大量脏页做 write() + fsync()。
write()对文件描述符的操作为,数据先写到 OS 页缓存里,标记为 页缓存里的 dirty page,之后会进行脏页刷盘,内核后台 flush 线程,或显式调用 fsync() / fdatasync() / sync_file_range() 之类。
PG的写路径大致如下:
shared_buffers(脏) → write() → OS page cache(脏) → flush → 磁盘
双缓存的深层次原因
初看起来,肯定有种浪费资源的感觉,为什么一份数据要在 shared_buffers + OS page cache 各一份,管理上下文也有消耗。
根本原因在于,两种缓存解决的根本就不是同一个问题。
PG 需要自己控制的数据结构和并发语义
在 shared_buffers 中,每个 buffer 不是单纯的裸 8KB 数据,
BufferDesc header中有以下内容:
buffer tag(对应哪个 relation、哪个 block);
引用计数(pin count);
使用计数(clock-sweep 算法);
脏标记、IO 中标记(正在被读写);
防止多个 backend 并发修改同一页的元数据;
与 MVCC / 可见性控制高度耦合。
这些东西 OS page cache 并不具备相应的能力,没法直接为PG提供处理能力。PG不得不拥有一套自己逻辑的buffer,才能配合PG内核快速定位一个页面是否已在缓存中,做好 buffer pin/lock、并发读写控制,以及维护自己的替换策略(clock-sweep)和统计信息。
OS 缓存则服务于整个系统和其他进程
OS page cache 的存在有几个好处,多个进程共享,不只是 PG,还有 cp, rsync, backup 程序 等。文件系统元数据、目录项等也依赖页缓存。即使某些数据不在 shared_buffers 中,命中 OS cache 比直接命中磁盘快多了。
双缓存相关的调优参数
第一个当然是shared_buffers多大。
shared_buffers 如果太小,PG这个层面的命中率就会很低,大量的页面在 buffer manager 里走不通,每次都要和OS交互。shared_buffers 太大的话,OS page cache 将会变小,其他进程I/O抖动(缓存 WAL、系统目录、程序本身、其他服务),自己访问文件也会更慢。
这个参数一般推荐在内存的 1/4 ~ 1/2 。
另外一个参数是effective_cache_size,这个参数不是实际分配内存,而是告诉优化器,系统 + PG 大概有这么多可用 cache 用来放数据页。一般的配置规则是shared_buffers + (OS 内存中会被当作 IO Cache 使用的那部分)。这样优化器在估算走索引 vs 全表扫时,会合理地认为:很多数据其实已经在 OS + shared_buffers 了,不一定每次都下盘。
Linux 的readAhead机制
顺序扫描seqscan,即大量连续读一个表的时候,PG 这层是按 block 顺序发起 read(),OS 会识别这种模式,启动 readahead:提前把后续几个块读入页缓存,PG 再去读这些块时,既可能命中 shared_buffers,也可能命中 OS cache 后再 copy。对于纯顺序大表扫(尤其是 work_mem 不够、临时文件多时),OS 的 readahead 其实非常重要。
话说回来,PG是否可以绕开OS cache,进行直接IO?理论上是可以的,但是PG是开源软件,这样做需要克服跨平台的复杂度,readahead、写合并、块对齐等都要自己重新做一遍。这对于一个非商业机构的工作量都是巨大的,在权衡性能与实现的工作量上,目前保持buffer I/O是一个稳妥的决策。