

本文翻译自oracle官方文档,仅供学习使用
Database Server
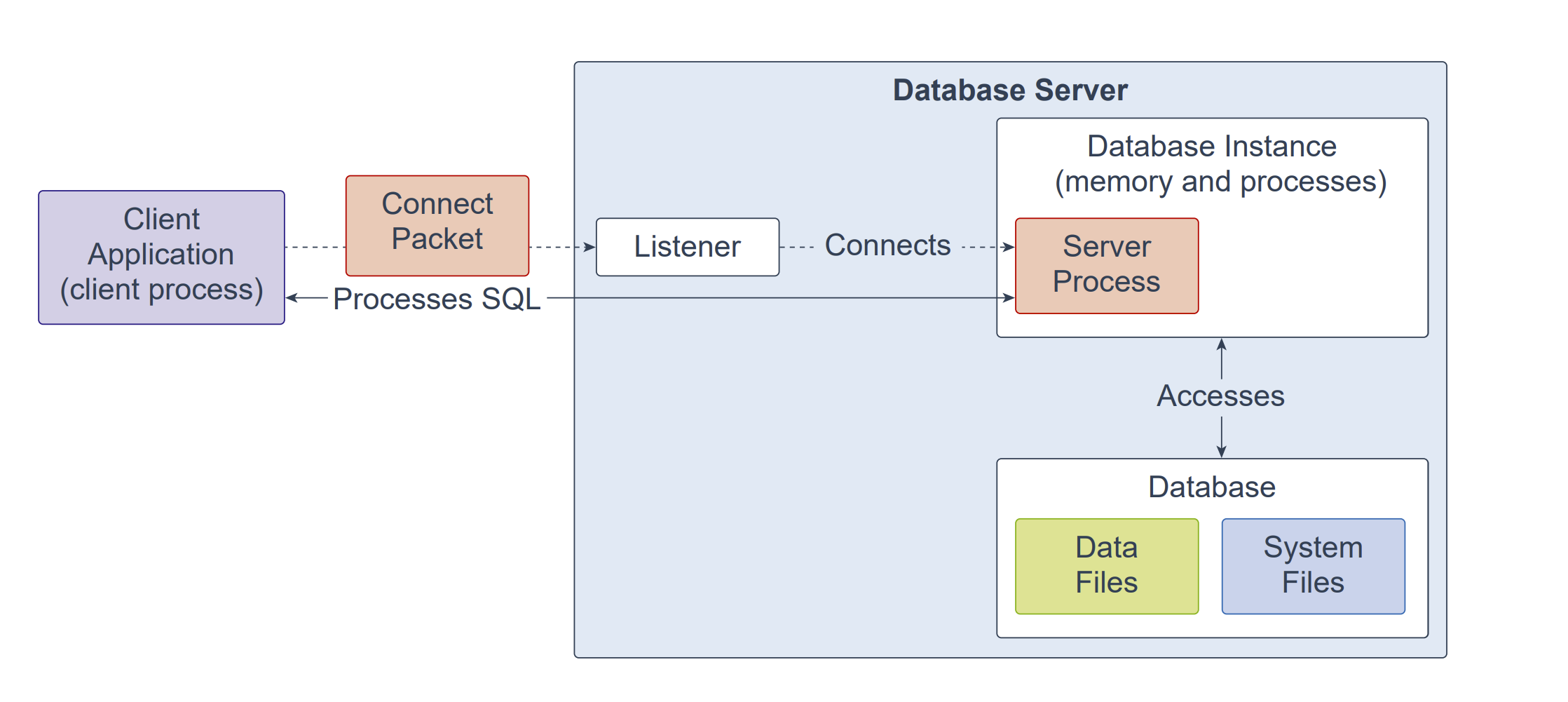
Oracle 数据库由至少一个数据库实例(instance)和一个数据库(database)组成。数据库实例负责内存与进程的处理。数据库由称为数据文件(data files)的物理文件构成,并且可以是非容器数据库(non-CDB)或多租户容器数据库(CDB)。Oracle 数据库在运行期间还会使用若干数据库系统文件。
单实例数据库架构由一个数据库实例和一个数据库组成。数据库与数据库实例之间是一对一关系。可以在同一台服务器上安装多个单实例数据库,每个数据库均拥有独立的数据库实例。该配置有利于在同一台机器上运行不同版本的 Oracle 数据库。
Oracle Real Application Clusters(Oracle RAC)数据库架构由运行在不同服务器上的多个实例组成,它们共享同一个数据库。该服务器集群对外在一端表现为单一服务器,对另一端的终端用户与应用而言亦如是。此配置旨在实现高可用性、可扩展性以及高端性能。
监听器(listener)是一个数据库服务器进程。它接收客户端请求,建立到数据库实例(instance)的连接,然后将该客户端连接移交给服务器进程(server process)。监听器既可以在数据库服务器本地运行,也可以以远程方式运行。典型的 Oracle RAC 环境通常采用远程方式运行。
Database Instance
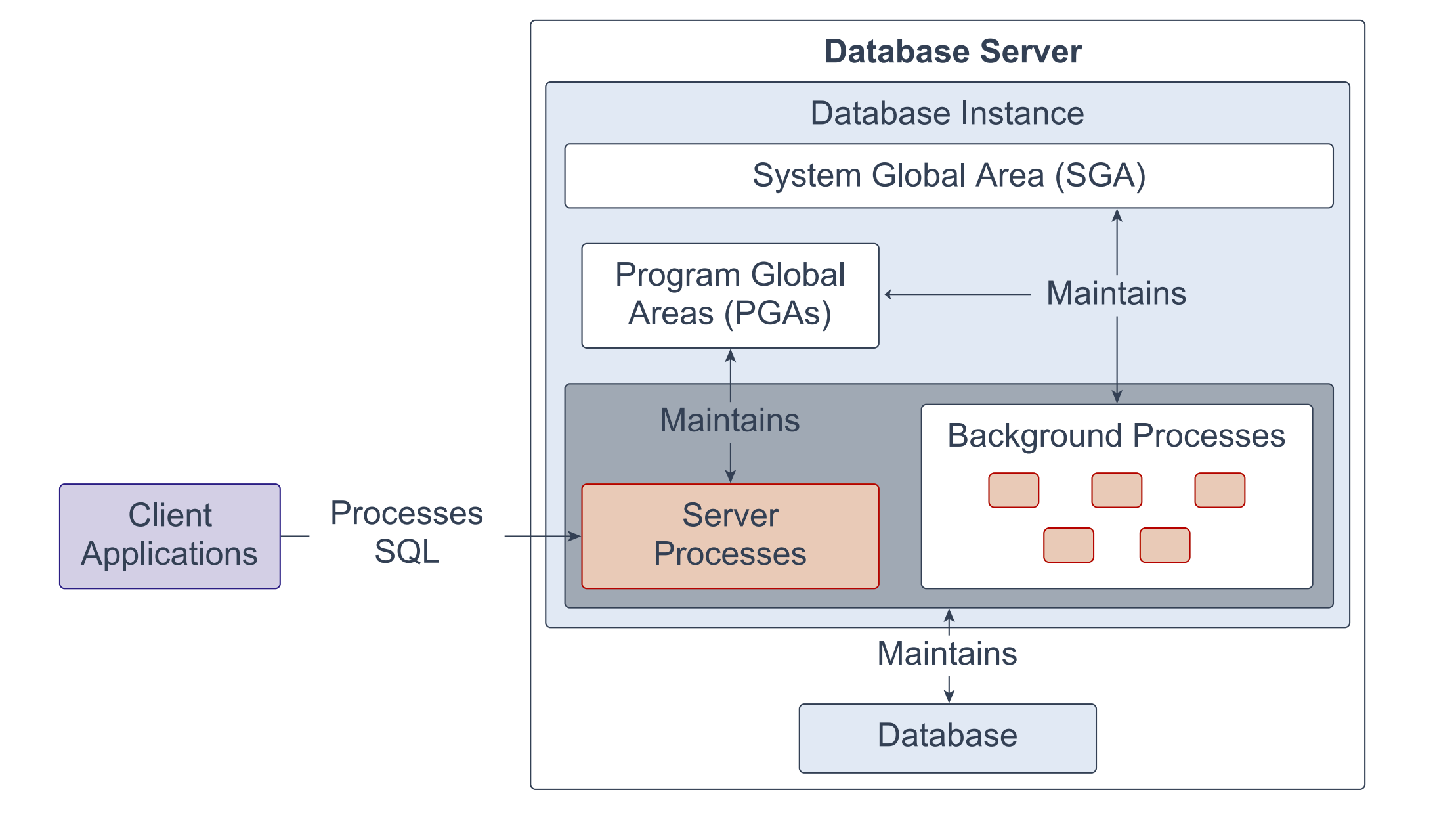
一个数据库实例(database instance)由一组 Oracle 数据库的后台进程(background processes)和内存结构构成。主要的内存结构包括系统全局区(SGA,System Global Area)和程序全局区(PGA,Program Global Area,复数为 PGAs)。后台进程对数据库中已存储的数据(数据文件,data files)进行操作,并使用这些内存结构完成工作。数据库实例仅存在于内存中。
Oracle 数据库还会创建服务器进程(server processes),代表客户端程序处理与数据库的连接,并为客户端程序执行具体工作;例如解析与运行 SQL 语句、检索结果并返回给客户端程序。此类服务器进程也称为前台进程(foreground processes)。
更多信息,参见 Oracle Database Instance。
System Global Area
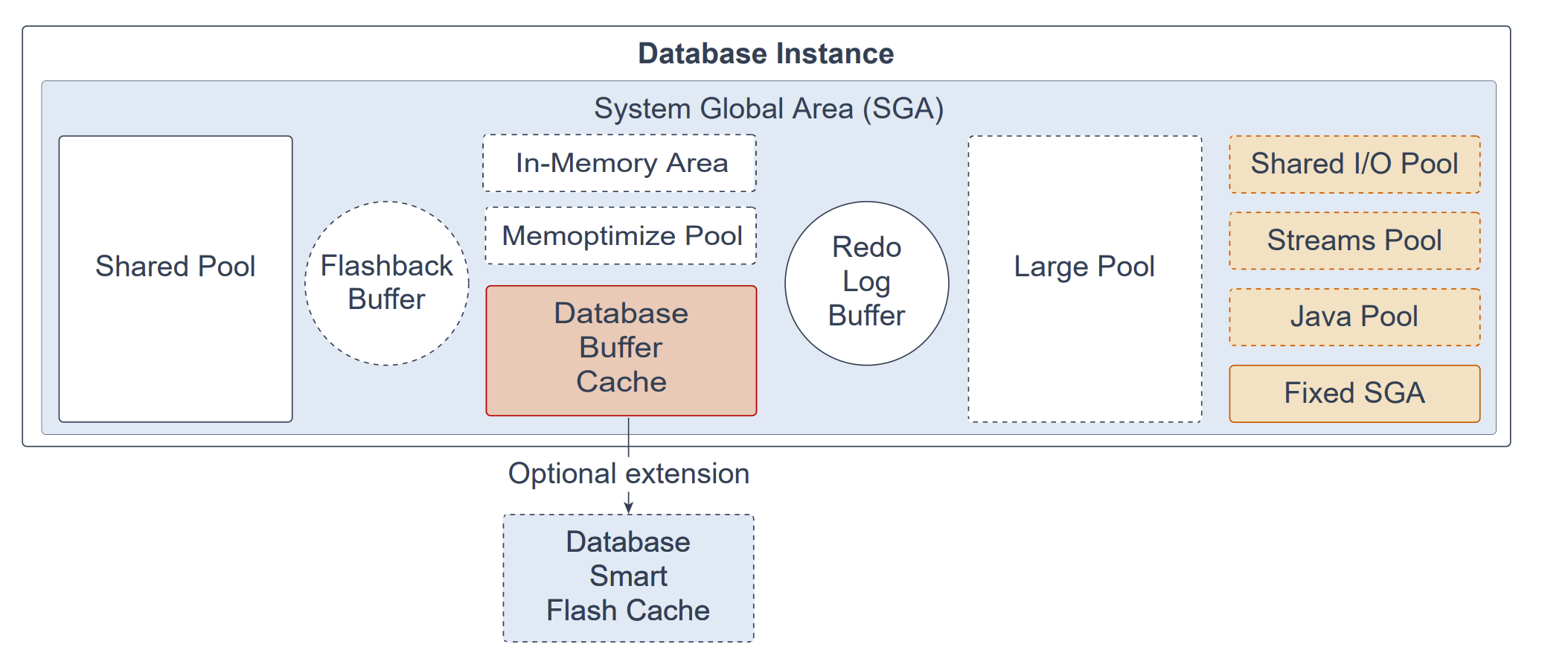
系统全局区(SGA, System Global Area)是为某个 Oracle 数据库实例(instance)保存数据与控制信息的内存区域。所有服务器进程与后台进程共享 SGA。启动数据库实例时,系统会显示为 SGA 分配的内存大小。SGA 包含以下数据结构:
共享池(Shared Pool):缓存可在用户之间共享的各种构件;例如已解析的 SQL、PL/SQL 代码、系统参数以及数据字典信息。共享池几乎参与数据库中发生的每一项操作。例如,当用户执行一条 SQL 语句时,Oracle 数据库就会访问共享池。
闪回缓冲区(Flashback Buffer):这是 SGA 中的可选组件。启用闪回数据库(Flashback Database)后,会启动名为恢复写入进程(Recovery Writer Process,RVWR)的后台进程。RVWR 会定期将已修改的数据块从缓冲区缓存复制到闪回缓冲区,并按顺序把闪回数据库的数据从闪回缓冲区写入闪回数据库日志(Flashback Database logs),这些日志循环复用。
数据库缓冲区缓存(Database Buffer Cache):用于存放从数据文件读取的数据块副本的内存区域。缓冲区(buffer)是主内存中的一个地址,缓冲区管理器会在此临时缓存当前或最近使用的数据块。所有并发连接到同一数据库实例的用户都共享对该缓冲区缓存的访问。
