

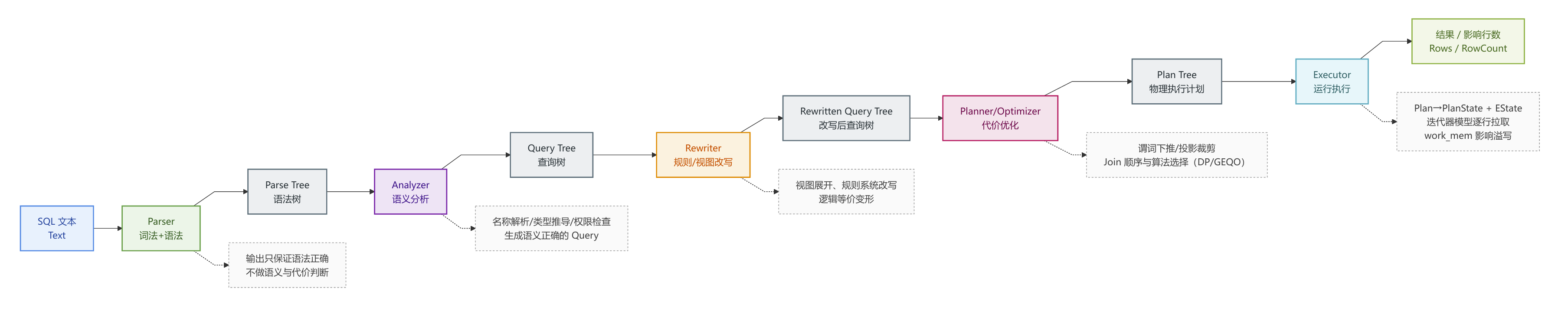
SQL语句的生命周期
前面的内存架构,物理架构,进程架构偏向静态系统架构,有哪些部件,长什么样子,谁负责干什么。
现在可以通过描述一条SQL语句的生命周期将上面的各部分串起来,是一个偏动态的查询架构。一个SQL语句可以分为以下五部分:Parser → Analyzer → Rewriter → Planner → Executor。
从客户端报文到 exec_simple_query
这是语句生命的起始,客户端发送一条 Simple Query(文本协议)时,大致流程是:
// postgres.c
PostgresMain(...)
{
for (;;)
{
// 读取客户端发来的消息,区分类型(Q: simple query / P: parse / B: bind ...)
switch (firstchar)
{
case 'Q': // Simple Query
exec_simple_query(query_string);
break;
...
}
}
}
exec_simple_query()位于pquery.c。
除了启动包和 SSL 请求以外,所有协议消息结构如下:
Byte1 消息类型,比如 'Q' / 'P' / 'B' / 'E' ...
Int32 消息长度(包含这 4 个字节,但不包含前面的类型字节)
... 剩下是消息体(参数)PostgresMain() 中读第一字节 firstchar,然后 switch (firstchar) 分发:
switch (firstchar)
{
case 'Q': /* simple query */ exec_simple_query(...); break;
case 'P': /* parse */ exec_parse_message(...); break;
case 'B': /* bind */ exec_bind_message(...); break;
case 'E': /* execute */ exec_execute_message(...);break;
case 'D': /* describe */ exec_describe_message(...);break;
case 'S': /* sync */ exec_sync_message(...); break;
case 'H': /* flush */ ... break;
case 'C': /* close */ ... break;
case 'F': /* fastpath func */ exec_fastpath_message(...);break;
case 'X': /* terminate */ ... 退出 break;
...
}其中 Q/P/B是三个最核心的协议。
Q:Simple Query
简单查询协议是最常见的一类查询协议,我们常见的查询就是使用这类协议。报文头部的消息类型是Q。一次 Q 可以包含多条 SQL,用 ; 分隔(所有语句共享一个隐式事务块,除非你显式 BEGIN/COMMIT)。文本模式,参数得拼在 SQL 字符串里。后端一次性 parse/analyze/plan/execute,不能复用 parse/plan 结果。具体的消息格式如下:
Byte1 'Q'
Int32 长度(包含长度字段自身)
String query_string,以 '\0' 结尾P:Parse
Parse message扩展查询协议把 SQL 文本“预解析”为 Prepared Statement。Parser会把SQL文本和预期参数类型注册为一个prepared statement 对象,但不一定马上执行。消息格式如下:
Byte1 'P'
Int32 长度
String statement_name // 预编译语句名,空字符串表示 unnamed
String query_string // 只能包含一条 SQL(多条会报错)
Int16 numParamTypes // 后面参数类型 OID 的个数
Int32[n] paramTypeOids // 每个参数的类型 OID,0 表示未指定exec_parse_message()的处理流程是,读取 statement_name / query_string / 参数类型 OID 列表,调用 pg_parse_query() 做 语法解析,生成 RawStmt 列表,对每个 RawStmt 调 parse_analyze() 做 语义分析,生成 Query,建立一个 PreparedStatement / CachedPlanSource,保存 SQL 文本/ Query 树/参数类型信息,规划一般延迟到 Bind 阶段(真正要执行时)。成功时,后端返回 ParseComplete;语法/语义出错则返回 ErrorResponse,当前事务出错状态等。
驱动(JDBC、libpq)一般会用 P 做预编译,好处是少一次解析/分析,可以重用计划而且支持参数化。另一面,该协议只能是一条 SQL,不能像 Q 那样一串多条。否则语法错误。而且该协议的生命周期是会话级的,直到连接断开或显式 Close,这点要特别注意,在pgbouncer连接池的配置上要有所体现。
B:Bind
Bind message 扩展查询协议把刚才 Parse 出来的 prepared statement,加上这次的参数值,绑定成一个 portal,并决定结果集的格式(text/binary)。其格式如下:
Byte1 'B'
Int32 长度
String portal_name // 目标 portal 名,空字符串 = unnamed portal
String statement_name // 源 prepared statement 名,空字符串 = unnamed stmt
Int16 nParamFormatCodes // 参数格式码个数 C
Int16[C] paramFormatCodes // 每个参数是 text(0) 还是 binary(1)
Int16 nParams // 参数个数 N
for each param:
Int32 paramLen // -1 = NULL
ByteN paramValue // 参数值,text 或 binary
Int16 nResultFormatCodes // 结果列格式码个数 R
Int16[R] resultFormatCodes // 每列 text/binary,或 1 个值表示所有列exec_bind_message()的流程如下:
找到
statement_name对应的 prepared statement;检查参数个数、类型是否匹配;
根据参数格式码解析参数数据,构造
ParamListInfo;通常在这里进行规划(planning),若该 prepared statement 之前没规划过,
pg_plan_queries()生成计划,可能缓存为 generic plan,或者结合本次参数生成 custom plan,再决定是否缓存;创建一个
Portal对象,满足 “这个 prepared statement + 这组参数 + 这个结果格式” 的组合。记录顶层Plan、QueryDesc等。
E:Execute
Execute message和 P/B 搭配不可分,其消息格式如下:
Byte1 'E'
Int32 长度
String portal_name // 要执行的 portal 名,空 = unnamed
Int32 max_rows // 返回的最大行数,0 = 所有行服务端exec_execute_message()的流程是,找前面Bind生成的 portal,调用 PortalStart()(第一次执行时),建立 EState、PlanState 树。调 PortalRun() 拉取结果,max_rows == 0时则一直跑到结束,max_rows > 0时则跑一段,可能返回 PortalSuspended,等待下一次 E 继续执行。函数返回类似 simple query:RowDescription / DataRow / CommandComplete / EmptyQueryResponse / ErrorResponse 等。
至此主要类型的的协议介绍完毕,下面是一些用于辅助控制和描述类的其他类型协议。
解析器 Paser
解析器的调用链入口位于pquery.c中的pg_parse_query。主要结构体有RawStmt,以及 SelectStmt、InsertStmt 等,这些结构体都位于parsenodes.h。调用链条如下:
pg_parse_query(query_string)
-> raw_parser(query_string)
-> yylex() // 词法分析,来自 scan.l
-> yyparse() // bison 生成的语法分析,来自 gram.y
-> 返回 List<RawStmt*>RawStmt:外面包了一层,里面的 stmt 才是真正的语句节点(SelectStmt、InsertStmt…),还有 SQL 文本位置之类的元信息。
这个阶段会检查语法的正确性,包括关键字、括号、from/where等结构是否合法。而并不知道表、列、类型存不存在。这个阶段会输出一棵没有语义的语法树,例如:SELECT * FROM t WHERE a + 1 > 10;这个语句会被解析成解析成 SelectStmt,其中fromClause 里存的是一个 RangeVar(名字叫 t),targetList 里有一个特殊的 ResTarget 表示 *,whereClause 是一个表达式树(OpExpr 嵌套 A_Expr 等)。
这个树很接近 SQL 文本结构,但还无法执行,需要进入下一步分析。上面就是简要的解析器工作流程,为了更好的理解词法解析和语法解析,下面剖析这这两步。
词法分析
Lexer 的工作是将字符流切割成Token流,词法分析首先会做分词(Token),比如输入以下语句
SELECT a + 1 FROM t WHERE b > 10;词法分析器会对这个sql字符串进行分词。
select是关键字Token,a是标识符Token,+是运算符Token,1则是常量Token。
之后,词法分析会进行规范化处理,注释、空白、转义、字符串字面量、参数引用、标识符大小写折叠等。
flex 词法规则核心实现在scan.l,一些关键字查表、标识符处理等辅助函数则在scansup.c
在 bison/flex 的经典组合里,yylex()每调用一次,返回一个整数枚举类型的 token 。同时会输出
yylval:token 的语义值(比如常量值、字符串内容、标识符文本)在 PG 里,token 的语义值通常承载为
标识符、常量、运算符及参数yylloc:token 在原 SQL 文本中的位置(用于报错定位)
scan.l 不是“单条正则从头匹配到尾”这么简单,它大量使用 exclusive start conditions(词法状态) 来处理 SQL 的复杂字面量语法。例如,单引号字符串 'it''s ok',必须识别 '' 表示单引号转义,还要支持 E'...' 的反斜杠转义语义。此外还有双引号标识符,双引号内不做大小写折叠,且允许关键字作为对象名。这些都需要 scanner 进入不同状态,才能正确消化掉内容并在结束时生成一个token。
PG的词法解析器识别到类似 [A-Za-z_][A-Za-z0-9_$]*的单词后,并不会直接返回IDENT,而是会将文本做规范化,比如折叠为小写,再按NAMEDATALEN截断等。kwlist.h生成关键字映射,词法解析器根据关键字类别返回保留关键字TOKEN(SELECT/FROM等),或 非保留关键字在语法里仍可能走 IDENT/unreserved_keyword 等路径。
对于运算和符号,词法分析器往往会区分单字符符号和多字符及自定义运算符。前者直接返回字符本身 token(比如 '+', ',', ';', '('),而后者返回通用 token(常见命名为 Op),并把具体文本放进 yylval,交给语法规则匹配 qual_Op / MathOp 等非终结符去处理。
语法分析
这一步才算真正的parser,前面的词法分析只知道这是一串token,语法分析要回答SELECT ... FROM ... WHERE ... 这种 token 序列,能不能组成一棵合法的 SQL 语法结构,如果合法,按 SQL 语法把它归约成树形结构(AST语法树),其中包含了SelectStmt,InsertStmt,JoinExpr,以及各节点的表达式A_Expr、ColumnRef、FuncCall等。
gramparse.h中包含了bison 语法实现,bison 生成的 base_yylex()是一个LR 语法分析器,其最终产出 raw parse tree(未语义分析),供 analyze.c 后续转换为 Query tree。
RawParseMode决定从哪个语法入口符号开始 parse,它明确了 raw_parser 接受的字符串形态 与 输出 List 里装什么节点:
RAW_PARSE_DEFAULT:解析分号分隔的 SQL 命令,返回List<RawStmt>RAW_PARSE_TYPE_NAME:解析类型名,返回List<TypeName>(单元素)RAW_PARSE_PLPGSQL_EXPR / ASSIGNn:给 PL/pgSQL 场景的特殊入口(单元素 List)
在 raw_parser() 内部,非 DEFAULT 模式会预置一个“lookahead token”(mode_token[])作为语法入口切换信号,写得非常清楚:数组按 RawParseMode 下标索引,设置 yyextra.have_lookahead/lookahead_token。
raw_parser()的职责是拿到 token 流后完成语法归约(shift/reduce)并产出 raw parsetree 列表(未 analyzed)。因为 bison 需要通过 yylex 取 token,raw_parser() 仍会创建 flex scanner。
base_yyparse是语法分析器的主体,负责拼接Token,做约规,拼接解析树,在执行机理上,base_yyparse() 就是典型 bison LALR(1) 流程:
维护 状态栈(states)+ 语义值栈(YYSTYPE)+ 位置栈(YYLTYPE)
每次通过
yylex(这里是base_yylex())取一个 token查 action 表:shift(压栈)或 reduce(按产生式归约)
在 reduce 时执行产生式对应的 C 代码块(semantic action),用
makeNode()/list_make*()等构造 AST 节点并返回给上层非终结符最终从“语句列表”入口符号归约完成,形成
yyextra.parsetree
分析器 Analyze
分析器的工作是将Raw Parse Tree 转换为一棵Query Tree。analyze.c
这个阶段的核心工作原则如下:
可优化语句(optimizable statements):Analyze 阶段会对每个被引用表获取“合适的锁”,因此可以做“更重的语义分析”(因为语义依赖系统表/元数据,必须稳定)。
工具类语句(utility commands):一般不在这里做语义转换(否则执行阶段锁可能不再有效),而是直接包进一个
CMD_UTILITY的Query节点里。但
DECLARE CURSOR / EXPLAIN / CREATE TABLE AS等是例外:它们内部包含可优化语句,所以仍需做 转换。
总结一下,就是分析器的设计哲学是能保证语义稳定的地方才做深语义绑定;否则就延迟到 utility 执行器自己处理。
注意:Analyze 阶段就可能产生 queryId,并且提供 post-parse-analyze hook 给插件,这也是很多安全/审计类插件切入点。parse_analyze_withcb()
在postgres.c中,分析器和重写器是一对绑定的组合,首先会调用 parse_analyze_fixedparams() 或 parse_analyze_varparams()进行执行解析分析,之后就是重写pg_rewrite_query()。Analyzer和Rewriter都有可能讲一条语句扩展为多条语句,所以返回的是List<Query>。
分析器的输入来自解析器的RawStmt,它由gram.y 输出,此时词法/语法已经完成。但是同时保留了大量语法形态的节点,比如还没绑定到具体表/列、运算符还是符号、常量可能还带 unknown 语义等。分析器的输出则是一个Query或是经由重写器产生的List<Query>,对于Planner而言,所有可解析的语义都被绑定成“OID + Var + 函数/运算符选择 + 类型/排序规则/权限依赖等内核可执行语义,Query 结构具备“可优化性。
Query内容
Query 是后续 optimizer / executor 理解的逻辑查询表示。其包含如下内容:
commandType:SELECT/INSERT/UPDATE/DELETErtable:RangeTblEntry列表(所有表/子查询/函数等“范围”)jointree:FROM/JOIN 形成的逻辑连接树targetList:TargetEntry列表,每个代表一个输出列qual:WHERE 条件表达式groupClause/havingQual/sortClause/limitOffset/limitCount等
除此,分析器还会进程名字解析 Name Resolution。比如FROM t1 a JOIN t2 b ON a.id = b.id WHERE a.col > 10;这句,Analyzer 会查系统 catalog 找表 t1/t2 是否存在、列有哪些。把 a.col 解析为特定 RangeTblEntry + 某个属性号(varno/varattno),对 * 展开成多个 TargetEntry(每个实际列)。
类型推断与强制类型转换Type Resolution & Coercion同样也是分析器的工作内容,比如WHERE id = '123'中的id是int类型,而'123'则是unknown。分析器会查找 pg_operator,找到 = 操作符对应的参数类型组合。决定把 '123' 转成 int4,在表达式树里插入 RelabelType 或 FuncExpr 做 cast。复杂表达式里根据上下文推断结果类型,比如 CASE、COALESCE 等。
Analyze 的过程分解
Analyze 的三个入口(fixed/var/withcb)都遵循同一套路:创建 ParseState,写入 p_sourcetext、p_queryEnv,然后进入 transformTopLevelStmt()。例如 parse_analyze_fixedparams() 的注释也明确:它把 raw parse tree 转成 Query;optimizable statements 做较多转换;utility statements 挂到 CMD_UTILITY Query 上。
Analyzer 并不是“全局无状态”的纯函数,它需要一个 ParseState 作为语义环境,包含命名空间、range table、当前解析层级(子查询/CTE)、参数类型解析策略等。
Planner 不能在参数类型未定的情况下稳定选择函数/运算符/索引策略,因此 Analyzer 必须确保:
要么外部给定参数类型(prepared statement 常见)
parse_analyze_fixedparams():调用方提供每个$n的类型,引用未定义参数会被禁止。要么 Analyzer 能在语义上下文中推导,并最终确定下来
parse_analyze_varparams():允许从上下文推断$n的类型,并可能扩展paramTypes[]。
而在 postgres.c 的 pg_analyze_and_rewrite_varparams() 里还有一个关键“收口动作”:Analyze 完成后会检查每个参数类型都必须被确定,否则直接报错could not determine data type of parameter $n。
Analyzer 允许做语法层面的规范化,但会非常克制。因为语义规则只允许顶层出现,所以这类转换通常只在顶层做。做完后把结构整理成后续 transform 过程更统一的形态,从而减少分支复杂度。非常典型的例子是,transformTopLevelStmt()处理 SELECT ... INTO 时,会将其转换为CreateTableAsStmt,同时会清空原 SelectStmt 的 intoClause,避免后续在不允许的位置出现 INTO 时无法报错。
Analyzer 的产物要给 Planner/Executor 用,但很多 utility 命令不走 Planner(或在 utility 执行时才解析内部对象),所以 Analyzer 采用只对需要优化/执行语义绑定的语句做重分析的策略。也就是说Analyzer 不是对所有语句都深度 transform。
stmt_requires_parse_analysis() 把语句分成三类:
Optimizable statements:
SELECT/INSERT/UPDATE/DELETE/MERGE/...等,返回 trueSpecial cases:
DECLARE CURSOR/EXPLAIN/CREATE TABLE AS/CALL等也返回 true(因为内部有可优化语句)其它语句:一般不深度分析,最终会包进
CMD_UTILITYQuery
子查询分析必须满足两条,作用域隔离及语义一致。前者的意思是子查询能看到外层哪些名字、哪些锁/依赖可以继承,需要明确控制,后者则是 unknown 类型常量是否要在子层被强行 resolve,必须是可配置策略,避免破坏 SQL 语义。例如
SELECT * FROM employees WHERE salary = '1000';在这个查询中,'1000' 是一个字符串字面量,它的类型是 unknown,因为它没有显式指定类型。如果 PostgreSQL 使用 配置策略,它可能会选择将 '1000' 强制转换为 int4,这样就可以和 salary 列(假设是 int4 类型)进行比较。
以 SELECT/DML 这类可优化 Query 为例,在 Analyze 的末段会将 ParseState 中统计出来的语义特征写回 Query(如 hasSubLinks/hasWindowFuncs/hasAggs 等),然后 assign_query_collations()。若包含聚合,再 parseCheckAggregates(),并且源码明确说明:聚合检查必须在 collation 之后做,才能可靠比较表达式
Planner 很依赖这些语义标志和表达式正规化结果。有没有子链接、窗口函数、目标 SRF、聚合等,会直接影响规划空间与执行器节点选择。collation(排序规则)影响等价类、排序/哈希策略、索引可用性。聚合一致性检查属于语义合法性关口,必须在表达式结构稳定后执行。
Analyzer 是语义已经绑定但尚未 rewrite/plan的关键阶段点。对审计/安全/统计插件而言,这是最佳切入位置之一(结构完整、语义稳定、仍可记录原始位置与上下文)。
最后总结一下Analyzer语义绑定的内容
重写器 Rewriter
Rewriter位于Analyzer之后,Planner之前。Analyze会产出query tree,还需要规则系统将这棵树进行重写,形成真正要被优化/执行的一组查询。规则可以让一条语句变成多条语句,或者直接变空。
重写器的工作流程
在 QueryRewrite()函数的注释里,非常明确的将重写器的工作分为了以下几步:
必要时先进行锁定和修补。
通常从Parser/Analyze出来的
query tree通常已经拿过该拿的锁。但是来自缓存或历史的query tree就必须补这一步。AcquireRewriteLocks()的职责不是改写逻辑,而是为改写/规划/执行提供 schema 稳定性。把涉及到的 relation 锁住,避免你在重写过程中表结构被并发 DDL 改掉;同时它还会做一些历史规则树里与 JOIN + dropped column 相关的修补(避免规则里保留了已删除列导致后续处理代价巨大)。处理
non-select规则这一步会把 INSERT/UPDATE/DELETE/MERGE 等写类语句按规则系统做改写。
DO INSTEAD:用规则动作替换原语句;对视图插入实际是写入
base table-- 创建表和视图及插入规则 CREATE TABLE t ( id int primary key, val text ); CREATE VIEW v AS SELECT id, val FROM t; CREATE RULE v_ins AS ON INSERT TO v DO INSTEAD INSERT INTO t(id, val) VALUES (NEW.id, NEW.val); -- 当执行 INSERT INTO v(id, val) VALUES (1, 'a'); -- 重写器会将语句改写为 INSERT INTO t(id, val) VALUES (1, 'a');DO ALSO:在原语句基础上追加动作(因此可能产生多条 Query);比如更新业务表的同时写审计表
