Postgresql进程架构
进程作为操作系统中的重要概念,包含了程序代码以及相关的运行环境。每个进程在操作系统中都是独立的,具有自己的地址空间,并可以运行。Postgresql采用多进程架构,进程之间相互隔离,提高了安全性和稳定性。下面逐一介绍各种进程。
主进程(Postmaster)
Postgresql的主进程传统上被称作Postmaster。就像这个形象的名称一样,作为PG的大boss,该进程是绝对不会干刷脏,复制这类蓝领工作的。postmaster主要负责以下工作:
监听连接。
fork()/exec()出会话后端(每个连接一个进程)postmaster源码的顶部注释开篇就写明前端程序连接到postmaster,然后由它立刻fork出后端进程(backend process)来处理连接。请求认证由子进程负责,一旦认证成功,该子进程就会变为后端进程。这样做的好处是避免主进程阻塞,即使当前子进程由于认证卡住,不影响postmaster处理其他连接请求。
由两个相关的参数会限制子进程的创建行为,以防止资源耗尽。一个是
max_connection,postmaster 在BackendStartup前后会看并发/配额并作出拒绝或延迟,防止在认证阶段资源就被耗尽。事实上,PG默认的100参数值是有道理的,因为现代数据库服务器拥有100核心以上的CPU服务器并不多,至于空闲连接PG认为客户端应当保持克制,换句话说连接管理的事应当在客户端而不是服务端。对此可以前置pgbouncer这样的连接池对连接进行管理,充分利用连接复用,增加系统吞吐。另外一个参数则是
authentication_timeout,这个参数一目了然,就是防止限制认证阶段的半开连接长期占用资源的。这两个参数实质上预防了DoS风险。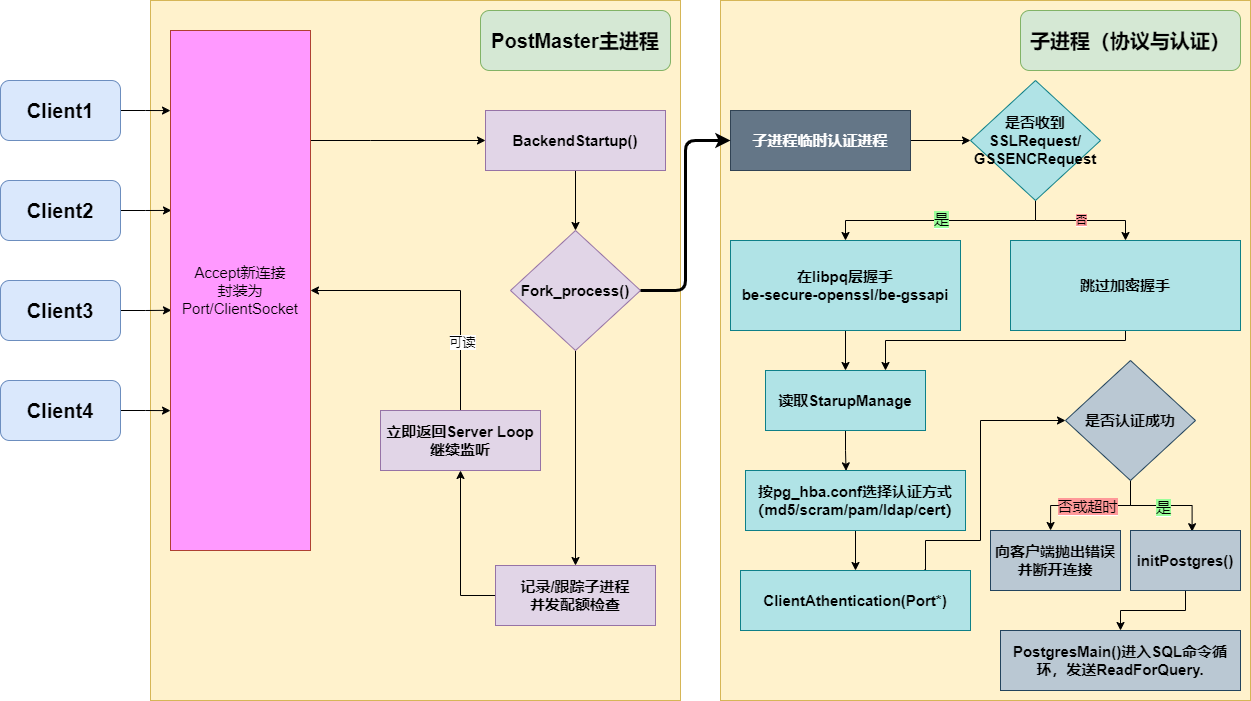
全局性的运维操作。PG实例的启动与关闭。postmaster本身不会直接进行操作,它只是在合适的时候派生子进程去操作这些事情。在某个后端进程崩溃后,也负责重置系统。
SIGHUP 重载配置,SIGTERM/INT/QUIT 三种关机语义。这些都是通过postmaster进行管理。同时会维护
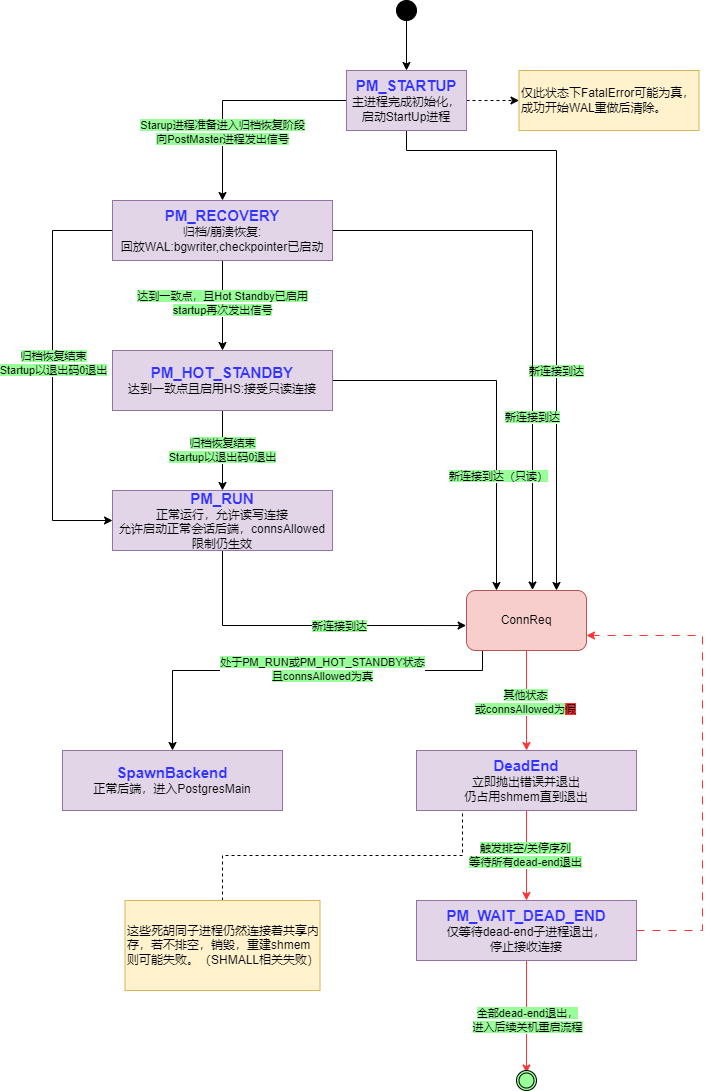
postmaster.pid文件,让pg_ctl工具识别实例及其端口,socket目录等等。下面详细说说全局性的运行步骤:PostgreSQL 启动、关闭、恢复的状态机
当 PostgreSQL 启动时,Postmaster(主进程)会先完成一些初始化工作,然后进入 PM_STARTUP 状态。接下来,启动进程会被启动,做一些准备工作,比如读取数据库的控制文件。
如果是正常启动或者恢复崩溃后的数据库,启动进程会执行 WAL(Write-Ahead Logging)回放,确保数据库恢复到一致状态,并且会在完成后退出,Postmaster 切换到 PM_RUN 状态。
如果是归档恢复(Archive Recovery),这个过程会更慢,并且支持热备份(Hot Standby)。启动进程在准备好进行归档恢复时,会通知 Postmaster 进入 PM_RECOVERY 状态,这时会启动 后台写入进程(bgwriter) 和 检查点进程(checkpointer) 来帮助加速恢复。
如果启用了热备份功能,启动进程会在恢复到一致点后再通知 Postmaster 切换到 PM_HOT_STANDBY 状态,这时数据库可以接受只读查询。一旦归档恢复完成,启动进程会退出,Postmaster 会切换回 PM_RUN 状态,恢复到正常操作。
在 PM_RUN 或 PM_HOT_STANDBY 状态下,Postmaster 可以接受并启动正常的数据库连接。
在其他状态(比如恢复中或等待中),Postmaster 不会处理正常的连接请求,而是启动“死胡同”进程,这些进程只是给客户端返回一个错误消息后退出。它们会被记录在 ActiveChildList 中,直到它们都退出,Postmaster 才会继续其他操作。
在 PM_WAIT_DEAD_END 状态下,Postmaster 会等待所有“死胡同”进程退出,直到它们完全退出,Postmaster 才会开始关闭数据库或重启。
创建共享内存与信号量池。这部分工作是在初始化实例的时候进行的。原则上postmaster尽量避免触碰这些共享资源。究其本质,postmaster不是后端进程(PGPROC)数组的成员,因此不能参与锁管理之类的操作。让postmaster远离共享内存操作,可以让它变得更简单,同时更可靠,符合软件设计中的局部性原则。上面说的后端进程崩溃后,postmaster几乎总能通过重置共享内存操作来成功恢复,如果postmaster也使用共享内存,那么非常容易在后端进程崩溃的时候一起跟着崩溃。
需要提一点的是, PostgreSQL 的策略是:任一后端崩溃,postmaster 会拉闸重启整个实例以清理共享内存,再由“启动进程”执行恢复。所以使用kill命令处理PG后端进程往往是非常危险的。
SIGHUP:重载postgresql.conf/pg_hba.conf等配置。SIGTERM(Smart Shutdown):不再接收新连接,等待现有会话自然结束后关闭。SIGINT(Fast Shutdown):强行断开现有会话并做正常关闭。SIGQUIT(Immediate):立刻退出不做清理,下次启动会跑恢复。
后台进程(Background Processes)
后台进程负责执行数据库的系统维护任务和自动化操作。
下面逐一对这些后台进程进行介绍
Background Writer(bgwriter)
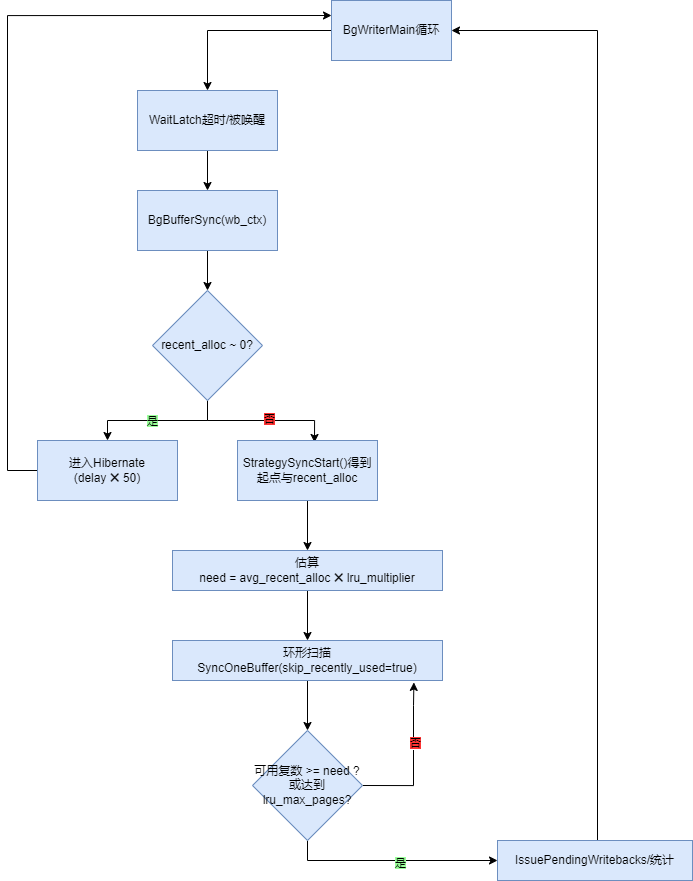