数据库智能闪存缓存(Database Smart Flash Cache):在 Solaris 或 Oracle Linux 上运行的数据库可选择启用的数据库缓冲区缓存的内存扩展,为数据库块提供二级缓存。它可提升以读取为主的联机事务处理(OLTP)工作负载,以及数据仓库(DW)环境中的临时查询与批量数据修改的响应时间与总体吞吐量。数据库智能闪存缓存位于一个或多个闪存磁盘设备上(使用闪存存储的固态设备),通常比增加主内存更经济,且其速度比机械磁盘快一个数量级。
重做日志缓冲区(Redo Log Buffer):位于 SGA 中的环形缓冲区,用于保存对数据库所做更改的信息。该信息以重做条目(redo entries)的形式存储。重做条目包含重建(或重做)由数据操纵语言(DML)、数据定义语言(DDL)或内部操作对数据库所做更改所需的信息;在需要时用于数据库恢复。
大型池(Large Pool):一种可选的内存区域,面向比共享池(shared pool)更大的内存分配。大型池可为共享服务器的用户全局区(UGA)、Oracle XA 接口(用于事务与多个数据库交互的场景)、语句并行执行所用的消息缓冲区、Recovery Manager(RMAN)I/O 从进程的缓冲区,以及延迟插入(deferred inserts)提供大块内存分配。
内存区域(In-Memory Area):可选组件,使对象(表、分区及其他类型)以一种称为列式(columnar)的新格式存放在内存中。该格式使扫描、连接与聚合相比传统的磁盘行式格式快得多,从而同时为 OLTP 与 DW 环境提供快速报表与 DML 性能。此特性对那类“在少数列上操作但返回大量行”的分析型应用尤为有用,而非典型 OLTP(在少数行上操作但返回许多列)。
内存优化池(Memoptimize Pool):可选组件,为基于键的查询提供高性能与可扩展性。Memoptimize Pool 包含两部分:memoptimize 缓冲区区域与哈希索引(hash index)。快速查找利用该池中的哈希索引结构,对启用了
MEMOPTIMIZE FOR READ的给定表的数据块进行快速访问,这些数据块会被永久固定(pinned)在缓冲区缓存中以避免磁盘 I/O。Memoptimize Pool 中的缓冲与数据库缓冲区缓存完全分离。当配置“Memoptimized Rowstore”时会创建哈希索引,并由 Oracle 数据库自动维护。共享 I/O 池(SecureFiles)(Shared I/O Pool):用于对 SecureFile 大对象(LOBs)的各类大规模 I/O 操作。LOB 是为承载海量数据而设计的一组数据类型。SecureFile 是一种 LOB 存储参数,支持数据去重、加密与压缩。
Streams 池(Streams Pool):供 Oracle Streams、Data Pump 与 GoldenGate 集成捕获/应用进程使用。该池存放缓冲队列消息,并为 Oracle Streams 的捕获与应用进程提供内存。除非显式配置,其初始大小为 0;当使用 Oracle Streams 时,池大小会按需动态增长。
Java 池(Java Pool):供 Java 虚拟机(JVM)中所有会话特定的 Java 代码与数据使用。其使用方式取决于 Oracle 数据库运行的模式。
固定 SGA(Fixed SGA):一种内部维护区域,包含关于数据库与数据库实例状态的通用信息,以及进程间通信的信息。
更多信息,参见《系统全局区(SGA)概述》(Overview of the System Global Area, SGA)。
Shared Pool
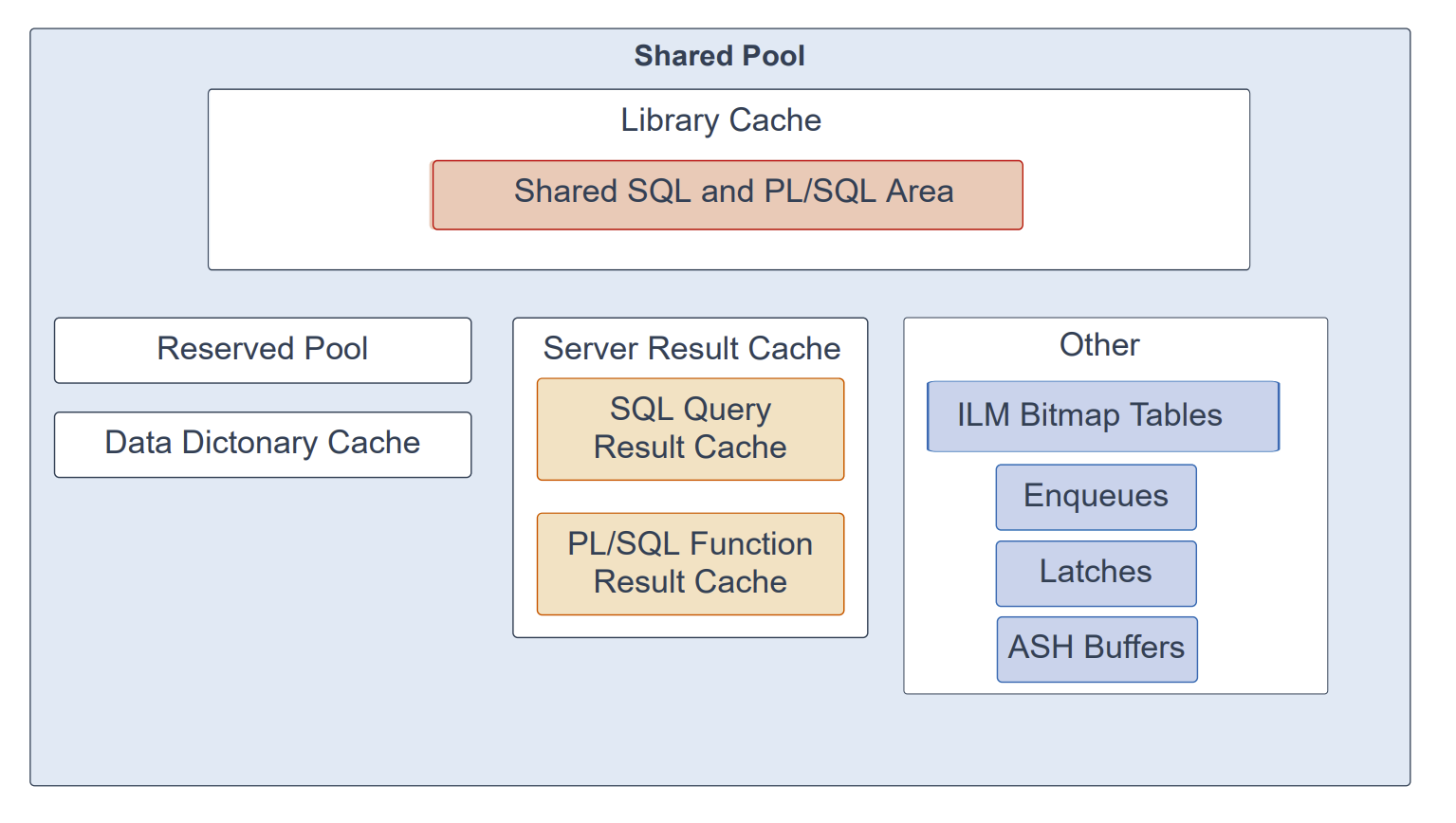
共享池(Shared Pool)是系统全局区(SGA, System Global Area)的组成部分,负责缓存多种类型的程序数据。例如,共享池存放解析后的 SQL、PL/SQL 代码、系统参数以及数据字典信息。共享池几乎参与数据库中发生的每一项操作;例如,当用户执行一条 SQL 语句时,Oracle 数据库会访问共享池。
共享池划分为以下子组件:
库缓存(Library Cache):一种共享池内存结构,用于存储可执行的 SQL 和 PL/SQL 代码。该缓存包含共享的 SQL/PLSQL 区以及控制结构,例如锁(locks)与库缓存句柄(library cache handles)。当执行某条 SQL 语句时,数据库会尝试复用先前已执行过的代码;如果该语句的解析表示已存在且可共享,数据库将复用该代码,此称为软解析(soft parse)或库缓存命中(library cache hit)。否则,数据库需构建新的可执行版本,称为硬解析(hard parse)或库缓存未命中(library cache miss)。