-- 原表 CREATE TABLE acct ( id int primary key, balance int ); -- 审计表 CREATE TABLE acct_audit ( id int, old_bal int, new_bal int, ts timestamptz default now() ); -- 规则 CREATE RULE acct_upd_audit AS ON UPDATE TO acct DO ALSO INSERT INTO acct_audit(id, old_bal, new_bal) VALUES (OLD.id, OLD.balance, NEW.balance); -- 当执行以下语句时 UPDATE acct SET balance = balance + 100 WHERE id = 1; -- 重写器等效 -- 1. 追加的审计 INSERT INSERT INTO acct_audit(id, old_bal, new_bal) VALUES (OLD.id, OLD.balance, NEW.balance); -- 2. 原始 UPDATE 仍然执行 UPDATE acct SET balance = balance + 100 WHERE id = 1; -- 所以最少产生了两条queryDO INSTEAD NOTHING:抑制原语句(可能导致最终 0 条 Query);无条件 NOTHING:整条语句被吃掉
CREATE TABLE t2(id int); CREATE RULE t2_no_delete AS ON DELETE TO t2 DO INSTEAD NOTHING; DELETE FROM t2; -- 没有任何可执行查询带条件 NOTHING:只拦截一部分行,就是分流
ALTER TABLE t2 ADD COLUMN protected bool default false; CREATE RULE t2_no_delete_protected AS ON DELETE TO t2 WHERE OLD.protected DO INSTEAD NOTHING; DELETE FROM t2; -- 重写器的等效结果 DELETE FROM t2 WHERE NOT OLD.protected;处理视图展开及安全条件注入
RIR(Retrieve-Instead-Retrieve)可以把它理解成,视图就是一条 SELECT 规则。因此在 这一步 会对每个 Query 做 视图展开(把对 view 的引用替换成 view 定义的子查询/连接树)。
QueryRewrite()在 Step 2 对每条 query 调用fireRIRrules()的动作在源码里是显式写出来的。同时,这一步也是RLS(Row Level Security)策略被注入
securityQuals/withCheckOptions的关键阶段。如果这些策略表达式里包含子查询(SubLinks),还需要额外处理锁与递归展开。当规则把 1 条语句改写成多条语句时,PG 仍需要决定哪个 Query 可以设置
canSetTag(影响客户端看到的 command tag / 影响行数显示等)。QueryRewrite()在 Step 3 专门做了这件事。

需要注意的是,重写器和触发器的区别,两者看似有相似的功能,但是本质不同。
规则(RULE)属于查询重写(Rewriter):在规划器之前,把你的语句改写/展开为另一棵查询树(甚至多条查询),然后再去计划与执行。
RULE:宏展开/改写 SQL(执行前改要执行什么)
触发器(TRIGGER)属于执行器(Executor):语句开始执行后,在
BEFORE/AFTER/INSTEAD OF的时点被调用,可按“每行”或“每语句”触发TRIGGER:运行时回调(执行中/执行后做“额外动作或校验”)
规划器 Planner/Optimizer
Rewriter 之后的 Query tree具备语义已确定、规则已展开、视图/规则已改写的特征。通过planner最终输出为可执行的 Plan tree,一棵封装于PlannedStmt数据结构中的规划树。Executor 只需要按节点类型逐层执行即可。
Planner的本质并不是字面上的生成一个计划,而是枚举候选执行路径,而后基于统计信息与代价模型(Cost Model)给每条路径定价,在这些路径中选择全局最优或近似最优的路径组合,最后把选中的 Path 具体化成 Plan 节点树。
Planner的核心模型
Planner的核心数据模型有如下三个
规划的核心动作,就是不断构造 RelOptInfo,往里面塞入不同的 Path(候选走法),再做比较选择。pathnode.c 里能看到 Path 成本比较的思想:比较的是 startup/total cost 等指标,而不是看起来哪个更快。
Planner的主流程
1. 把 Query 变成更适合优化的形态
在 planner.c 里能看到大量 preprocess_*:
preprocess_expression():对表达式做预处理,为后续等价推导、常量折叠、规范化做铺垫。preprocess_qual_conditions():处理 WHERE/JOIN 条件,使其更利于选择性估算和路径生成。preprocess_limit():把 LIMIT/OFFSET 这种“只要前 N 行”的信息提早注入优化过程,会显著影响 join 策略、排序策略。grouping_planner():负责聚合、排序、窗口函数、distinct、limit 等“上层关系”的规划。
这一阶段的目的是让查询树更规整、更可推导,把会影响全局策略的信息(如 LIMIT)提前暴露给代价模型。
2. 扫描路径生成
对每个 base relation(单表),Planner 会生成一组访问路径(pathlist):
Seq Scan(全表扫)
Index Scan / Index Only Scan(索引扫)
Bitmap Index + Bitmap Heap(位图路径)
Parallel 相关路径(如果可并行)
在 allpaths.c 的 set_rel_pathlist()/相关链路里,你可以看到它会把 SeqScan 和 Index paths 都先塞进候选集中(例如 create_seqscan_path()、create_index_paths()),后面再让 cost 模型去淘汰。
这一阶段的目的是构造一个全集性的可行性路径集合。
3. join搜索
当 FROM 里有多表,Planner 会经历一个关键阶段:枚举 join 关系。先把单表 RelOptInfo 都建好,然后尝试把它们两两 join 成更大的 RelOptInfo,再把更大的 Rel 与剩余 Rel 继续 join,直到形成最终的all-join Rel。
make_one_rel() 是典型的“把 join 问题收敛到一个最终 RelOptInfo的关键入口之一。
而 join 顺序搜索可能采用:
动态规划式的标准 join search
或达到阈值后启用 GEQO(遗传算法) 做近似搜索,避免组合爆炸。
join 顺序决定了中间结果规模,而中间结果规模又决定了整体代价,所以必须作为全局优化问题处理。
4. 上层关系规划
这一步很多人容易误解为执行器的事,但其实它强烈影响 join 策略和 scan 策略。
grouping_planner()在这一层做以下工作:
聚合(HashAgg/SortAgg)
DISTINCT(通常转成 Unique/HashAggregate 等变体)
ORDER BY(Sort/Incremental Sort)
WINDOW(WindowAgg)
LIMIT(Limit)
组合成上层 Rel 的候选路径,并把“上层需求”(比如必须有序)用 PathKeys 等形式传递下去(从而反向影响下层是否选择能天然输出有序结果的 IndexPath)。
5. 执行方案落地
当 cheapest Path 确定后,Planner 进入“具体化”阶段,把抽象的 Path 递归转换成具体 Plan 节点(SeqScan、IndexScan、NestLoop、HashJoin、Sort…)。
在 createplan.c 你能看到大量 create_*_plan() 用于把不同 Path 落成对应 Plan 节点。例如 create_seqscan_plan(),其中会对 qual 做排序、抽取实际表达式、替换 nestloop 参数等。
优化阶段只需要比较走法,真正执行需要具体节点与可执行表达式结构。
Planner的影响因素
Planner的选择不是靠拍脑袋,主要依赖两方面因素:
统计信息
统计信息来自
ANALYZE收集的统计(以及扩展统计),影响 selectivity、基数估算、join 结果行数估算。代价参数
如
random_page_cost、seq_page_cost、cpu_tuple_cost、work_mem、并行相关参数等,用于把 I/O 与 CPU 折算成统一成本标尺。成本计算相关实现在costsize.c等模块中。
对应上面两个因素,我们在explain的时候,结果的偏差往往也可以归结于这两方面:
估算行数不准,统计问题、谓词相关性、数据倾斜、参数化谓词导致 generic plan 偏差。
成本参数与真实硬件/负载不匹配。尤其
random_page_cost、并行收益、work_mem 对 hash/sort 的拐点。
这里不展开讨论调优问题。往往调优是系统性的平衡问题,在调优之上则是安全,这会在其他章节详细讨论。
执行器 Executor
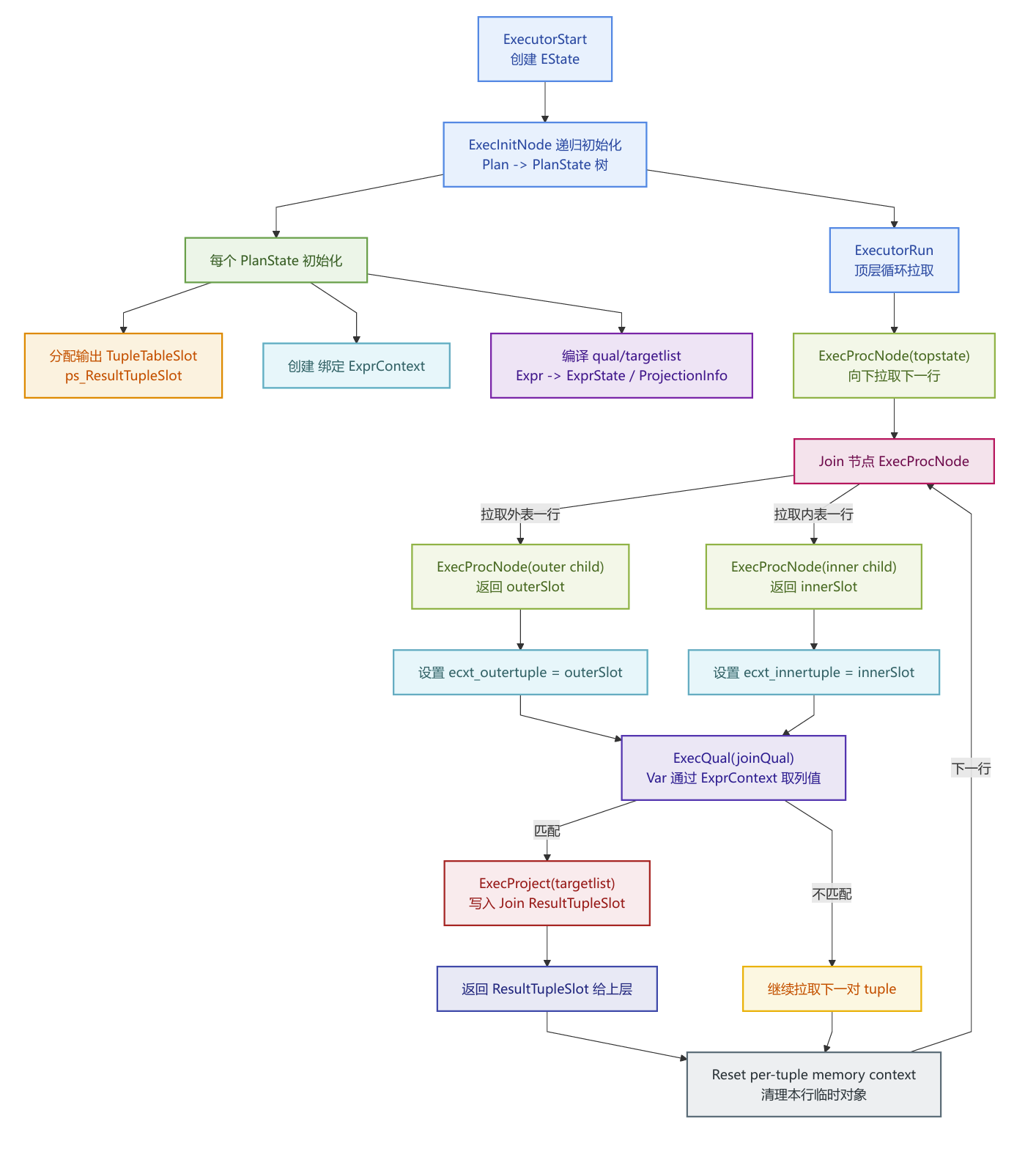
执行器是整个流程的最后一步,Planner解决的是怎么做便宜,Executor解决的是怎么把它做出来,就是把 Plan tree 实例化成 PlanState tree,静态的规划树的每个节点都会变为一个运行态对象PlanState。其中包含了子节点指针(left/right),输出 slot(TupleTableSlot),节点内部状态(例如 HashJoin 的 hash table、Sort 的 tuplestore),编译好的表达式执行状态(ExprState)。
之后会按节点类型分派执行逻辑,不同节点类型有不同的执行函数,ExecProcNode(node)里根据 nodeTag 分派到 ExecSeqScan / ExecHashJoin / ExecSort / ExecAgg 。
以迭代器的火山模型驱动整个树,顶层不断向下要一行,下层算出一行再返回,直到返回 NULL 表示结束。
Plan tree 是程序的 AST,Executor 是解释执行 AST 的虚拟机。
运行时系统
除了上面的plan tree转换工作,执行器还有一个重要的职能就是运行时系统。具体而言,就是数据库执行需要大量运行期协作,Executor 需要承担更多的任务:
MVCC 可见性与快照
快照
Snapshot决定select 读到哪个版本的行,行是否可见。Executor 在扫描阶段会对拿到的 tuple 做可见性判断,不符合当前快照的版本会被直接跳过。锁与并发一致性
UPDATE/DELETE 必须锁住目标行(行锁),并处理并发冲突。READ COMMITTED 下还可能需要 EPQ(EvalPlanQual)重检:发现行在你扫描后被别人改了,需要重新拉取并用原条件再判断一次,以保证语义一致。
表达式求值与 per-tuple 内存管理
WHERE 条件、JOIN 条件、SELECT 列表达式、函数调用、类型转换,全部在 Executor 里执行。为了性能与防泄漏,Executor 使用每行重置的内存上下文(per-tuple context),一行计算完就 reset,一次性释放这一行求值产生的临时对象。
触发器、约束、索引维护
这可以看做是DML 的真正成本。
BEFORE/AFTER 触发器、约束检查(NOT NULL/CHECK/外键等)、更新索引条目,全部发生在执行期。所以同样一条 UPDATE,Planner 选了同样的 scan/join 路径,执行时间也可能因为触发器/索引数量差异而天差地别。
产生结果行与输出
执行器的输出有两类:
SELECT:产生一个个结果行(tuple),送给 DestReceiver,客户端
/CTAS/INSERT SELECT的接收端等。INSERT/UPDATE/DELETE/MERGE:通过 ModifyTable 节点驱动,产生受影响行数,并进行写入与索引维护/触发器执行。
SELECT 路径
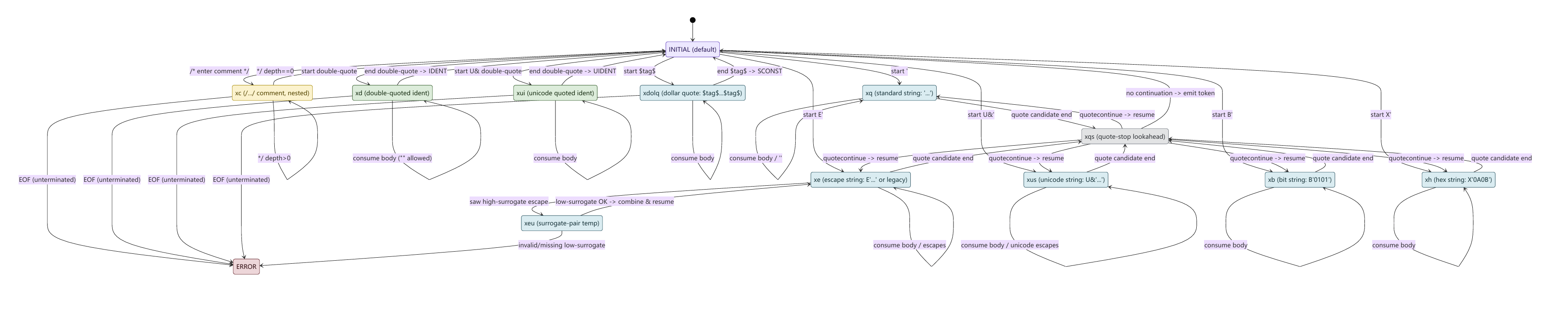
SELECT 的执行几乎都可理解为顶层节点(Limit / Sort / Agg / Result)开始循环,然后顶层向子节点拉取 tuple(ExecProcNode(child))。子节点继续向更下层拉取,直到 scan 节点从表/索引里拿到 tuple。拿到tuple后会对 tuple 执行过滤ExecQual(WHERE / JOIN qual)和投影ExecProject(SELECT 列表达式)。最后返回一行给上层,最终交给 DestReceiver。为了更直观理解这个过程,举例如下:
SELECT c.id, c.name
FROM customer c
WHERE c.status = 'ACTIVE'
ORDER BY c.created_at DESC
LIMIT 10;典型计划树可能是Limit → Sort → SeqScan(customer)。
Executor 的工作过程如下
Limit 节点要 10 行 → 找 Sort 要行
Sort 必须先把下层全部读完(阻塞算子)→ 去 SeqScan 拉行
SeqScan 每拿到一行就做可见性判断 → ExecQual 过滤 status
合格行交给 Sort 收集、排序
Sort 排完开始逐行吐 → Limit 吐前 10 行 → DestReceiver 输出
DML 路径
DML 的核心不是“输出行”,而是把上游产生的行变成实际写入动作。这条链路的总入口节点通常是 ModifyTable。
上游子计划负责找出要改哪些行 / 新行是什么,而ModifyTable 负责对目标表执行 Insert/Update/Delete/Merge;触发器与约束;索引维护;统计受影响行数;如果有 RETURNING,再把返回行送给 DestReceiver。
UPDATE 的逐行执行过程
定位目标行。上游子计划产生目标行标识,比如 ctid 或者旧 tuple。
行锁与并发处理。对目标行加锁,如在 READ COMMITTED 下发现并发更新,可能触发 EPQ 重检:重新取最新版本,并重新判断条件
计算新行(new tuple)。评估
SET表达式、类型转换、生成新 tupleBEFORE ROW 触发器。触发器可以修改 NEW 值,甚至跳过本次更新
约束检查。
NOT NULL / CHECK和外键约束执行 heap 更新。写入新版本 tuple,MVCC:旧版本并不物理删除。可能发生 HOT 更新(减少索引维护),也可能需要更新索引。
索引维护。对涉及的索引写入/更新条目(多索引会显著增加开销)。
AFTER ROW 触发器
RETURNING(若存在)。将 RETURNING 计算结果作为 tuple 输出给 DestReceiver
update,delete,insert的过程类似,只是核心动作从更新旧行版本变成插入新行或标记删除版本。
执行器的核心原理
在 PostgreSQL 的执行器里,每个 Plan 节点在运行时都会对应一个 PlanState,并遵循同一套生命周期接口。
Init:初始化节点状态(打开关系/准备表达式/准备 slot/准备私有状态)ExecInitNode(node)
Next:获取下一行(返回一个
TupleTableSlot*,没有更多行时返回空)ExecProcNode(nodeState)End:释放资源 ExecEndNode(nodeState)
其中Next是核心操作。整个的过程是拉取式的,或者说是消费者驱动的。顶层节点(例如 Limit / Result / Gather / ModifyTable)需要一行结果时,调用子节点的 ExecProcNode()。子节点为了得到一行,继续调用它的子节点 ExecProcNode()。一直递归到最底层的 Scan 节点(SeqScan/IndexScan…)从存储层取到一行,然后逐层返回。当某个节点没有更多行时,它的 ExecProcNode() 返回空(NULL slot),上层据此认为该节点结束。
当一个节点不需要先读完全部输入就能输出第一行,并且能持续边读边吐,它就是流式/可流水线pipelining的。
典型流式节点有以下几类:
Scan:拿一行吐一行
Filter(
Qual):拿一行判断通过就吐,不通过就继续拿下一行Project:对一行计算表达式后吐出
Nested Loop Join:外表一行一行驱动内表探测,匹配到了就吐
阻塞算子会先把输入收集到内存/磁盘,处理完一大批后才开始输出第一行。这意味着流水线被破坏。阻塞节点有以下几类:
Sort:必须收集足够多数据排序后才开始输出HashJoin的 build 侧:通常要先 build 哈希表(至少要先读完 build 输入)HashAgg:通常要读完输入才能确定聚合结果(除非特殊场景)Materialize/CTE Scan(视具体实现/计划形态):可能提前物化WindowAgg:很多窗口需要看到分区内多行才能吐结果(部分可以边处理边吐,但仍可能需要缓冲)
所以我们在explain的时候要关注这些阻塞算子节点,因为其中的绝大部分节点超过work_mem就会产生磁盘IO,将中间结果写入临时文件