介绍刷盘进程bgwriter前,先科普一个概念,就是磁盘和内存内容不一致的时候,我们称内存中的这些页面(page)为脏页。bgwriter进程的工作内容就是刷脏,当发现干净页面不足的时候,会选择一批脏页面刷入磁盘,减少检查点时间及高并发下的抖动。
BackgroundWriter中,BgBufferSync是其核心方法。它控制本轮要扫描多少 buffer、预估接下来需要多少“干净可复用”页、在环形扫描中逐个调用 SyncOneBuffer() 写脏页并统计可复用页数。SyncOneBuffer()方法返回位掩码:BUF_WRITTEN、BUF_REUSABLE,前者表示确实写出了一个脏页,后者表示该页现在可复用。bgwriter 会以跳过 recently used的方式调用它,尽量不去打扰刚被访问的热点页。
扫描起点与近期分配率则来自缓冲替换策略模块。StrategySyncStart(&completed_passes, &recent_alloc)给 bgwriter 一个环形扫描起点、到目前为止替换指针完成的圈数以及最近的分配次数(recent alloc)。
BgBufferSync的伪逻辑如下:
读取策略层统计
(start, completed_passes, recent_alloc) = StrategySyncStart(...)。
估算下轮可能需要的干净页数
need = avg_recent_alloc * bgwriter_lru_multiplier(平均“近期分配量”乘上系数)唤醒扫描+刷脏
从
start开始在共享缓冲池按环形顺序扫描;对每个候选页调用SyncOneBuffer(..., /*skip_recently_used=*/true, wb_context):如果返回
BUF_WRITTEN,就把该页加入写回队列如果返回
BUF_REUSABLE,就把“当前可复用计数”+1直到“可复用计数 ≥ need”或“本轮写的页数达到
bgwriter_lru_maxpages上限”为止。上限被打满时,pg_stat_bgwriter.maxwritten_clean会 +1。
“什么都没发生”时进入休眠(Hibernate)模式:如果最近没有 buffer 分配活动,BgWriterMain 会把一次循环的睡眠时间放大(
HIBERNATE_FACTOR≈50),以减少唤醒次数/省电;一旦有新的 buffer 分配,会通过StrategyNotifyBgWriter唤醒。
连续页的写回会被合并并延迟触发,由 WritebackContext 承担“聚合/发起写回”的职责;当累计到阈值(bgwriter_flush_after)或需要提交时,会调用 IssuePendingWritebacks(wb_context, IO_CONTEXT_BGWRITER) 触发内核层的写回(不同平台对应 pg_flush_data() / sync_file_range/ posix_fadvise 等)。最近的 commit 还特地优化了在 fsync=off 的情况下跳过无意义的写回跟踪。
相关 GUC 有bgwriter_lru_maxpages(每轮最多写几页),bgwriter_lru_multiplier(下一轮需求乘子),bgwriter_flush_after(触发写回批次阈值)等。
需要注意的是,bgwriter和checkpoint虽然都有刷盘的操作,但是两者本质是不同的。
checkpointer:把 WAL 里记录的修改真正落盘并 fsync,确保崩溃恢复时间与 WAL 增长受控;它保证的是一致性和持久性。
bgwriter:尽量让“清洁页”储备充足,不保证耐久性,只是把“脏”变“干净”。两者配合可以把 I/O 压力摊平。它保证的是数据库系统的平稳和磁盘IO分散。
下面以PG11版本为例,说明刷脏过程中需要观察的要点(PG17及以上版本信息有所变化)
SELECT now() AS ts, *
FROM pg_stat_bgwriter;
-- 关键字段:
-- buffers_clean -- bgwriter 写出的缓冲页数
-- maxwritten_clean -- bgwriter 因“单轮上限”而提前停(命中限流)的次数
-- buffers_backend -- 前端会话自己动手写的缓冲页(bgwriter没来得及先写)
-- buffers_backend_fsync-- 前端会话被迫 fsync(极少见,说明配置/设备很吃紧)
-- buffers_alloc -- 分配的新缓冲页数
buffers_clean稳步增长 → bgwriter 正常“提前清洗”脏页。maxwritten_clean频繁增加 → 单轮写页上限太小(bgwriter_lru_maxpages)或轮询太频繁/过慢(bgwriter_delay),bgwriter 被“打断”很多次,可能跟不上工作集脏化速度。buffers_backend高 → 前端会话不得不自己刷脏页,说明 bgwriter 不够用或 checkpoint 压力大。buffers_alloc很高 → 工作集冷热变化大、共享缓冲命中差,需结合缓存命中率和接入/SQL 模式判断。
SELECT pid, backend_type, state, wait_event_type, wait_event
FROM pg_stat_activity
WHERE backend_type = 'background writer';Activity: BgwriterHibernate:休眠,无事可做(正常)。Activity: BgwriterMain:主循环等待/调度(正常)。
也可以使用pg_buffercache插件观察脏页
-- 脏页比例(估算)
SELECT SUM(CASE WHEN isdirty THEN 1 ELSE 0 END)::float / COUNT(*) AS dirty_ratio