预留池(Reserved Pool):共享池中的一块内存区域,Oracle 数据库可用其分配较大的连续内存块。数据库从共享池以“块”(chunks)的方式分配内存;通过分块,较大的对象(超过 5 KB)无需一块单一的大连续区域即可装入缓存,从而降低因碎片化导致的连续内存不足的可能性。
数据字典缓存(Data Dictionary Cache):存放关于数据库对象的信息(即字典数据)。也称为行缓存(row cache),因为其以“行”的形式保存数据,而非以缓冲区的形式。
服务器结果缓存(Server Result Cache):共享池内的一个内存池,用于保存结果集。其包含 SQL 查询结果缓存 与 PL/SQL 函数结果缓存,二者共享同一基础设施。SQL 查询结果缓存存储查询及查询片段的结果,大多数应用都能因此获得性能提升。PL/SQL 函数结果缓存存储函数的结果集;适合缓存的典型场景是那些频繁被调用且依赖相对静态数据的函数。
其他组件(Other Components):包括排队锁(enqueues)、闩锁(latches)、信息生命周期管理(ILM)位图表、活动会话历史(ASH)缓冲区,以及其他较小的内存结构。
Enqueue:一种共享内存结构(锁),用于串行化对数据库资源的访问,可关联到会话或事务。示例包括:控制文件事务、数据文件、实例恢复、介质恢复、事务恢复、作业队列等。
Latch:一种低层级的串行化控制机制,用于保护 SGA 中的共享数据结构,防止被同时访问。示例包括:行缓存对象、库缓存固定(library cache pin)、日志文件并行写(log file parallel write)。
更多信息,参见共享池(Shared Pool)。
Large Pool
大型池(Large Pool)是一个可选的内存区域,数据库管理员可将其配置为为以下内容提供大块内存分配:
用户全局区(UGA, User Global Area):为共享服务器(shared server)与 Oracle XA 接口(用于事务与多个数据库交互的场景)提供会话内存。
I/O 缓冲区区域(I/O Buffer Area):供 I/O 服务器进程、并行查询操作使用的消息缓冲区、Recovery Manager(RMAN)I/O 从进程的缓冲区,以及高级队列(Advanced Queuing)的内存表存储使用。
延迟插入池(Deferred Inserts Pool):快速摄取(fast ingest)特性,使对定义为
MEMOPTIMIZE FOR WRITE的表进行高频、单行的数据插入成为可能。快速摄取产生的插入也称为“延迟插入(deferred inserts)”。它们最初缓存在大型池中,随后由空间管理协调器(Space Management Coordinator,SMCO)及 Wxxx 从属后台进程以异步方式写入磁盘(触发条件为每个会话、每个对象累计写入达到 1MB,或经过 60 秒)。在 SMCO 后台进程完成清扫(sweep)之前,缓存在该池中的任何数据——即便已提交——对包括写入者在内的任何会话都不可见、不可读。
初始化与大小管理 当向某个“内存优化写(memoptimized for write)”表插入第一行时,会在大型池中初始化该池。若大型池空间充足,将一次性从大型池划拨 2G。如果大型池空间不足,会在内部检测到并自动清除一个 ORA-4031,随后以原请求的一半大小重试分配;若仍不足,将依次以 512M 与 256M 重试。若仍无法分配成功,则在实例重启之前,该特性将被禁用。一旦该池完成初始化,其大小保持静态,不能增长或缩小。
空闲内存与回收策略(Free memory) 大型池不同于共享池(Shared Pool)中的“预留空间(Reserved Space)”——后者与共享池的其它分配共享同一条 LRU(Least Recently Used,最近最少使用)链表;而大型池没有 LRU 列表。在大型池中,内存以“大块”形式分配,在使用完成之前不可释放。