当上层不再拉取,下层自然停止。这就是早停机制。在拉取式模型中,停止执行不需要广播信号。只要上层节点在满足条件后不再调用子节点的 ExecProcNode(),子节点就不会继续做任何工作。
最常见触发早停的上层节点有Limit,Exists/SemiJoin 相关节点,某些聚合/子查询场景。下面举两个例子加深理解:
有效早停
SELECT * FROM t ORDER BY created_at DESC LIMIT 10;若存在匹配的索引(例如
created_at DESC),Planner 可能选IndexScan直接按顺序吐行,Limit → IndexScan(t using idx_created_at_desc),执行顺序如下:Limit拉 10 行IndexScan只需要读到 10 行就可以停全链路工作量近似 O(10)
早停失效
同样的 SQL,如果没有合适索引,计划可能就会是
Limit → Sort → SeqScan。执行顺序如下:Limit的确只需要 10 行但
Sort为了输出第一行就要先拿到全部输入并完成排序。所以SeqScan会被读完,Limit的“早停”到Sort这一层就被阻断了。LIMIT下方存在必须物化的节点(Sort/HashAgg/Hash build),早停就会大幅衰减甚至失效。
所以,早停能否带来收益,取决于 LIMIT 下面是不是阻塞算子。
关键数据结构
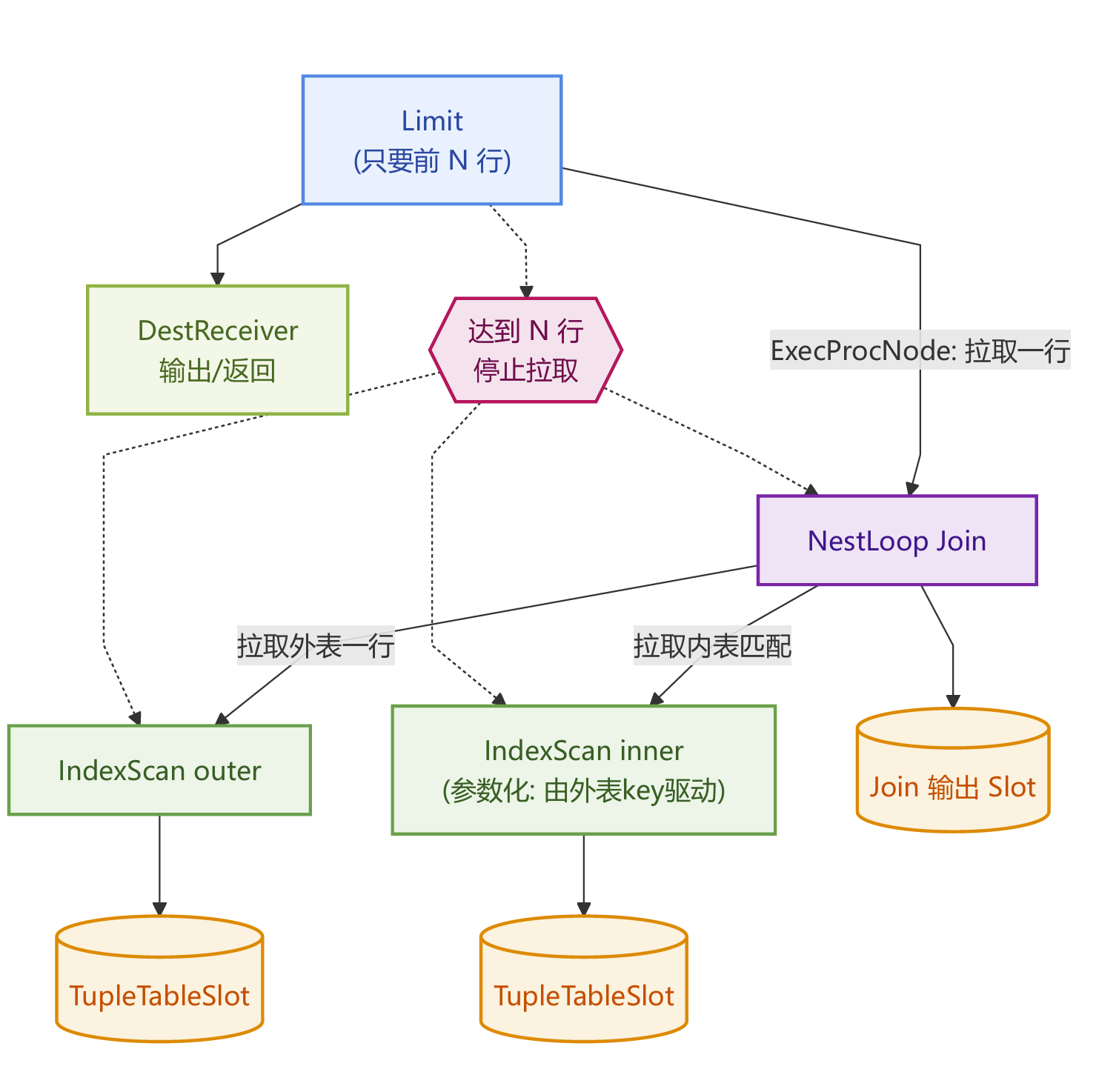
执行器有四个关键对象 EState、PlanState、TupleTableSlot、ExprContext。
数据结构总览:
EState
EState在初始化阶段ExecutorStart时被创建,贯穿 ExecutorRun 全过程,ExecutorEnd时被释放,或错误回滚时由事务/portal 上下文回收。
Estats里面的内容主要分为以下6类:
一致性与并发
当前 Snapshot即MVCC 可见性依据。当前命令 ID、事务语义相关状态。FOR UPDATE/行锁相关结构。
参数与子计划
外部参数、执行期参数,如嵌套循环参数、
SubPlan输出参数。子查询/子计划SubPlanState管理。目标关系
ResultRelInfo列表,INSERT/UPDATE/DELETE的目标表信息。索引信息、触发器信息、约束检查所需元数据。DML专用的核心内容。
TupleTable
语句执行期会创建大量 slots,例如scan 输出、join 输出、投影输出、临时存放。它们会统一挂在 EState 的 tuple table 里,便于统一释放。
内存上下文
这部分内容非常关键。
es_query_cxt,per-query 内存包含节点状态、表达式编译结果、哈希表/tuplestore 等。
es_tupleTable_cxt,执行器在计划树上会创建大量
TupleTableSlot,这些 slot 自身会分配values[] / nulls[]数组、values[] / nulls[]数组、还有一些 slot 内部结构。将 slot 相关分配集中到es_tupleTable_cxt的好处是slot 对象数量多、但结构相对规整,集中管理更清晰。Reset per-tuple 时不会影响 slot 自身结构。ExprContext ,per-tuple reset 的上下文。表达式求值非常依赖分配内存,
text || text拼接生成新 varlena,regexp_*/to_char/ JSON 处理生成中间对象,类型转换、数组构造、函数返回临时结构,TOAST 解压/解包等等,这些对象的生命周期都具备一个特点,只对当前一行有效,下一行就不需要了。所以执行器为表达式求值准备一个 per-tuple 上下文,每处理完一行:Reset 一次。好处是成本极低,且不会泄露。这也是PG可以跑大量表达式查询而内存不会被撑爆的原因之一。
统计与可观测性
EXPLAIN ANALYZE 的 instrumentation,节点计时、行数、缓冲等。
EState 把执行器运行所需的全局状态集中管理,避免每个节点各自持有互相引用导致生命周期难控。
PlanState
plan是Planner 的产物,是静态的,描述节点类型、表达式树、子节点结构等等。
PlanState是Executor 的产物,是动态的,即运行态。其中包含子节点 PlanState 指针,输出 slot、表达式执行状态ExprState
/ProjectionInfo,节点私有运行时结构,例如 HashJoin 的 hash table、Sort 的 tuplestore。
PlanState 的通用字段如下:
ps.lefttree / ps.righttree:子节点运行态
ps.ps_ResultTupleSlot:该节点对外输出的 slot
ps.qual(过滤条件):WHERE/JOIN qual 的执行态
Selection, σ关系代数中的选择在这一阶段执行,Planner会将选择这一操作分发到多个位置执行,而执行器在运行期对每一行调用ExecQual()来判断是否保留。Scan 节点上的过滤,
SeqScan的 Filter,IndexScan的 indexqual/recheckJoin 节点上的连接条件,joinqual(用于匹配)+ otherqual(用于额外过滤)
上层节点的残余过滤,有些条件不能下推,就会留在更上层节点过滤。
ps.targetlist / ProjectionInfo:SELECT 列投影(或上层节点需要的投影)
ps.ExprContext:该节点专属的 ExprContext(变量绑定、per-tuple 内存)
ExecProcNode 回调:该节点“拉取下一行”的具体实现(迭代器模型)
关系代数算子到 PG 执行节点的对应关系
TupleTableSlot
TupleTableSlot是执行器中的核心容器,贯穿整个执行器生命周期。
执行器里 tuple 的形态很多:
来自 heap 的物理行。通常就是我们观察
base table中带有ctid的的一行数据来自 join/投影计算的虚拟行。这些输出行往往没有对应的 HeapTuple,因此不会有
ctid、不会有 buffer、也不一定有物理行头部。为了减少拷贝的minimal tuple。HeapTuple 是面向表存储的结构,包含大量与存储/并发相关的信息,但执行器在很多场景并不需要完整的 heap 行头,用户列数据以及必要的 null bitmap/长度信息。
MinimalTuple更小、更轻,拷贝成本更低,适合在执行器内部暂存中间结果。buffer pin、TOAST展开策略等。当你从 heap 表读取一行时,这行数据在内存里通常来自共享缓冲区(shared buffers)中的某个 page。为了保证你在访问这行内容时,该 page 不会被回收/替换,tuple 指针在有效期内不悬空。执行器/存储层会对该 buffer 做 pin,就是钉住该页面,slot 持有的 heap tuple 指向 buffer page,buffer 被 pin 住,直到 slot 释放或被覆盖。slot 有时不是拷贝一份行数据,而是“引用 buffer 里的行并确保 buffer 不被换出。
TOAST 用于存储超长的变长字段(text/bytea/jsonb 等),可能以压缩或外部存储指针形式存在。对执行器来说有两个选择,立即展开和延迟展开,前者就是读到行就把大字段解压/拉回内存,后者只有当表达式/输出真的需要该列时才展开。PostgreSQL 倾向于能延迟就延迟。
Slot的作用,就是将这些形态各异,功能不同的tuple,统一到一种容器内,从而达到统一接口 + 延迟物化 + 降低拷贝。
Slot里有三类关键信息:
TupleDesc,这行有哪些列,类型是什么。
values/nulls 数组,解构后的列值缓存。
底层存储指针,
heap tuple / minimal tuple / virtual tuple。还有是否解构的标记
节点拿到一条 heap tuple 时,不一定立刻把每列都解出来。上层表达式要用某列时,slot 才去 deform(解构)并填 values/nulls(缓存起来)。这样能显著减少无用列的解构成本。
在 Volcano 模型里,ExecProcNode() 返回的就是 slot。一行在树上向上传递时,不是 copy 一份 heap tuple,而是返回一个 slot 引用。上层可以在自己输出 slot 中重新组装(投影/计算),也可以直接转发下层 slot。
ExprContext
表达式树(qual/targetlist)求值时,需要知道以下信息
Var(列引用)应该从哪一行取值?scantuple/outertuple/innertuple?参数(Param)从哪取?