FROM pg_buffercache;WITH s AS (
SELECT
now() AS ts,
checkpoints_timed,
checkpoints_req,
checkpoint_write_time, -- ms, double precision
checkpoint_sync_time, -- ms, double precision
buffers_checkpoint,
buffers_clean,
buffers_backend,
buffers_backend_fsync,
maxwritten_clean,
buffers_alloc,
stats_reset,
EXTRACT(EPOCH FROM now() - stats_reset) AS elapsed_sec -- double precision
FROM pg_stat_bgwriter
)
SELECT
ts,
checkpoints_timed,
checkpoints_req,
ROUND((checkpoint_write_time/1000.0)::numeric, 1) AS ckpt_write_s,
ROUND((checkpoint_sync_time/1000.0)::numeric, 1) AS ckpt_sync_s,
buffers_checkpoint,
buffers_clean,
buffers_backend,
buffers_backend_fsync,
maxwritten_clean,
buffers_alloc,
-- 占比/速率(自 stats_reset 以来)
ROUND((buffers_backend::numeric * 100)
/ NULLIF((buffers_backend + buffers_clean)::numeric, 0), 1)
AS backend_write_share_pct, -- 会话写占比,高→bgwriter跟不太上
ROUND((buffers_checkpoint::numeric * 100)
/ NULLIF((buffers_backend + buffers_clean + buffers_checkpoint)::numeric, 0), 1)
AS checkpoint_write_share_pct, -- 检查点写占比,高→检查点压力大
ROUND((maxwritten_clean::numeric)
/ NULLIF((elapsed_sec/60.0)::numeric, 0), 2)
AS maxwritten_per_min, -- 单轮上限被打满的频率(次/分钟)
ROUND((buffers_alloc::numeric)
/ NULLIF((elapsed_sec/60.0)::numeric, 0), 0)
AS alloc_per_min, -- 缓冲分配速率(页/分钟)
to_char(stats_reset,'YYYY-MM-DD HH24:MI:SS') AS stats_reset
FROM s;
backend_write_share_pct高(比如 >50%)→ 大量脏页由会话自行写,bgwriter 可能偏“保守”。maxwritten_per_min高 → 单轮被bgwriter_lru_maxpages频繁限流,可考虑调大或缩短bgwriter_delay。checkpoint_write_share_pct高、同时ckpt_write_s/ckpt_sync_s大 → 检查点阶段 I/O 压力大,要配合检查点参数/存储看。
WAL Writer(walwriter)
和磁盘交互的另外一个重要进程就是walwriter进程。wal日志记录了数据库中的一致性变化,是数据库复制,崩溃后恢复的安全保证。walwirter 把WAL 缓冲区里的数据周期性写出/刷盘,减少普通后端在提交时自己 write/fsync 的次数;同时为异步提交(synchronous_commit=off 等)提供有上界的落盘延迟。异步提交的提交记录会在不超过 3× wal_writer_delay 的时间内落到磁盘;若 walwriter 跟不上,普通后端仍然可以自行写/刷 WAL,因此 walwriter 不是关键路径进程。
walwriter刷盘和写出被以下参数控制:
wal_writer_delay(默认 200 ms):时间门限。每次刷完后,walwriter睡这段时间;但如果有异步提交发生,会更早被唤醒(从而缩短异步提交回写到盘的延迟)。wal_writer_flush_after:体量门限。如果距离上次刷盘时间还不到wal_writer_delay,且新增 WAL 量未达到该阈值,则 walwriter只写到 OS 缓冲而不 fsync;达到阈值就立即刷盘。
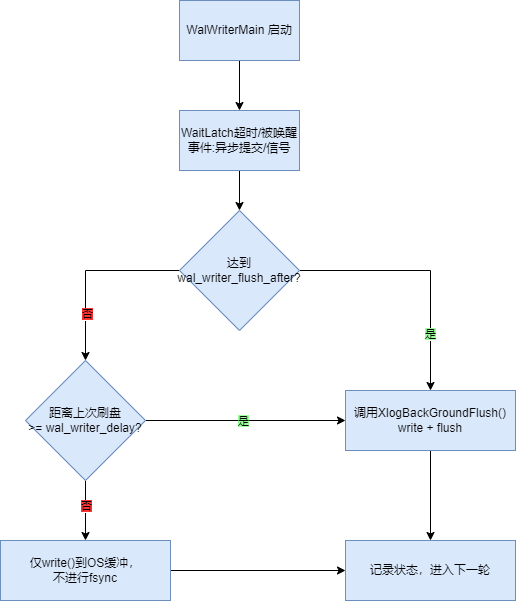
既然walwriter和 backendprocess都可以刷写wal日志,那么需要二者分工明确。
client backend在本进程内构造并插入 WAL 记录到共享的 WAL buffers,拿到该记录的结束 LSN(
XLogInsertRecord()返回),必要时还会直接 flush 到盘(XLogFlush())。插入期间用的是WALInsertLock(分片的轻量锁),只保护“把记录拷入 WAL 缓冲”的并发,不负责落盘。WAL Writer(walwriter):一个常驻后台进程,定期或被唤醒去把 WAL 缓冲写/刷到持久介质(
XLogBackgroundFlush()→XLogWrite()/XLogFlush())。它不生成记录,只做落盘“保洁”。
顺序,原子性,崩溃可恢复是刷写wal日志一致性的内在含义。
顺序:WAL 以 LSN 单调前进,