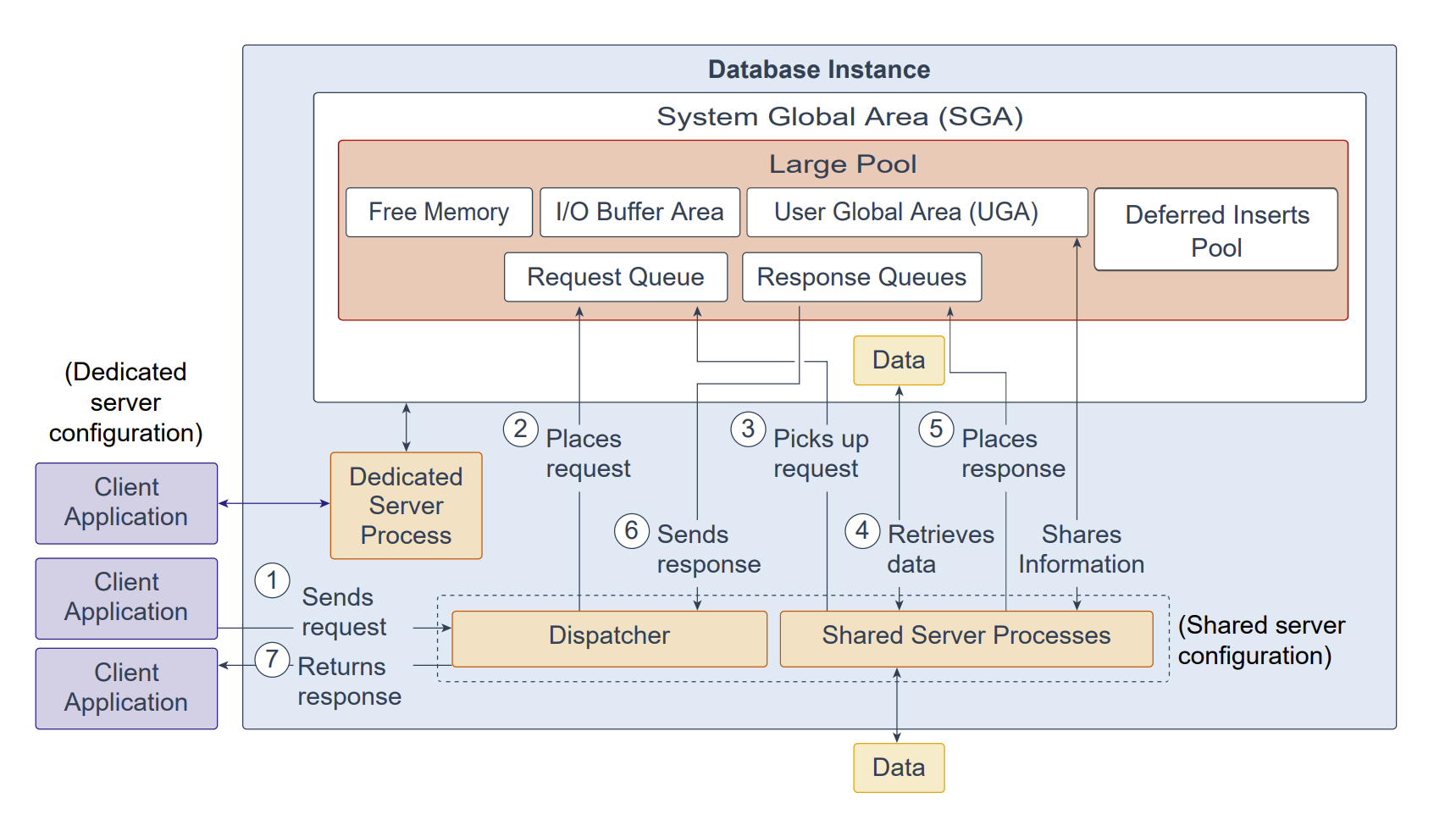
来自用户的“请求”是其 SQL 语句所触发的单次 API 调用。在专用服务器(dedicated server)环境中,一个服务器进程只为一个客户端进程处理请求。每个服务器进程都会消耗系统资源(包括 CPU 周期与内存)。在共享服务器(shared server)环境中,处理流程如下:
客户端应用将请求发送到数据库实例,该请求由分发器(dispatcher)接收。
分发器将请求放入大型池(large pool)中的请求队列(request queue)。
下一可用的共享服务器进程(shared server process)取走请求。共享服务器进程会轮询公共请求队列以获取新请求,并按先进先出(FIFO)的顺序取走请求。一个共享服务器进程一次从队列中取走一个请求。
共享服务器进程发出完成该请求所需的所有数据库调用。首先,它会访问共享池(shared pool)中的库缓存(library cache)以验证所需对象;例如检查表是否存在、用户是否具备相应权限等。随后,进程访问缓冲区缓存(buffer cache)以获取数据;若未命中,则访问磁盘。 不同的数据库调用可以由不同的共享服务器进程处理。因此,请求解析查询、获取第一行、获取下一行以及关闭结果集等操作,可能分别由不同的共享服务器进程完成。 正因为每次数据库调用可能由不同的共享服务器进程处理,用户全局区(UGA, User Global Area)必须位于共享内存区域,因为 UGA 中保存了每个客户端会话的信息。换言之,UGA 含有各会话信息,必须对所有共享服务器进程可见,因为任一共享服务器进程都可能处理任一会话的数据库调用。
请求完成后,共享服务器进程将响应放入调用该请求的分发器在大型池中的响应队列(response queue)。每个分发器都有其独立的响应队列。
响应队列把响应交给分发器。
分发器将已完成的请求返回给相应的客户端应用。
更多信息,参见大型池(Large Pool)。
Database Buffer Cache
数据库缓冲区缓存(Database Buffer Cache,简称 buffer cache)是系统全局区(SGA, System Global Area)中的一块内存区域,用于存放从数据文件读取的数据块副本。缓冲区(buffer)是按数据库块大小划分的一段内存;每个缓冲区都有一个称为数据库缓冲区地址(DBA, Database Buffer Address)的地址。所有并发连接到同一数据库实例的用户都共享对缓冲区缓存的访问。缓冲区缓存的目标是优化物理 I/O:把经常访问的块尽量留在缓存中,而将不常访问的块写回磁盘。
当某个 Oracle 数据库用户进程第一次需要某段数据时,会先到数据库缓冲区缓存中查找该数据:
若在缓存中找到了(缓存命中,cache hit),则可直接从内存读取;
若没找到(缓存未命中,cache miss),则必须先把数据块从磁盘上的数据文件拷贝到缓存中的某个缓冲区,再进行访问。 显然,经由缓存命中访问数据比缓存未命中更快。
缓存中的缓冲区由一个**结合“最近最少使用(LRU)链表”和触碰计数(touch count)**的复杂算法管理。LRU 机制有助于让最近使用过的块留在内存中,从而尽量减少磁盘访问。
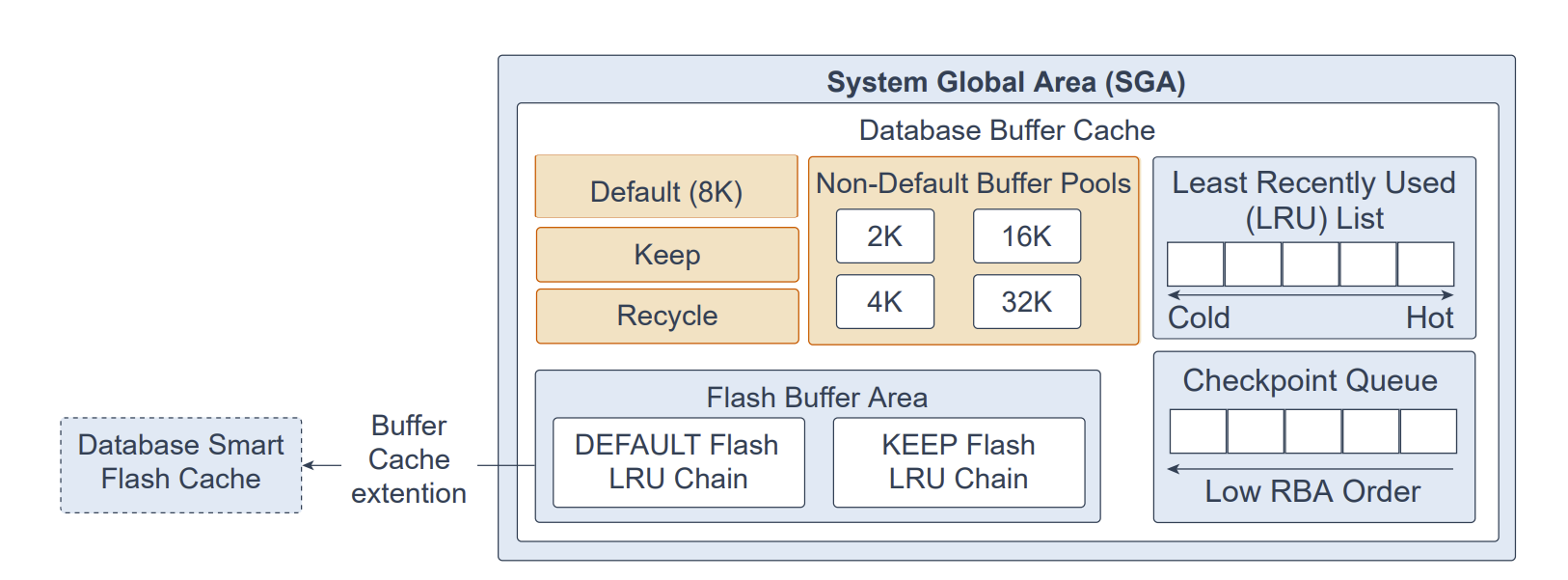
数据库缓冲区缓存由以下部分构成:
默认池(Default pool):块通常在此缓存。默认块大小为 8 KB。除非你手动配置了独立的其他池,否则默认池就是唯一的缓冲池。是否配置其他可选池,对默认池本身没有影响。
保留池(Keep pool):供那些访问频繁、但因空间不足而从默认池“老化”淘汰的块使用。其目的在于将指定对象尽量留驻内存,从而避免 I/O。
回收池(Recycle pool):供不常使用的块使用。回收池可防止指定对象在缓存中占用不必要的空间。
非默认缓冲池(Non-default buffer pools):供使用非常规块大小(2 KB、4 KB、16 KB、32 KB)的表空间使用。每种非常规块大小都有其独立的缓冲池。Oracle 数据库对这些池中的块的管理方式与默认池相同。