这次求值产生的临时数据放哪?怎么快速释放?
ExprContext 正是把这些运行期的上下文绑定集中起来。
ecxt_scantuple,当前扫描输入行。
ecxt_outertuple,join 外表当前行。
ecxt_innertuple,join 内表当前行。
以上是三个使用非常频繁的slot指针。 Join 节点每比较一次匹配,都会反复更新 ExprContext 中的 outer/inner slot 指针,然后调用 ExecQual(joinqual)。
ExprContext 通常有两类内存上下文概念,per-query,表达式初始化后的执行态结构(长期存在);per-tuple:每行求值产生的临时对象(短期存在)。上面也提到过per-tuple这类内存上下文,每处理完一行就 reset per-tuple context,把临时分配一次性清空,目的是大查询不会因为表达式求值泄漏内存。
总结
SQL 全链路(Parser → Analyzer → Rewriter → Planner → Executor)
附录
动态规划算法
动态规划算法相较暴力破解可以快速的找出最优解。其核心是最优子结构和重叠子问题,前者的意思是整体最优解可以由若干个子问题的最优解组合出来,后者的意思是很多不同的决策路径会反复遇到相同子问题;DP 用记忆/表让每个子问题只算一次。
下面举个例子说明DP是如何进行规划的。
1. 问题的定义
4 张表 join,找最小 cost 的 join 顺序。
有 4 个关系 relation:A, B, C, D。
简化的基数与 join 选择性join selectivity:
行数(rows)
|A|=1000,|B|=100,|C|=10000,|D|=500join 图
A ⋈ B,选择性sAB = 0.01B ⋈ C,选择性sBC = 0.001C ⋈ D,选择性sCD = 0.05
其他组合视为没有 join 条件。在真实 planner 里通常会被认为是笛卡尔积,代价极高,通常会尽量避免/剪枝。
代价模型
扫描成本:cost_scan(X) = |X|
join 输出行数估算: rows(X ⋈ Y) = rows(X) * rows(Y) * sXY
join 成本估算:cost_join(X, Y) = cost(X) + cost(Y) + rows(X) * rows(Y)
这里把 join 的主要开销粗暴近似成两边输入行数的乘积。真实 PG 会更复杂:HashJoin/Sort/Merge/NL 的不同成本、I/O、CPU、work_mem 等。
2. DP 的状态定义
对 join 顺序问题,经典 DP 定义是dp[S] = 生成子集 S结果的最优方案。其中S 是表集合。
每个dp[S]有三个要素,best_cost[S],best_rows[S],best_plan[S]。
边界则是,对单表子集:dp[{X}] = (cost=|X|, rows=|X|, plan=Scan(X))。
事实上,PG 里不会只存一个标量 dp[S],它会把子集 S 对应成一个 joinrel:
RelOptInfo(S):对应集合S的优化对象pathlist(S):一组候选路径(Paths)cheapest_total_path(S)/cheapest_startup_path(S):从候选里选出来的“最优”路径
dp[S] = Paths(S)(一组非劣解),而不是单个解。
3. 确定最优子结构
假设 S={A,B,C,D} 的最优计划 P* 最后一步是把两棵子计划 join 起来,
那么可以断言,P1 必须是子集 X 的最优计划(同理 P2 是 Y 的最优计划)。
假设 P1 不是 X 的最优计划,那就存在另一个计划 P1',使得 cost(P1') < cost(P1),且输出等价(同样得到 X 的结果集合)。
那么把 P* 里的 P1 替换为 P1',得到新计划 P' = Join(P1', P2)。
由于 join 成本函数里包含 cost(P1) 这一项,且其它项不因替换而变大到抵消。会有 cost(P') < cost(P*),与 P* 最优矛盾。
所以 P1 必须最优。反证法证毕。
在真实 Planner 里,注意输出等价还包含:输出顺序、参数化依赖等维度,所以 PG 不是只存一个最优解,而是存一组 Pareto-最优 Path。因此 PG 的状态更像被 dominance 剪枝后的非劣集Paths(S) = { p1, p2, ... }
4. 确定重叠子问题
很多不同的大问题,都会用到同一子集的最优解:
求
dp[{A,B,C}]会用到dp[{A,B}]、dp[{B,C}]求
dp[{A,B,D}]也可能用到dp[{A,B}]求
dp[{B,C,D}]会用到dp[{B,C}]
dp[{A,B}]、dp[{B,C}] 这些子问题会被反复引用——这就是重叠子问题。
DP 把它们缓存下来,每个子集只算一次。
5. 决策与转移
决策就是每一步要选择什么。这包含三个层面:
把 S 切成哪两块。
Partition选一个非空真子集
X ⊂ S,令L = X,L = X。这代表最终计划的最后一步是Join( dp[L], dp[R] )。本质上,这就是 join 顺序问题的结构决策,最后一步 join 哪两块中间结果。
用哪种 join 算法。
Algorithm choice同一个
(L, R),可能有多种 join 算法候选,Nested Loop、Hash Join、Merge Join,是否parallel等。可以把 join 算法抽象为
m ∈ Methods(L, R)。可行性。
Feasibility连接性(joinable):
L与R之间必须存在可用 join 条件(或可推导的等价连接),否则就是笛卡尔积候选,通常应强剪枝。外连接合法性(legal):外连接/半连接会限制 join 重排,很多拆分是非法的。
物理性质约束(properties):例如 MergeJoin 要求两边可按 join key 排序(或能排序);参数化路径要求能用外层变量等。
所以一个可考虑的决策其实是三元组,决策 d = (L, R, m) 且满足可行性约束。
转移就是子问题“合成”父问题的过程。
一旦选定了 (L, R, m),转移就是取子问题最优解或候选集里某个解。在PG里用 Paths(L) 与 Paths(R)候选多解。
而后估算输出规模,rows_out = f_rows(rows[L], rows[R], join_clauses(L,R))。
估算代价,cost_out = f_cost(cost[L], cost[R], rows[L], rows[R], m, other_params)。
形成候选父解,candidate = (cost_out, rows_out, plan = (L,R,m))。
最后用 min/剪枝更新父状态。把 candidate path 加入 pathlist(S),再做 dominance 剪枝,最后更新 cheapest path。
6. 编写动态转移方程
对任意 S,|S| ≥ 2:
这句方程里每个部分是什么意思:
S:目标集合(要把这些表 join 起来)X ⊂ S且X ≠ ∅且X ≠ S:枚举所有“非空真子集”,等价于枚举所有二分切割(L=X, R=S\X)Methods(X, S\X):在这个切割上允许的 join 算法集合(含可行性过滤)Join_m(dp[X], dp[S\X]):把两个子计划用算法 m 合成父计划,得到一个候选计划(含 cost/rows)外层
min:从所有候选里挑 cost 最小的那个作为dp[S]
7. 手动计算
一步步填写DP表
单表之后是两表join,只计算有jion关系的
然后是三表
S = {A,B,C}
dp[{A,B,C}] 取最小:
cost=2,011,100,对应切分{A} | {B,C}(即A ⋈ (B ⋈ C))。S = {B,C,D}
dp[{B,C,D}] 取最小:
cost=1,510,600,对应切分{D} | {B,C}(即D ⋈ (B ⋈ C))。
最后是4表
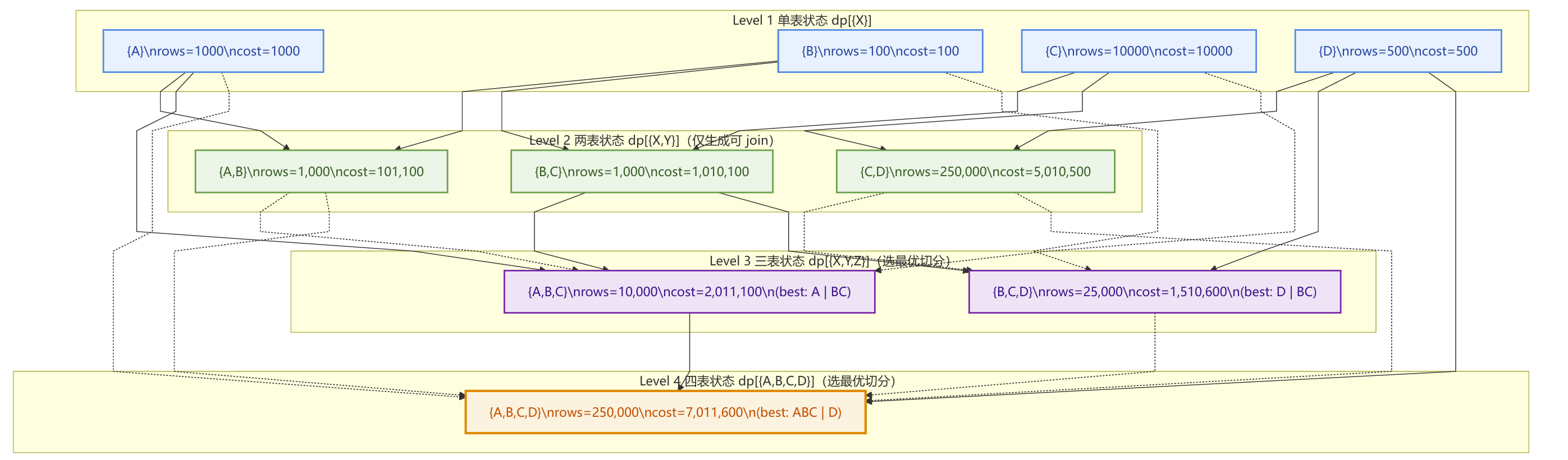
8. 伪代码
# 初始化
for each base rel i:
rel[i] = build_base_rel(i)
generate_base_paths(rel[i]) # seq/index/bitmap/partial...