XLogWrite()只会从上次已写位置向前追加;WALWriteLock确保一次只有一个写者。不写半条记录:
WaitXLogInsertionsToFinish()保证截至本次目标 LSN 的所有记录都已经完整拷入 WAL 缓冲,再去写文件。保证原子性。组提交:多会话把“要 flush 的 LSN”合并,由一个写者完成写+刷;因此“写出去的内容”与“上层承诺的持久性”是一致的。
崩溃恢复:哪怕崩溃在“写了一半的页面”,恢复时也按页头/校验/链指针识别最后一条完整记录,截断脏尾,保证重做从干净一致点开始。
下面是后端进程和walwriter进程配合的一个例子
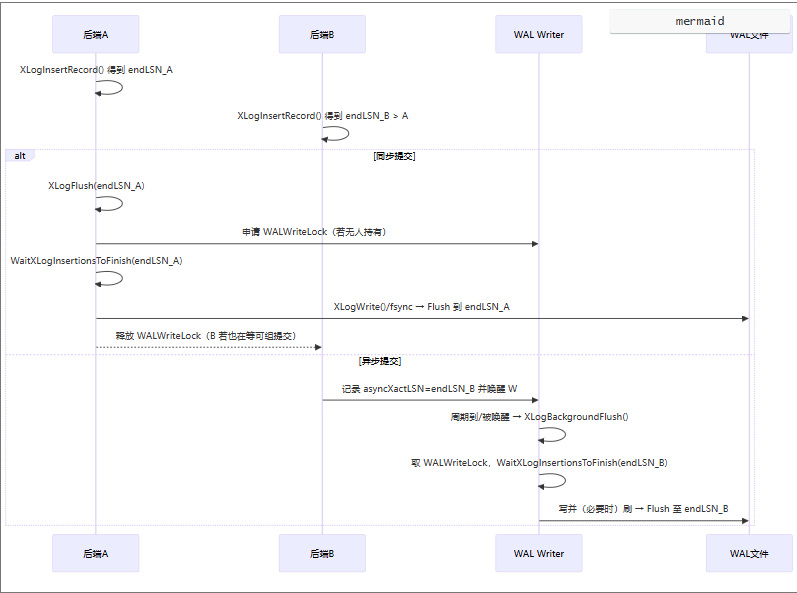
更多的wal日志原理部分可以参考ARIES
walwriter 由 postmaster 在启动子进程完成后立即拉起,并一直存活,直到 postmaster 命令它终止。正常的终止通过 SIGTERM 触发,此时 walwriter 执行 exit(0) 退出。紧急终止则通过 SIGQUIT;与任意后端一样,walwriter 收到 SIGQUIT 会直接异常中止并退出。
如果 walwriter 意外退出,postmaster 会将其视为后端崩溃:共享内存可能已损坏,因此需要对其余后端发送 SIGQUIT 予以终止,然后启动一次恢复流程。
Checkpointer
chk进程的工作目标是把数据文件里需要持久化的脏页全部写出并 fsync,形成一个一致性点(checkpoint),并据此回收/预分配 WAL 段,缩短崩溃恢复时间、控制 WAL 增长。
checkpointer进程是数据库一致性的保障性进程,因此是核心进程,它广泛与其他进程进行配合。
bgwriter:平时“提前清洗一部分脏页”,不给一致性背书;
walwriter:只负责 WAL 写/刷;
checkpointer:在检查点把仍需的脏页全部落盘且 fsync,并写入检查点记录到 WAL,更新控制文件等。
检查点涉及RTO指标,越频繁的检查点在崩溃后的恢复时间越短,但是对于磁盘性能要求就越高。总的来说,过于频繁的检查点是一个不好的征兆,对于崩溃后恢复应当基于系统化,架构化去解决,而不是通过检查点来强制解决。检查点的触发有以下原因:
时间到:
checkpoint_timeout到期的定时检查点(timed checkpoint)。WAL 脏得太多:自上次检查点以来产生的 WAL 超过
max_wal_size(或早期的逻辑,PG11 已有min_wal_size/max_wal_size池化)。人工请求:
CHECKPOINT命令,或内部发起(如VACUUM FULL、CREATE DATABASE等部分场景会发 force/immediate 的请求)备库:在恢复/热备中,Startup 进程决定时机并发起 restartpoint,由 checkpointer 执行写盘/fsync
一次检查点里具体做了什么
检查点的主循环在CheckpointerMain()方法中,而检查点流程则在 CreateCheckPoint()方法中,一次检查点有以下步骤:
LogCheckpointStart:记录原因(超时/请求/WAL 膨胀等)、估算工作量。
决定 redo 起点:计算
RedoRecPtr,并设置 full-page writes 模式边界(确保检查点后首次修改的页面会写入全页镜像,崩溃后可重做到一致)。写出所有需要的脏页:调用
BufferSync()(在 bufmgr.c),做全池扫描并把仍脏的缓冲页全部写出;为了平滑 I/O,在循环中多次调用CheckpointWriteDelay(progress)按checkpoint_completion_target分摊写入,尽量避免尖峰。检查点过程如何做到平滑
和bgwriter或pgwal进程的刷盘流程不太一样,chk刷盘的核心思路就是两步。
写一页→就评估“是否超前”:
BufferSync()每写出一页脏块后,都会调用CheckpointWriteDelay(flags, progress),把已完成进度progress(0~1)喂给节流器。节流器的职责就是“若进度超前,就小睡一会儿”。源码注释就写明“被 BufferSync 每写一页后调用,用来按checkpoint_completion_target节流”。怎么判断“超前/落后”:
IsCheckpointOnSchedule(progress)会把“我们写盘的进度”与“应该消耗的时间比例、以及WAL 产生比例”对比,若“进度 ≥(时间进度 与 WAL 进度)”,就认为在节拍上,可以睡;否则继续猛干不睡。
checkpoint_completion_target是个非常关键的参数,它指定了检查点完成的目标时间,主要涉及以下两条进度线:按 WAL 线:
取当前
recptr(主库:GetInsertRecPtr();恢复中:GetXLogReplayRecPtr()),与检查点开始位置ckpt_start_recptr之差,折算成自上次检查点以来、已经走过的 WAL 段比例,再除以估算段数CheckPointSegments:elapsed_xlogs = (recptr - ckpt_start_recptr) / wal_segment_size / CheckPointSegments。若progress < elapsed_xlogs→ 落后(不许睡)。按时间线:
取
(now - ckpt_start_time) / CheckPointTimeout得到“已经用掉的时间比例”。 若progress < elapsed_time→ 落后(不许睡)。
两条线都不落后 ⇒ on-schedule,可以睡。
代码里还有个
ckpt_cached_elapsed缓存,避免反复做昂贵计算;时间/WAL 指针不会倒退,所以命中缓存前直接判“未到睡觉点”。睡觉的前提条件