数据库智能闪存缓存(Database Smart Flash Cache,简称 flash cache):允许使用闪存设备在不增加主内存的情况下扩大缓冲区缓存的有效容量。通过把数据库中经常访问的数据缓存在闪存中,而不是每次都从磁盘读取,可提升数据库性能。数据库请求数据时,系统先查找数据库缓冲区缓存;若未命中,再查找 Flash Cache;若仍未命中,才访问磁盘。在 Oracle RAC 环境中,必须在全部实例或全部不启用上统一配置 Flash Cache。
最近最少使用链表(Least Recently Used list,LRU):保存指向脏缓冲区与干净缓冲区的指针。LRU 链表分为热端(hot end)与冷端(cold end):冷缓冲区是近期未被使用的缓冲区;热缓冲区是访问频繁且最近使用过的缓冲区。概念上只有一条 LRU,但为支持数据并发,数据库实际上会使用多条 LRU。
检查点队列(Checkpoint queue)
闪存缓冲区区域(Flash Buffer Area):由 DEFAULT Flash LRU 链与 KEEP Flash LRU 链组成。
在未启用 Database Smart Flash Cache 的情况下,当进程访问某块而该块不在缓冲区缓存中时,会触发从磁盘读入内存(物理读)。当内存中的缓冲区缓存已满时,会基于 LRU 机制逐出缓冲区。
启用 Database Smart Flash Cache 后,当一个干净的内存缓冲区被老化逐出时,数据库写进程(DBWn)会在后台把缓冲区内容写入 Flash Cache;同时,缓冲区头(buffer header)作为元数据保留在内存中,并根据对象属性 FLASH_CACHE 的取值,分别挂到 DEFAULT 或 KEEP 的 Flash LRU 链上。
KEEP Flash LRU 链用于将这些缓冲头维护在单独的链表上,避免被常规缓冲头替换;因此,指定为 KEEP 的对象,其对应的闪存缓冲头通常在 Flash Cache 中驻留更久。
若对象属性 FLASH_CACHE = NONE,系统不会在 Flash Cache 或内存中保留相应的缓冲区。
当某个已经从内存老化出去的缓冲区再次被访问时,系统会先检查 Flash Cache;若命中,则从 Flash Cache 读回(其耗时仅为磁盘读取的一小部分)。
在 RAC 环境中,Flash Cache 缓冲区的一致性与 Cache Fusion 的方式相同得到保证。
由于 Flash Cache 是扩展缓存,而直通路径 I/O(direct path I/O)会完全绕过缓冲区缓存,因此该特性不支持直通路径 I/O。
注意:系统不会把脏缓冲区写入 Flash Cache,因为执行检查点(checkpoint)时可能还需要把这些缓冲区读回内存;并且写入 Flash Cache 并不计入检查点。
更多信息,参见数据库缓冲区缓存(Database Buffer Cache)。
In-Memory Area
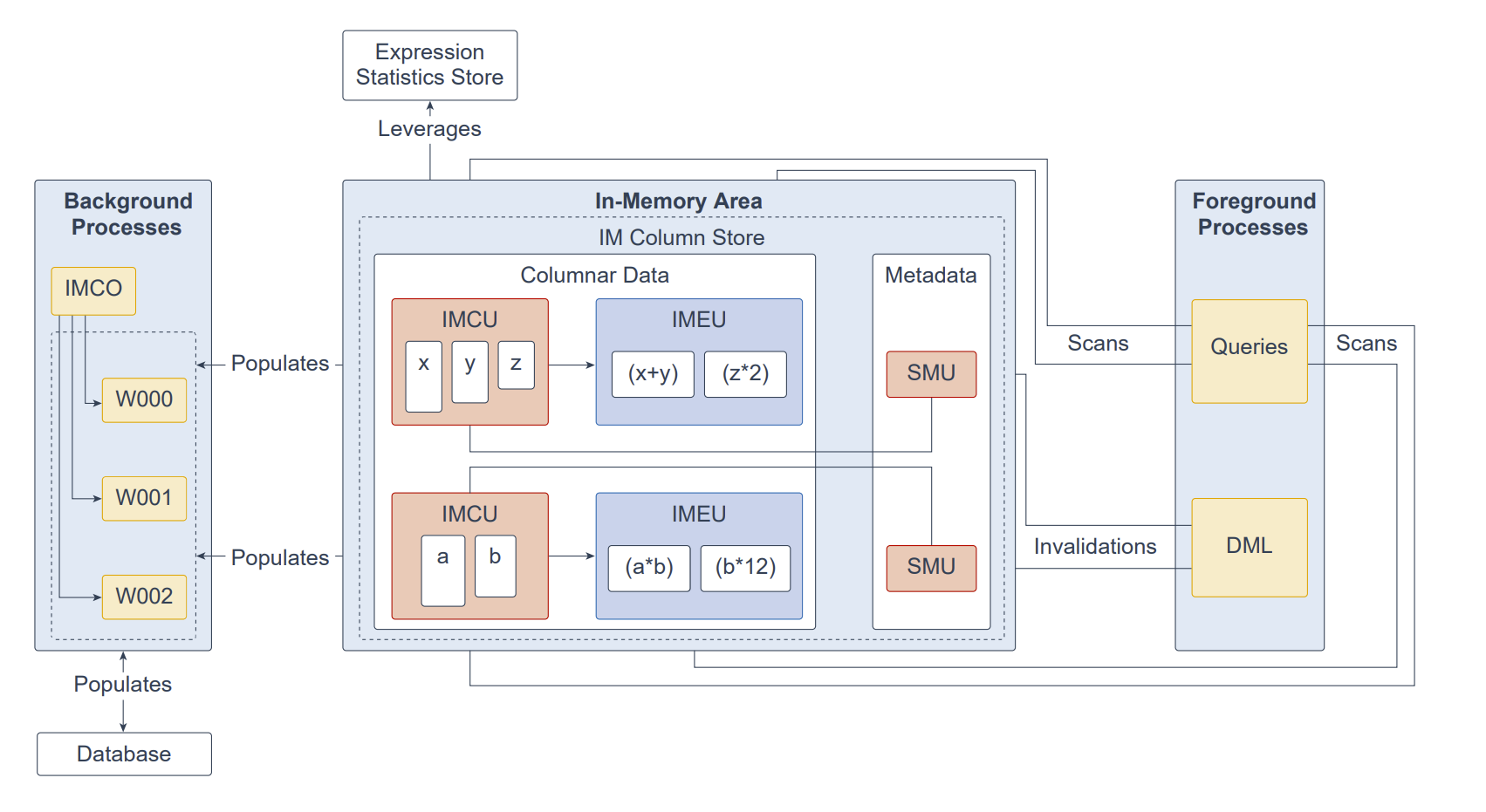
内存区域(In-Memory Area)是一个可选的 SGA 组件,其中包含内存列存(IM column store),该列存以列式格式将表与分区保存在内存中,以优化快速扫描。IM 列存使数据可以同时以两种格式驻留在 SGA 中:传统的行式格式(位于缓冲区缓存)与列式格式。数据库会透明地将联机事务处理(OLTP)查询(如主键查找)发送到缓冲区缓存,而将分析与报表类查询发送到 IM 列存。在取数时,Oracle 数据库也可以在同一条查询中同时从这两块内存区域读取数据。该双格式架构并不会使内存需求翻倍;缓冲区缓存经过优化,可在容量远小于数据库整体大小的情况下运行。
你应仅将对性能最关键的数据填充到 IM 列存中。要把对象加入 IM 列存,可在创建或修改对象时开启 INMEMORY 属性。该属性可设置在表空间(适用于该表空间中新建的所有表与视图)、表、(子)分区、物化视图,或对象内的列子集上。
IM 列存对数据与元数据采用优化后的存储单元进行管理,而非传统的 Oracle 数据块:
内存压缩单元(IMCU, In-Memory Compression Unit):只读、压缩的存储单元,包含一个或多个列的数据。
快照元数据单元(SMU, Snapshot Metadata Unit):保存与某个 IMCU 关联的元数据与事务信息。每个 IMCU 都映射到一个独立的 SMU。