# DP 按子集大小推进
join_rel_level[1] = { rel[i] }
for level = 2..N:
join_rel_level[level] = empty
# 生成 level 大小的 joinrel:常见两种扩展方式
# 1) left-deep: (level-1) + 1
for rel1 in join_rel_level[level-1]:
for rel2 in join_rel_level[1]:
if disjoint(rel1.relids, rel2.relids) and joinable(rel1, rel2) and legal(rel1, rel2):
joinrel = get_or_make_joinrel(rel1.relids ∪ rel2.relids)
generate_join_paths(joinrel, rel1, rel2) # NLJ/MJ/HJ + param paths + pathkeys
add_to_level(join_rel_level[level], joinrel)
# 2) bushy: k + (level-k)(能显著提升质量,但组合更多)
for k = 2..floor(level/2):
for rel1 in join_rel_level[k]:
for rel2 in join_rel_level[level-k]:
if disjoint(...) and joinable(...) and legal(...):
...遗传算法
有了DP为什么还要遗传算法呢?
暴力枚举 join 顺序接近 n!,按照子集做动态规划,通常复杂度也会是指数级的,只枚举 left-deep 时常用近似 O_{(n^2·2^n)},若允许 bushy进行更完整的二分拆分,复杂度在最坏情况下会更接近 O_{(3^n)} 量级。指数级说到底也不是常量级,可以参考下面的保守估计表
光 n=25 的子集数就三千多万;而 DP 并不是“每个子集算一次就完”,还要对每个子集做切分、生成 join path、比较成本。最终只能是穷尽CPU算力,中间结果填满内存。当估算本来就有偏差时,花极大规划时间去找模型内的全局最优,对真实运行未必带来同等收益,反而可能让planning time成为瓶颈。
当 n 很大时,Planner 的目标从证明最优变为在可接受时间内找到足够好的计划。遗传算法不再遍历几百万/几千万个子集组合,转而仅仅进行评估,种群规模 × 代数 次候选顺序。用选择/交叉/变异把搜索集中在更可能低成本的区域。其哲学是牺牲最优保证,换取规划时间可控。
动态规划的算法枚举S子集,并构造 joinrel(S),复杂度指数级增长。遗传算法 GEQO(Genetic Query Optimizer)是在jion数量超过阈值的时候,不再做完整 DP 枚举,而是把join 顺序当作搜索空间,用遗传算法在有限评估次数内找一个足够好的 join 顺序。后者替代的是前者的搜索策略,而不是整个优化器,后者仍然要依赖以下对象:
单表访问路径生成(seq/index/bitmap/parallel)
join 算法选择(NLJ/HJ/MJ 等)
代价模型(cost + rows 估算)
上层规划(group/order/limit 等)
1. 标记染色体
遗传算法的状态不是 dp[S],而是一个候选 join 顺序。
假设需要 join 的关系集合为 {R_1..R_n},则一个个体(individual)用一个排列表示:
你可以把它理解为基因序列:每个基因是一个关系 ID(或 Planner 内部对应的 relid)。
每个个体都有一个 fitness(适应度),通常由计划的 估算 cost 反推得到(cost 越小越好)。个体会组成种群:
2. 基因筛选策略
Selection
从当前种群
P中按适应度偏好选出父代,更低 cost 的个体,被选中的概率更大,但不会只选最优,目的是要保留多样性,避免陷入局部最优。Crossover / Recombination
把两个父代 join 顺序组合成新的顺序,但必须满足排列约束:子代不能重复某个关系,以及子代不能丢失某个关系。在PG的
GEQO算法实现中,采用适合排列问题的交叉算子,尽量保留父代中较好的相邻结构/片段,否则子代质量极不稳定。Mutation
突变就是对新生成的顺序做小幅随机扰动,常见方法有交换两个位置、反转一段、插入移动等。其目的还是跳出局部最优,维持搜索空间探索能力。
3. 遗传过程
从 P_t 选择父代对
对每对父代做交叉得到子代
对子代做一定概率突变
评估子代 fitness,怎么评估一个 join 顺序的 fitness是整个遗传过程的关键部分。
用某种“替换策略”形成下一代 P_{t+1}。常见做法是保留部分精英(
elitism),其余用子代填充。
GEQO 的目标与 Planner 的目标一致,都是最小化估算执行成本(total cost)
4. 评估函数 Evaluation
fitness函数往往是遗传算法的核心所在,但是和以往的纯算法不同,PG的GEQO是调用 Planner 的能力对该顺序做一次受约束的规划。
给定顺序
评估通常会构造一个jion过程,直觉上类似left-deep
J_2 = best\_join(r_1, r_2)
J_3 = best\_join(J_2, r_3)
...
J_n = best\_join(J_{n-1}, r_n)
其中 best_join(X,Y) 并不是固定 HashJoin 或 NLJ,而是在给定输入形态下,挑出代价最低的 join path。所以 GEQO 并不是顺序一固定就死了,它仍会在每一步使用代价模型挑 join 方法与访问路径。它只是把顺序搜索从 DP 枚举换成 GA 搜索。
join 顺序决定中间结果规模,影响最大。在固定顺序下再做局部最优(每一步挑 cheapest join 方法),能在有限时间内给出顺序的可比成本,用这个成本做 fitness,就能驱动 GA 在顺序空间里进化。
5. 伪代码
令 Order 表示一个排列(join 顺序):
其中 Plan(Order) 是在该顺序约束下由 Planner 生成的计划,Cost 是 Planner 的成本估算输出。
一代的伪代码如下
P0 = InitPopulation(k) # k 个随机顺序(排列)
EvaluateFitness(P0) # 调 Planner 估算 cost → fitness
for gen = 1..G:
P_new = EliteKeep(P_{gen-1}) # 可选:保留少量最优个体(精英策略)
while |P_new| < k:
p1 = Select(P_{gen-1}) # 按 fitness 偏置选择
p2 = Select(P_{gen-1})
child = Crossover(p1, p2) # 排列交叉(保证无重复无缺失)
child = Mutate(child, pm) # 以概率 pm 做小扰动
EvaluateFitness(child)
P_new.add(child)
P_gen = Replace(P_{gen-1}, P_new) # 形成新一代
return BestIndividual(P_G)