不是 快速检查点(
!(flags & CHECKPOINT_FAST));不是关库/关机路径(
!ShutdownXLOGPending && !ShutdownRequestPending);没有排队的“快检查点”请求(
!FastCheckpointRequested());并且
IsCheckpointOnSchedule(progress)为真(即进度不落后)
睡觉前会三件事,然后小睡100ms
吸收待处理的 fsync 请求:
AbsorbSyncRequests()(防止请求队列溢出);处理
SIGHUP重载并把 GUC 变更同步到共享内存;pgstat_report_checkpointer()上报进度、CheckArchiveTimeout()等周期性事务;小睡:
WaitLatch(MyLatch, ..., WL_TIMEOUT, 100, WAIT_EVENT_CHECKPOINT_WRITE_DELAY)→ 一次固定睡 100ms,并带 wait-event。
fsync 所有相关文件:调用
smgrimmedsync()/smgrsync()等把已写出的数据真正刷到盘;checkpointer 还会吸收/处理后端上报的 fsync 请求。前端或后台在修改文件后会通过
ForwardSyncRequest()把fsync 请求放进共享队列;checkpointer 定期调用
AbsorbSyncRequests()把这些请求收下,之后统一批量 fsync(函数ProcessSyncRequests()),避免每个后端各自fsync()造成上下文切换和队列风暴。这也是 checkpointer 的关键价值之一:集中处理 fsync,把“最贵的一脚”做得更经济。
写检查点记录到 WAL 并 fsync:把检查点记录写入 WAL,保证该记录已经持久化;
更新控制文件 & WAL 段管理:更新控制文件中的检查点指针,按
min_wal_size/max_wal_size尝试回收旧段,并可能预创建新段以减少后续切段抖动;LogCheckpointEnd:记录总写页数、写/同步耗时等统计。
以上步骤中有三个关键函数
CreateCheckPoint()(xlog.c)一次检查点的完整动作BufferSync()/CheckpointWriteDelay()(bufmgr.c) 写脏页 & 限速smgrsync()/smgrimmedsync()(smgr 层) 统一的 fsync 出口
备库的checkpoint
还有一个重要的概念,就是备库的chk进程,准确的说,它不能叫检查点,重启点(restartpoint)这个名字似乎更合适。备库并不会做checkpoint 记录写入 WAL的检查点。和主库chk进程同样的工作是,它会刷脏并且fsync,但是不向 WAL 再写 checkpoint 记录,而是更新控制文件(pg_control)上的恢复进度,好让下次重启时从更近的位置继续回放,并据此清理/回收更早的 WAL。简单地说:restartpoint = 恢复期间的“检查点”,但“证据”不写进 WAL,而是写进控制文件。
备库chk特有的触发条件和约束
触发方式:与主库近似,到时(
checkpoint_timeout)或WAL 已回放到一定量就触发;不过至少要回放过一条主库的 checkpoint 记录之后,备库才会开始做 restartpoint。频率限制:restartpoint 不能比主库的 checkpoint 更频繁(需要跟随主库的“节拍”,避免过度重做)。
清理归档:
archive_cleanup_command会在每个 restartpoint后被调用,参数%r代表“包含最后一个有效 restartpoint 的 WAL 文件名”,早于它的归档 WAL 可清理。不能随意删除本地 WAL:备库也会按照本地的
min_wal_size/max_wal_size做段池回收,但仍受级联复制下游的槽/保留及还未到达的 minRecoveryPoint 等限制,不能删掉恢复仍需的 WAL。
作为DBA,检查点任务的观测非常重要:
SELECT now(), checkpoints_timed, checkpoints_req,
checkpoint_write_time, checkpoint_sync_time,
buffers_checkpoint
FROM pg_stat_bgwriter;checkpoints_timed / checkpoints_req:定时 vs 人工/压力触发的次数。checkpoint_write_time / checkpoint_sync_time(毫秒):写入 vs fsync 耗时。buffers_checkpoint:检查点阶段写出的页数。
审计日志也可以验证检查点的各项工作,强烈建议 log_checkpoints=on。
每次 checkpoint 会打印“写了多少页、写/同步用了多长时间、平均速率、造成原因(timeout/请求/WAL 膨胀)”。
结合审计日志和bgwriter视图,能定位“是写太多还是fsync 太慢”。
除此,还可以观察检查点进程的状态
SELECT pid, backend_type, state, wait_event_type, wait_event
FROM pg_stat_activity
WHERE backend_type = 'checkpointer';常见等待事件:Activity: CheckpointerMain(主循环),以及磁盘 I/O 相关的等待(不同平台的 wait_event 可能不完全一致,重点看是否长期被 I/O 拖住)。
参数调优部分常见如下:
checkpoint_timeout:别太短(会太频繁),多数场景 5~15 分钟;max_wal_size/min_wal_size:调大 max_wal_size 可降低“因 WAL 膨胀触发的 checkpoint”频率;min_wal_size给出可回收池的“底线”;checkpoint_completion_target:0.7~0.9 常见,让写入分布更平滑;checkpoint_flush_after:适度增大有助于顺序写合并;存储太慢:从日志的
sync_time与系统层iostat/pidstat着手,必要时考虑文件系统挂载参数(barrier/写回策略)与阵列缓存策略。
chk进程导航图
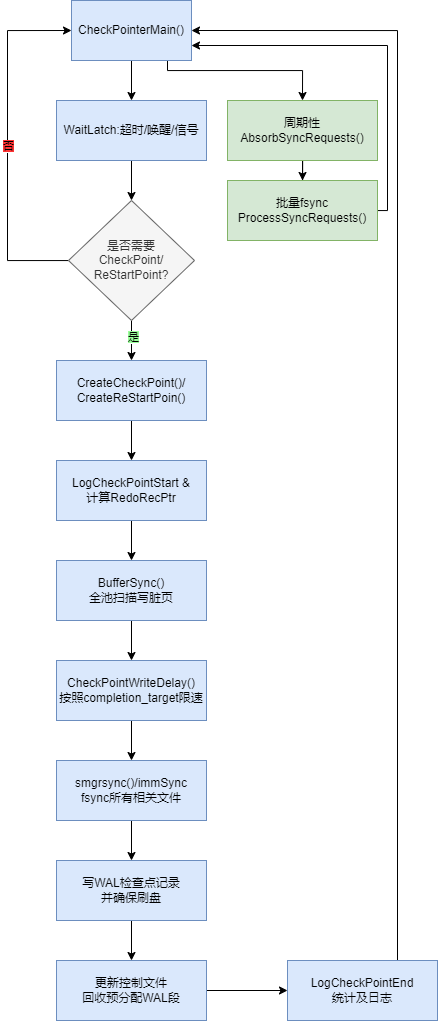
Archive Process
pgarch.c归档进程负责将Postgresql产生的wal日志进行归档处理,结合basebackup可以实现时间点恢复PITR。作为一个生产系统,要求必须开启归档。开启归档的条件有:
wal_level=replica,或者更高等级。wal_level参数决定了可以产生多少种类的wal记录。区别如下:archive_mode=on或者always。两者的区别在于,always会在恢复和备库状态下也启用归档进程,而on只在实例正常运行时(非恢复期间)进行归档,在备库恢复期间不会归档。这里不推荐always直接从备库归档到与主库相同的仓库,设计归档架构时,避免双写同仓。
archive_command参数则控制着归档操作,你甚至可以通过这个参数进行异地节点的归档保存
archive_command = 'scp -q -o BatchMode=yes -o StrictHostKeyChecking=yes %p arch@backup.example.com:/data/pg-archive/hostA/%f'其中的占位符含义如下:
%p=待归档文件的完整路径%f=文件名本身
归档流程
当一个 WAL 段“完成/切段”或生成了 timeline/backup 相关文件时,核心代码会在 pg_wal/archive_status/ 下放一个 *.ready 标记;传输成功后把它改名为 *.done。
archiver 的主循环调用 pgarch_readyXlog() 扫描 archive_status/,找出下一个 *.ready 的段名(PG11 每次扫描目录;PG15 起做了批量记忆,减少大量 .ready 时的反复扫描开销)。
有新 .ready 生成时会“踢一下” archiver;即便没有事件,archiver 也会按 PGARCH_AUTOWAKE_INTERVAL≈60s 定期主动扫描。
找到候选后,通过归档执行路径(PG11 为调用 shell 的 archive_command)把 %p 源文件送到你的归档存储;成功则把对应的 *.ready 改成 *.done,失败则保留 .ready 以便重试。如果发现某个 .ready 对应的 WAL 文件已被回收/不在本地(极端情况),archiver 会清理“孤儿提示文件”。
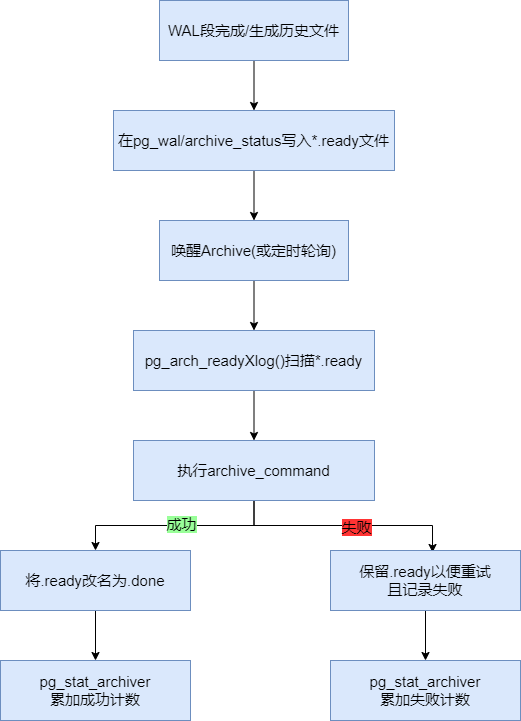
Logging Collector
syslogger.c日志进程会将Postmaster,各种后台进程及后端进程写到stderr的日志统一接到一根管道里,再落到滚动日志文件(也可同时写 csvlog)。这避免了进程间日志交叉、断行等问题。
当你把 logging_collector=on 后,postmaster 会 fork 出 syslogger。logging_collector 只能在启动时生效,其他日志参数可 SIGHUP 重载。审计日志的参数较多,可以参考官方文档进行了解Error Reporting and Logging.
syslogger的运行流程
Postmaster 启动时创建一对 匿名管道,把所有子进程(后台进程、前端会话后端)的 stderr 重定向到 管道写端;自己和 syslogger 拿着 读端(postmaster 常驻持有以便 syslogger 异常重启后还能继承)。
子进程里所有 ereport()/elog() 产出的「stderr 版」日志,不是直接 write() 文本——而是被打包成 管道分片(chunks) 协议写入管道:每个分片带一个小头(长度、pid、目标、是否最后一片)。
syslogger 主循环 WaitEventSetWait() 等管道可读,批量 read() 到缓冲,调用 process_pipe_input() 解析分片、按 pid 归并,凑齐一条完整消息(看到 “IS_LAST”)后落到对应目的地文件(stderr/csv/json)。同时按 时间/大小 或外部信号做 日志轮转。
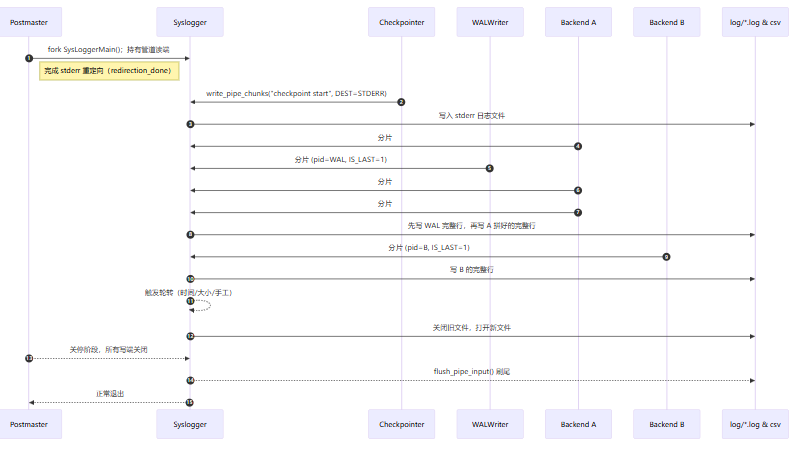
审计日志是一座宝库,通过它,可以进行异常定位,事后审计,服务与数据库的交互细节等等。通常会结合logrotate 进行审计日志的运维工作,PG 内置 collector 负责生成滚动文件(按日/按量)。OS系统侧的logrotate则担当压缩和保留策略。
postgresql.conf侧参数建议
# 开启收集器(启动后才能生效;需重启实例)
logging_collector = on
# 文件目标(stderr 必选;需要 CSV 则加 csvlog)
log_destination = 'stderr'
# 日志目录与命名(示例)
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
# 由 PG 自己按“时间/大小”触发轮转(任选其一或都开)
log_rotation_age = 1440 # 每 24h 轮转一次
log_rotation_size = 200MB # 单文件到 200MB 就轮转
log_truncate_on_rotation = on # 同名时截断重建(主要对按时轮转有用)/etc/logrotate.d/postgresql 配置