表达式统计存储(ESS, Expression Statistics Store)是一个用于保存表达式求值统计信息的仓库,位于 SGA 中,同时也持久化到磁盘。启用 IM 列存后,数据库会利用 ESS 支持内存表达式(IM expressions)特性。内存表达式单元(IMEU, In-Memory Expression Unit)是用于存放物化 IM 表达式与用户定义虚拟列的存储容器。请注意,ESS 独立于 IM 列存;它是数据库的永久组件,不可禁用。
从概念上讲,IMEU 是其父 IMCU 的逻辑扩展。就像一个 IMCU 可以包含多列一样,一个 IMEU 可以包含多个虚拟列。每个 IMEU 与且仅与一个 IMCU 一一对应,并映射到相同的行集。IMEU 中保存的是其关联 IMCU 所含数据的表达式结果;当 IMCU 被填充时,关联的 IMEU 也会被填充。
一个典型的 IM 表达式涉及一个或多个列(可能包含常量),并与表中的行一一对应。例如,EMPLOYEES 表的某个 IMCU 在列 weekly_salary 上包含第 1–1000 行;对于该 IMCU 中的这些行,IMEU 会计算自动检测到的 IM 表达式 weekly_salary*52,以及用户定义的虚拟列 quarterly_salary(定义为 weekly_salary*12)。IMCU 中自上而下的第 3 行对应 IMEU 中自上而下的第 3 行。
In-Memory Area 被细分为两个池:
1MB 列式数据池:用于存放实际填充入内存的列式数据(IMCU 与 IMEU)。
64K 元数据池:用于存放填充进 IM 列存的对象的元数据。 两者的相对大小由内部启发式算法决定;In-Memory Area 的大部分内存会分配给1MB 池。该区域的大小由初始化参数
INMEMORY_SIZE控制(默认 0),且最小值为 100MB。自 Oracle Database 12.2 起,你可以通过ALTER SYSTEM命令在线增大 In-Memory Area 的大小(每次至少增加 128MB);注意无法在线收缩该区域的大小。
对于内存表,在首次访问表数据或数据库启动时,会在 IM 列存中为其分配 IMCU。系统通过将磁盘上的行式数据转换为新的内存列式格式来制作该表的内存副本。由于 IM 列存副本仅存在于内存中,因此每次实例重启时都会再次进行该转换。在转换期间,表的内存版本会逐步可供查询使用;即使仅部分完成转换,查询也可以部分利用内存版本,其余部分仍从磁盘读取,而无需等待整个表转换完毕。
在响应查询与 DML 时,服务器进程会扫描列式数据并更新 SMU 元数据;后台进程负责将行式数据从磁盘填充到 IM 列存。In-Memory 协调进程(IMCO, In-Memory Coordinator Process)会发起列式数据的后台填充与重填充;空间管理协调器(SMCO, Space Management Coordinator Process)与空间管理工作进程(Wnnn)代表 IMCO 执行实际的填充/重填充操作。DML 所导致的数据块变更会先写入缓冲区缓存,再落盘;随后后台进程依据元数据失效与查询请求,将行式数据从磁盘重填充到 IM 列存。
你可以启用 In-Memory FastStart 功能,把 IM 列存中的列式数据以压缩列式格式写回数据库中的某个表空间,从而加快数据库启动速度。需要注意的是,该功能不适用于 IMEU;IMEU 始终由 IMCU 动态填充。
更多信息,参见《Oracle Database In-Memory 简介》(Introduction to Oracle Database In-Memory)。
Program Global Area
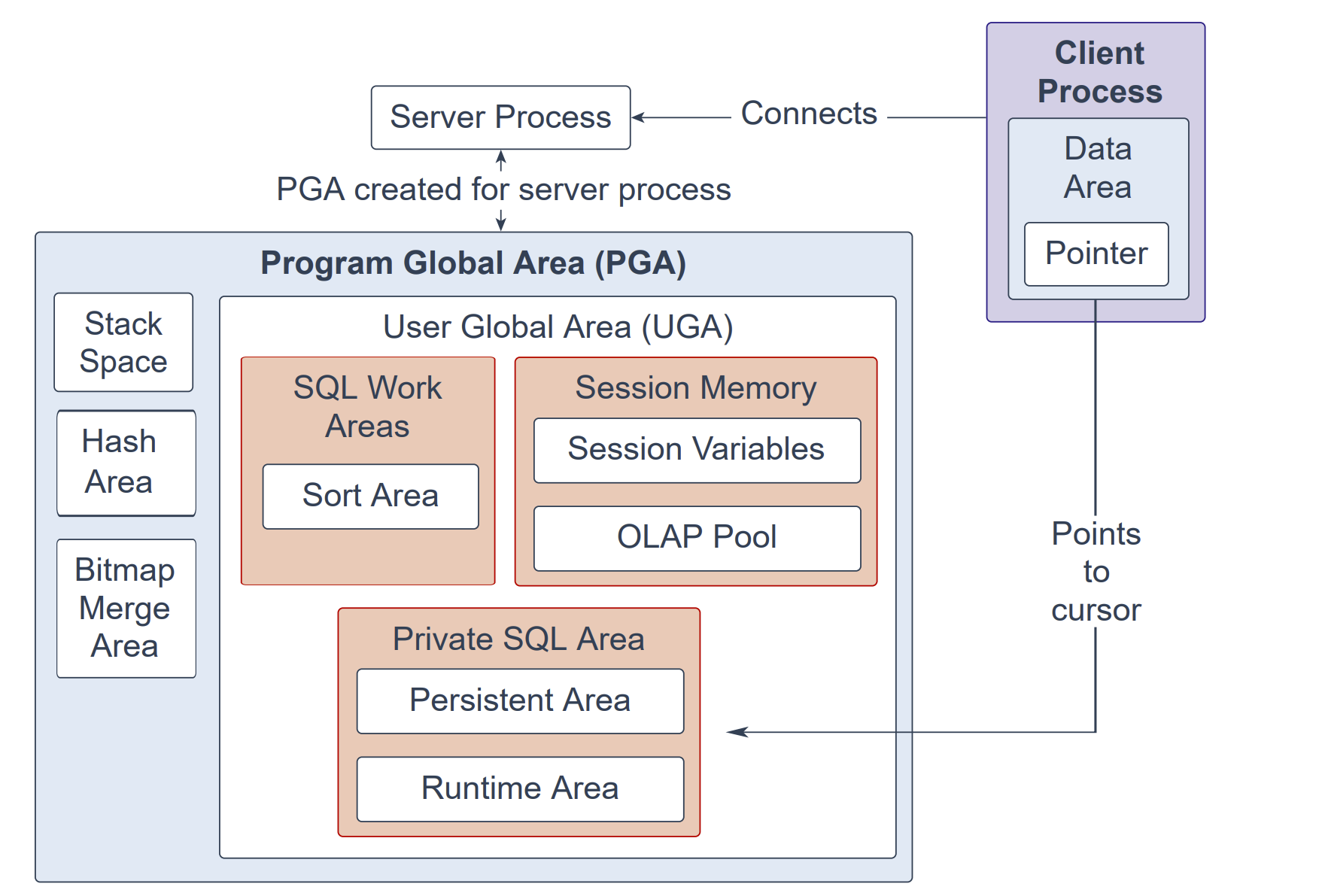
程序全局区(PGA,Program Global Area)是非共享的内存区域,包含仅供服务器进程与后台进程使用的数据与控制信息。Oracle 数据库会创建服务器进程,代表客户端程序与数据库建立连接。在专用服务器(dedicated server)环境中,每启动一个服务器进程或后台进程,都会创建一个对应的 PGA。每个 PGA 由栈空间(stack space)、哈希区(hash area)、位图合并区(bitmap merge area)以及用户全局区(UGA,User Global Area)组成。与其关联的服务器进程或后台进程终止时,该 PGA 会被释放。
在共享服务器(shared server)环境中,多个客户端用户共享同一个服务器进程。此时 UGA 会被移入大型池(large pool),PGA 仅保留栈空间、哈希区与位图合并区。
在专用服务器会话中,PGA 包含以下组件:
SQL 工作区(SQL work areas):其中的排序区(sort area)供诸如
ORDER BY、GROUP BY等对数据进行排序的操作使用。会话内存(Session memory):为会话变量(如登录信息)及会话所需的其他信息分配的用户会话数据存储区。OLAP 池(OLAP pool)用于管理 OLAP 数据页(等同于数据块)。
私有 SQL 区(Private SQL area):保存已解析 SQL 语句的信息及处理所需的其他会话特定信息。当服务器进程执行 SQL 或 PL/SQL 代码时,会使用私有 SQL 区来存放绑定变量(bind variables)值、查询执行状态信息以及查询执行工作区。同一会话或不同会话中的多个私有 SQL 区可以指向 SGA 中的同一个执行计划。持久区(persistent area)保存绑定变量值;运行时区(run-time area)保存查询执行状态信息。游标(cursor)是指向私有 SQL 区某一特定区域的名称或句柄:在客户端可视为一个指针,在服务器端可视为一种状态。由于游标与私有 SQL 区紧密相关,这两个术语有时可互换使用。
此外:
栈空间(Stack space):用于保存会话变量与数组的内存。
哈希区(Hash area):用于执行表之间的哈希连接(hash join)。
位图合并区(Bitmap merge area):用于合并从多个位图索引扫描得到的数据。
更多信息,参见《程序全局区(PGA)概述》(Overview of the Program Global Area, PGA)。
Background Processes
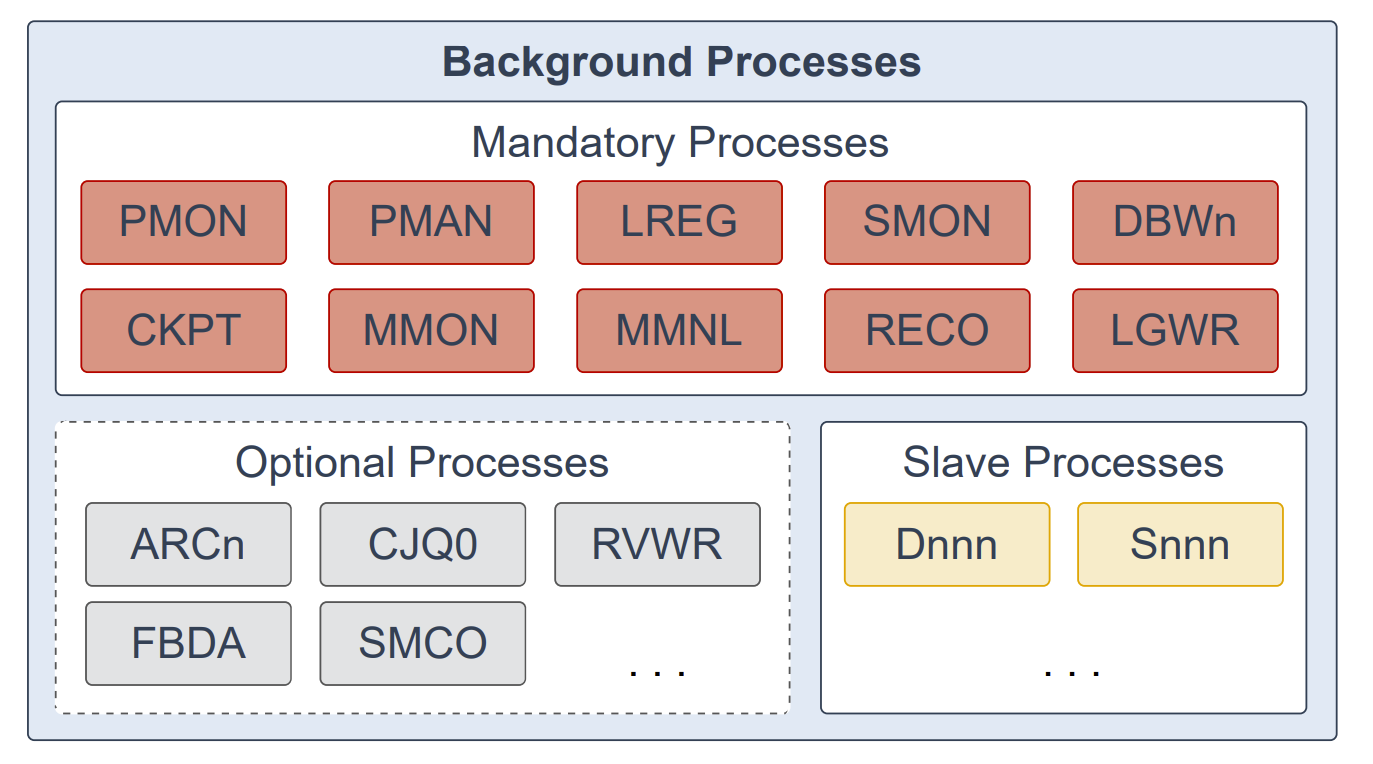
后台进程(background processes)是数据库实例的一部分,用于执行运行数据库所需的维护任务,并在多用户环境下最大化性能。每个后台进程各司其职,但彼此协同工作。启动数据库实例时,Oracle 数据库会自动创建后台进程。实例中存在的后台进程取决于数据库所启用的功能。当你启动数据库实例时,必需的后台进程会自动启动;根据需要,你也可以在之后启动可选的后台进程。
必需后台进程在所有典型的数据库配置中都存在。在使用最小化初始化参数文件启动的读/写数据库实例中,这些进程默认运行;读仅数据库实例会禁用其中的一些进程。必需后台进程包括:进程监视进程(Process Monitor Process,PMON)、进程管理器进程(Process Manager Process,PMAN)、监听器注册进程(Listener Registration Process,LREG)、系统监视进程(System Monitor Process,SMON)、数据库写进程(Database Writer Process,DBWn)、检查点进程(Checkpoint Process,CKPT)、可管理性监视进程(Manageability Monitor Process,MMON)、轻量可管理性监视进程(Manageability Monitor Lite Process,MMNL)、恢复进程(Recoverer Process,RECO)以及日志写入进程(Log Writer Process,LGWR)。
大多数可选后台进程与特定任务或功能相关。常见的可选进程包括:归档进程(Archiver Processes,ARCn)、作业队列协调器进程(Job Queue Coordinator Process,CJQ0)、恢复写入进程(Recovery Writer Process,RVWR)、闪回数据归档进程(Flashback Data Archive Process,FBDA)以及空间管理协调器进程(Space Management Coordinator Process,SMCO)。