/var/lib/pgsql/11/data/pg_log/*.log {
daily
rotate 14
missingok
notifempty
compress
delaycompress
dateext
su postgres postgres
sharedscripts
postrotate
# 让 PG 主动切新文件(不会中断服务)
su - postgres -c "psql -Atqc 'SELECT pg_rotate_logfile();' postgres" >/dev/null 2>&1 || true
endscript
}当然你也可以固定每个月对审计日志进行归档处理 ,这个没有强制要求,完全看安全及运维要求了。
Stats Collector
pg_stat.c统计信息收集器负责接收各个后台/后端上报的统计增量(表/索引访问计数、函数调用计数、数据库级事务/临时文件等),汇总后会定期落盘到pg_stat_tmp/ 下的临时文件;关库时会把快照固化到 global/pgstat.stat,以便下次启动快速“预热”。查询诸如 pg_stat_* 视图时,后端会从这些统计文件读一个快照。
这些统计信息主要用于监控与维护决策(如 autovacuum 判断阈值、观察热点表/索引等)。需要注意的是,其不等同于优化器的ANALYZE统计(pg_statistic/pg_statistic.h,和收集器是两条线)
stats collector进程的执行流程
Postmaster 在启动期拉起 stats collector。
每个后端把本事务期间的“表/索引/函数”等统计先放在本地缓存;在合适的时机(例如事务结束、函数批量阈值达到等)调用 pgstat_report_stat() 一次性打包发送多条消息:
pgstat_send_tabstat():表/索引访问计数块(hit、read、tup_ins/upd/del 等);pgstat_send_funcstats():函数调用次数与总时长(受track_functions控制);以及临时文件、死锁、归档器、bgwriter 等专用消息类型。
收集器循环从本地通信端口读取消息,,把增量合到内存哈希里。到轮转点(时间或事件)时把全量快照写到 pg_stat_tmp/ 下多个文件(按 DB/全局拆分)。
当你查询 pg_stat_* 视图时,后端调用如 backend_read_statsfile() / pgstat_read_current_status() 读取这些统计文件到本地内存,再拼出行集返回。
pg_stat_activity 属于实时会话状态,其核心数据来自后端状态共享区(backend_status.c),并不经收集器文件中转;但开关仍受 track_activities 控制。
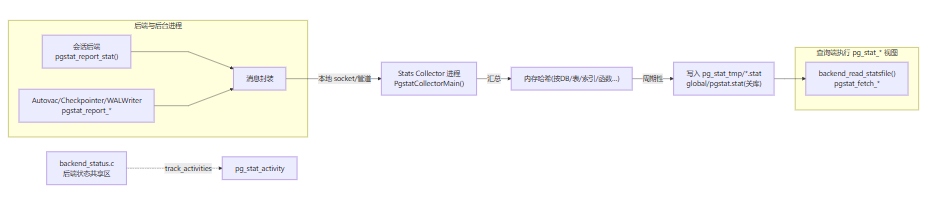
Autovacuum Launcher
autovacuum.c 自动清理启动器进程 同时实现了 Launcher (启动器)和 Worker(清理进程)。
Autovacuum 系统由两类不同的进程构成:autovacuum launcher 和 autovacuum worker。
当 autovacuum 的 GUC 参数被设置时,postmaster 会启动一个常驻的 launcher 进程。launcher 负责在合适的时机调度并启动 autovacuum workers。真正执行清理工作的则是 worker 进程:它们按 launcher 的指定连接到某个数据库,连接成功后扫描系统目录以选择需要 vacuum 的表。
autovacuum launcher 不能自行启动 worker 进程;如果让它直接 fork,会带来健壮性问题(例如:在异常情况下难以及时关闭这些子进程;又由于 launcher 自身已连接共享内存、可能受其损坏影响,它的健壮性不如 postmaster)。因此,启动 worker 的任务交由 postmaster 完成。
系统中有一块 autovacuum 共享内存区域,launcher 会在其中存放它想要进行 vacuum 的数据库信息。当需要启动新的 worker 时,launcher 会在共享内存里设置一个标志位,并向 postmaster 发送信号。此时 postmaster 只需知道“需要启动一个 worker”;它会 fork 出一个新子进程,并将其“转变”为 worker。这个新进程连接共享内存后,就能读取到 launcher 预先放入的相关信息。
如果 postmaster 端的 fork() 调用失败,它会在共享内存区域里设置一个失败标志,并向 launcher 发送信号。launcher 注意到该标志后,可以通过重新发送信号来再次尝试启动 worker。需要注意的是:这类失败通常是瞬时性的(例如高负载、内存压力、进程数过多等导致的 fork 失败);而更持久的问题(比如无法连接数据库)会在 worker 阶段被发现,并通过让 worker 正常退出来处理。之后,launcher 会按调度在合适的时间再次尝试启动新的 worker。
当 worker 完成 vacuum 工作后,会向 launcher 发送 SIGUSR2。launcher 被唤醒后,如果当前调度非常紧,可以立即再启动一个新的 worker。同时,launcher 还可以在这时平衡其余仍在运行的 workers 的基于代价的 vacuum 延迟配置。
需要注意:同一数据库内可以同时存在多个 worker。它们会把自己当前正在 vacuum 的表记录到共享内存中,从而使其他 workers 避免因争夺该表的 vacuum 锁而被阻塞。另外,它们在处理每张表之前,还会从 pgstats(统计信息)中读取该表上次被 vacuum 的时间,以避免又去 vacuum 一张刚刚被其它 worker 处理完、因此已不再记录在共享内存里的表。不过,由于在尚未持有关系锁之前存在一个小窗口,worker 仍可能选择到一张已经被 vacuum 过的表;这是当前设计中的一个缺陷(bug)。
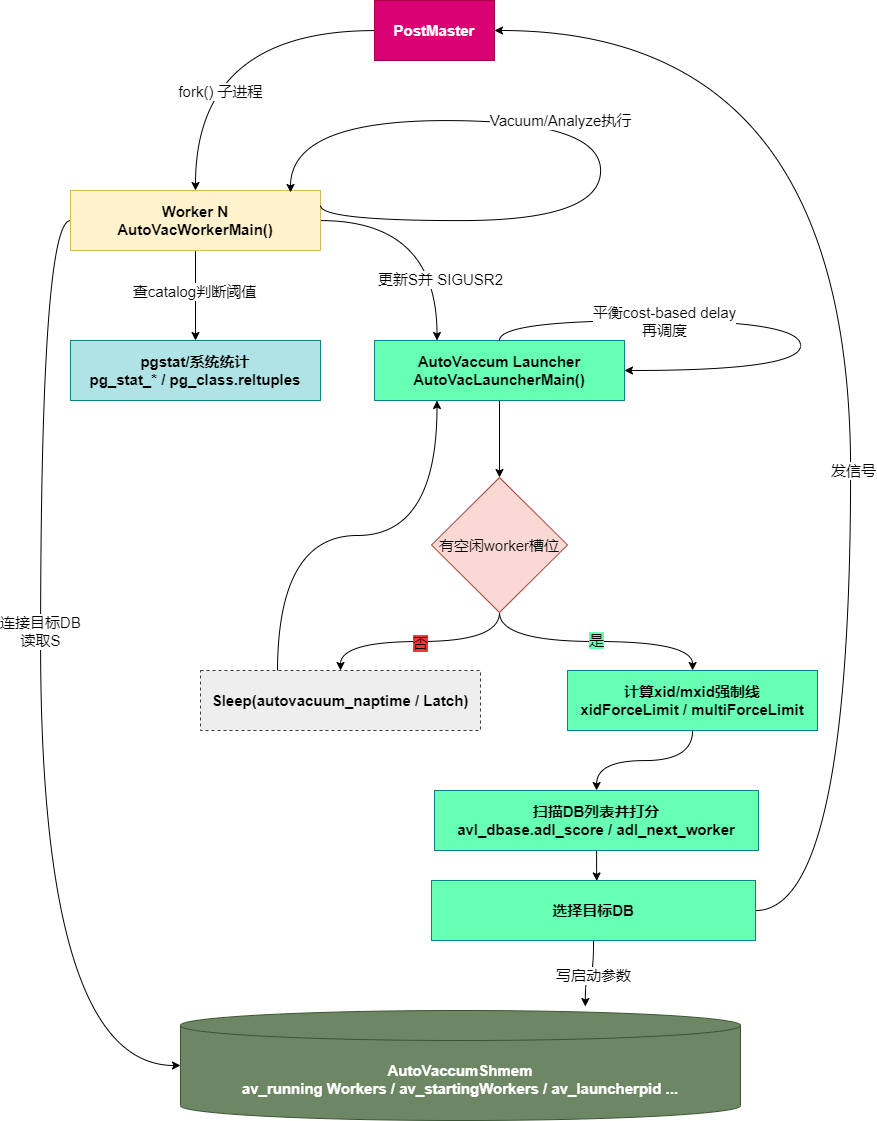
上面的七类后台进程是PG进程架构的骨干,除此外,还有如流复制复制相关的进程walsender/walreceiver,逻辑复制相关Logical replication launcher/logical replication worker(apply)/tablesync worker
分片执行进程 parallel worker,还有自带扩展的后台进程,这些进程都会以background worker形式呈现。
后端进程(client backend)
除了后台进程,还有一类常见的进程被成为后端进程。它是postmaster为每个客户端连接fork出的进程。
后端进程的生命周期
接入与 fork/exec
postmaster.c中详细描述了监听与接入。
ServerLoop()在监听套接字accept()到新连接后,进入BackendStartup()。BackendForkExec() frok出子进程,然后进入
BackendRun(Port *port),最终调用PostgresMain()postgres.c连接握手与认证
子进程在完成认证前准确的说还不能被叫做后端进程,解析包协议pqcomm.c。认证auth.c则采用
ClientAuthentication(port)方法进行。通过该方法的源码,我们可以知道,认证首先是防火墙策略的认证,就是pg_hba,然后才是各种类型的密码认证,包括md5/scram/ssl/pam/ldap 等。最后则是在该进程内设置变量, GUC、search_path、application_name等。挂接共享内存、注册自身
InitPostgres()方法会打开数据库、命名空间等上下文。之后便会注册 PGPROC,进程会将自己加入ProcArray,从此能参与锁、快照、死锁检测等;除此外,还会创建资源所有者ResourceOwner.以及内存上下文palloc.h。两者配合将内存与非内存资源进行管理。
其中资源拥有者是当前(子)事务/门户/后台工作单元”的资源账本,负责登记→扩容→记账→在提交/回滚/错误时按顺序释放各种非内存资源,避免泄漏与顺序错误。其内容包括有:
缓冲区 pin
Relation/Relcache 引用
系统缓存引用(SysCache/CatCache 列表)
快照
文件/目录句柄
计划缓存/元组描述/复制槽等
管理上则类似栈这种数据类型进行管理:
创建(入栈)
顶层事务开始:
StartTransaction()里创建TopTransactionResourceOwner = ResourceOwnerCreate(NULL, "TopTransaction");并设置CurrentResourceOwner = TopTransactionResourceOwner。子事务/保存点:
StartSubTransaction()会CurTransactionResourceOwner = ResourceOwnerCreate(parent, "SubTransaction");然后CurrentResourceOwner = CurTransactionResourceOwner(指向子 owner)。释放(出栈)
提交/回滚顶层事务:
CommitTransaction()/AbortTransaction()调ResourceOwnerRelease(BEFORE_LOCKS/LOCKS/AFTER_LOCKS, isCommit, true);→ResourceOwnerDelete(TopTransactionResourceOwner)→CurrentResourceOwner = NULL。提交/回滚子事务:
CommitSubTransaction()/AbortSubTransaction()同样 三阶段释放 后ResourceOwnerDelete(CurTransactionResourceOwner),并把CurrentResourceOwner切回父 owner。
而内存上下文管理是 PG 自研的分层内存分配器,让你按“生命周期”给内存分组;结束时一键 Reset/Delete 整组,无需逐个
free,也能在 ERROR 后批量回收,从机制上“防泄漏”。篇幅有限而内存管理涉及到OS和DB两个系统,内容过于复杂,这里不能铺开描述。有兴趣可以结合源码观察。到这一步这个进程才算是真正的可以被成为后端进程。
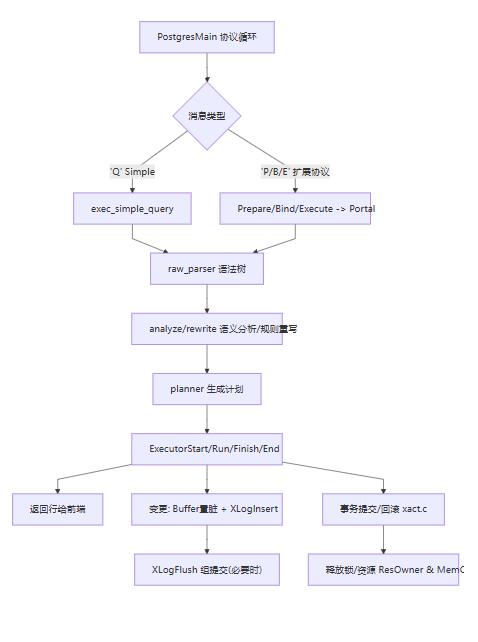
主循环:协议分发与 SQL 执行
PostgresMain()进入前端/后端协议主循环:Simple Query:
'Q'→exec_simple_query()Extended Query:
'P'/'B'/'E'→Prepare/Bind/Execute→Portal执行(pquery.c)
每条语句都会有 解析→分析→优化→执行四步
退出与清理
正常退出:
COMMIT后pgstat_report_activity()变idle,客户端断开 → 释放锁、ResourceOwnerRelease()、从 ProcArray 移除。异常退出:后端用
sigsetjmp/siglongjmp异常栈兜底(你之前看过的那段注释),在ERROR时回滚当前事务并清理内存/锁(不影响进程继续服务);FATAL则结束连接,进程退出。
后端进程创建时序图
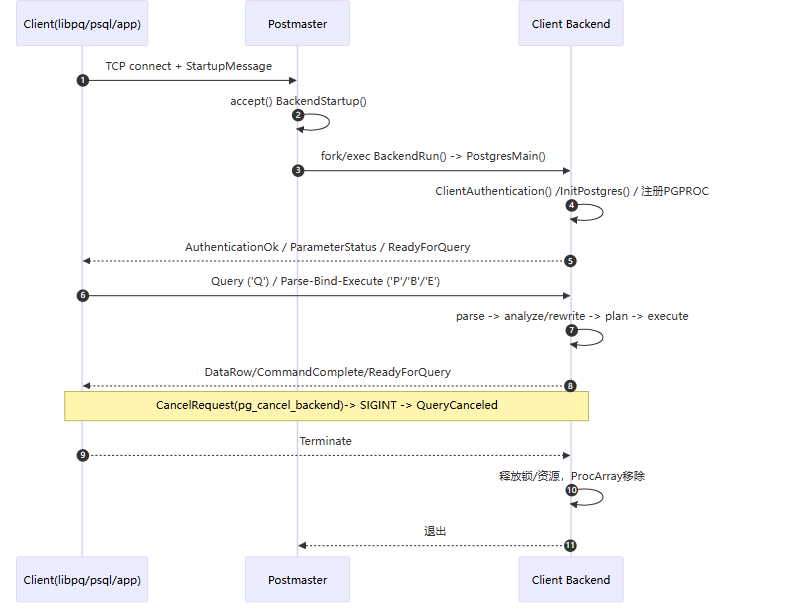
一条SQL语句的执行过程