从属进程(slave processes)是替其他进程执行工作的后台进程;例如,分发器进程(Dispatcher Process,Dnnn)与共享服务器进程(Shared Server Process,Snnn)。
完整的后台进程列表,参见后台进程(Background Processes)。
Process Monitor Process (PMON)
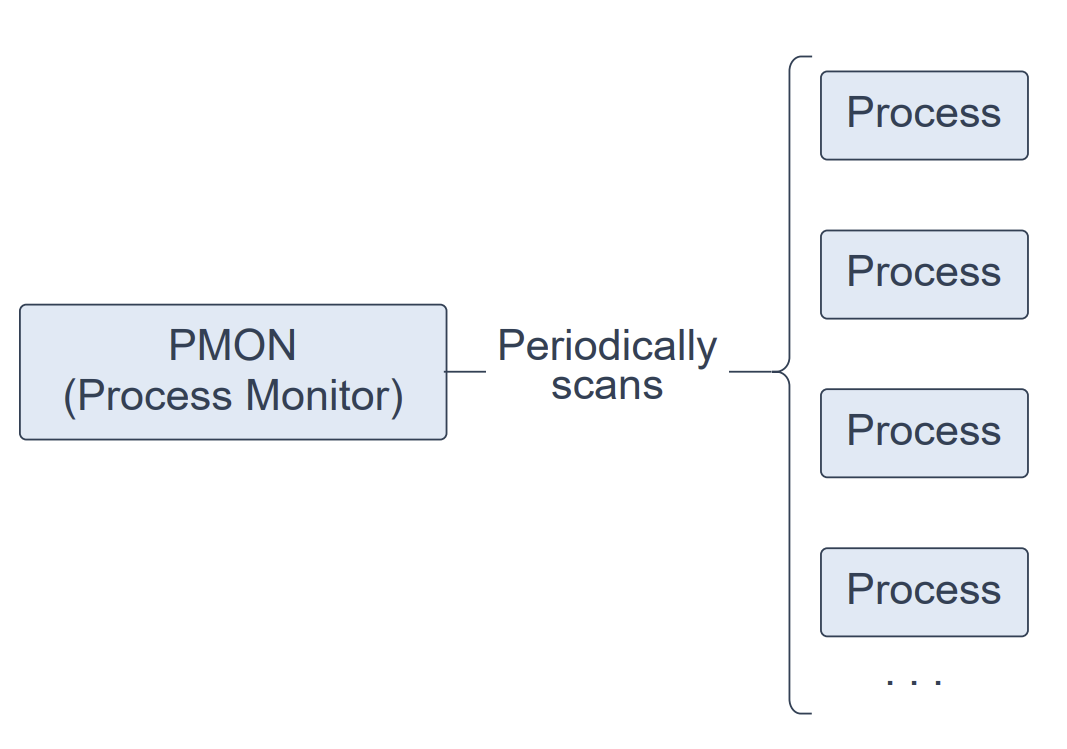
进程监视进程(Process Monitor Process,PMON)是一个后台进程,负责定期扫描所有进程,以发现任何异常终止的进程。随后,PMON 负责协调清理工作,该清理由清理主进程(Cleanup Main Process,CLMN)与清理从属进程(Cleanup Slave Process,CLnn)执行。
PMON 以操作系统进程(而非线程)的形式运行。除数据库实例外,PMON 也运行于 Oracle 自动存储管理(ASM)实例以及 Oracle ASM Proxy 实例之上。
完整的后台进程列表,参见 Background Processes(后台进程)。
Process Manager Process (PMAN)
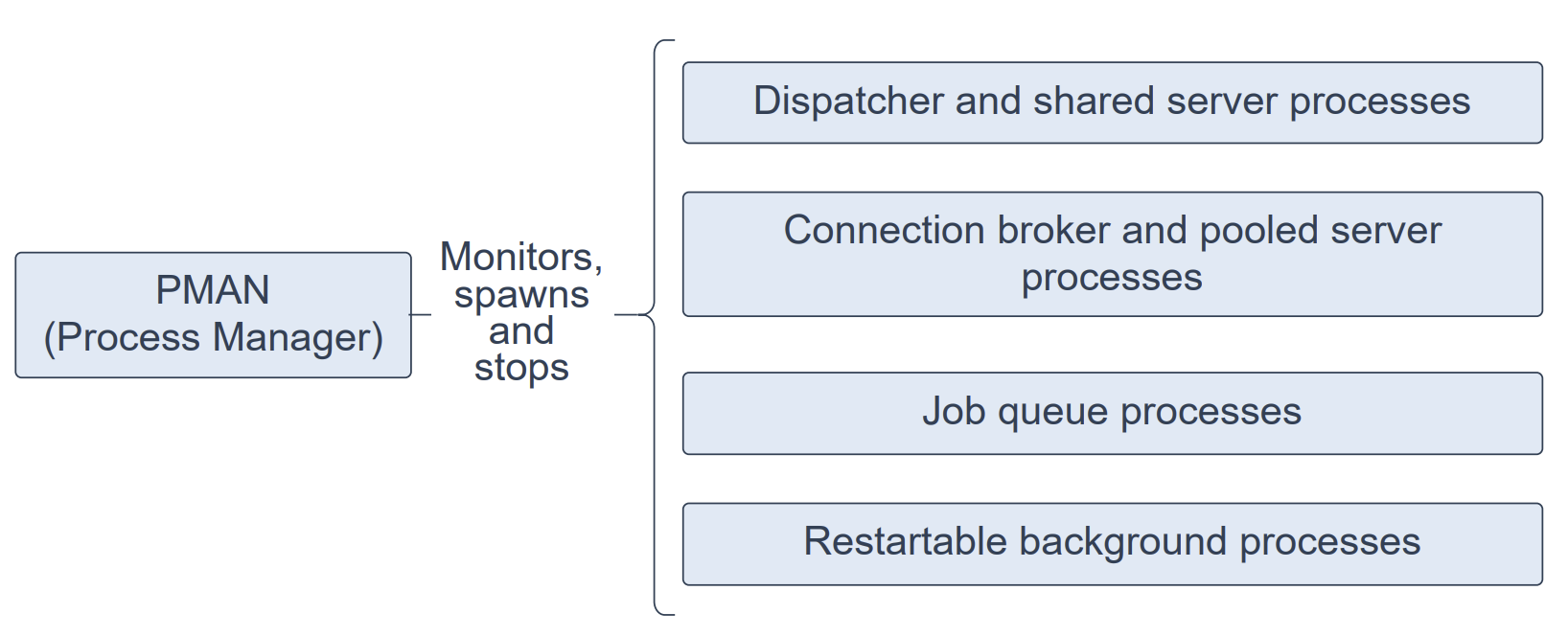
进程管理器进程(Process Manager Process,PMAN)是一个后台进程,用于按需监控、派生(spawn)并停止以下组件:
分发器进程与共享服务器进程(Dispatcher and Shared Server Processes)
数据库驻留连接池的连接代理与池化服务器进程(Connection Broker and Pooled Server Processes for Database Resident Connection Pools)
作业队列进程(Job Queue Processes)
可重启的后台进程(Restartable Background Processes)
PMAN 以操作系统进程(而非线程)的形式运行。除数据库实例外,PMAN 也运行于 Oracle 自动存储管理(ASM)实例以及 Oracle ASM Proxy 实例。
完整的后台进程列表,参见 Background Processes(后台进程)。
Listener Registration Process (LREG)
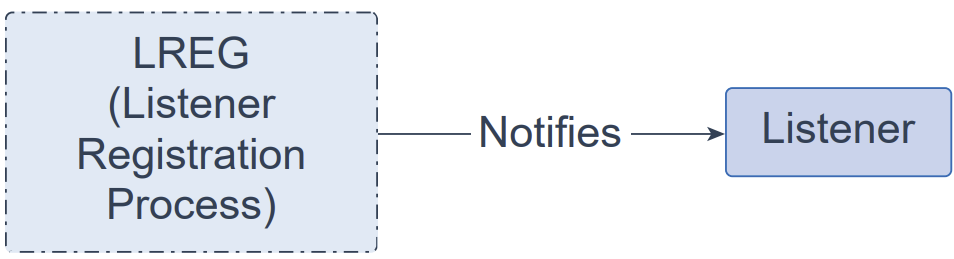
监听器注册进程(Listener Registration Process,LREG)是一个后台进程,用于将实例、服务、处理程序(handlers)以及端点(endpoints)信息通告给监听器。
LREG 可以以线程或操作系统进程的形式运行。除数据库实例外,LREG 也运行在 Oracle 自动存储管理(ASM)实例以及 Oracle Real Application Clusters(RAC) 上。
完整的后台进程列表,参见 Background Processes(后台进程)。
System Monitor Process (SMON)
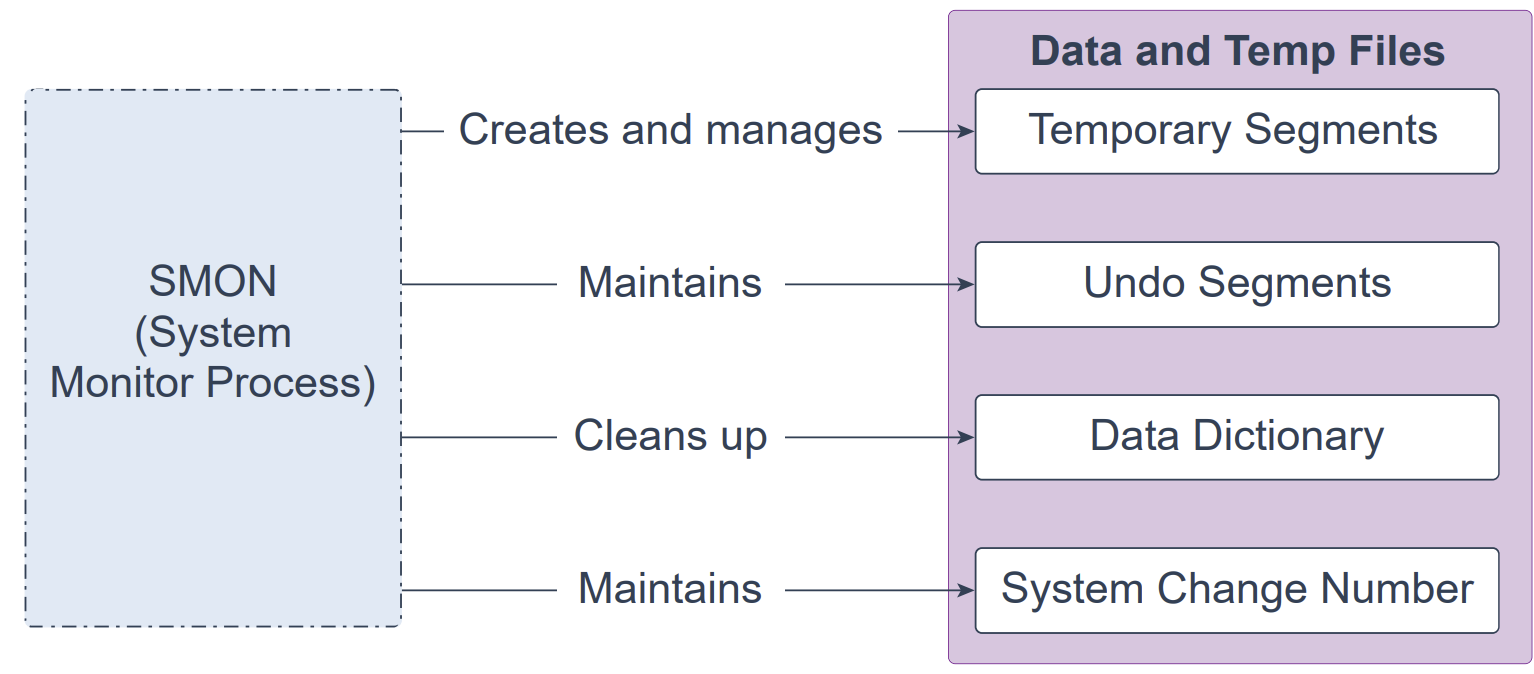
系统监视进程(System Monitor Process,SMON)是一个后台进程,负责执行多项数据库维护任务,包括:
创建并管理临时表空间的元数据,回收孤立的临时段所占空间。
维护撤销表空间:根据撤销空间使用统计,对撤销段进行联机(online)/脱机(offline)/收缩(shrink)。
当数据字典处于瞬态且不一致的状态时,执行清理(cleanup)。
维护用于支持 Oracle 闪回特性的系统改变号到时间(SCN,System Change Number)映射表。
SMON 对在后台活动期间引发的内部与外部错误具有良好的鲁棒性/容错性。SMON 可以以线程或操作系统进程形式运行。在 Oracle Real Application Clusters(RAC) 数据库中,一个实例的 SMON 进程可以为发生故障的其他实例执行实例恢复。
完整的后台进程列表,参见 Background Processes(后台进程)。
Database Writer Process (DBWn)
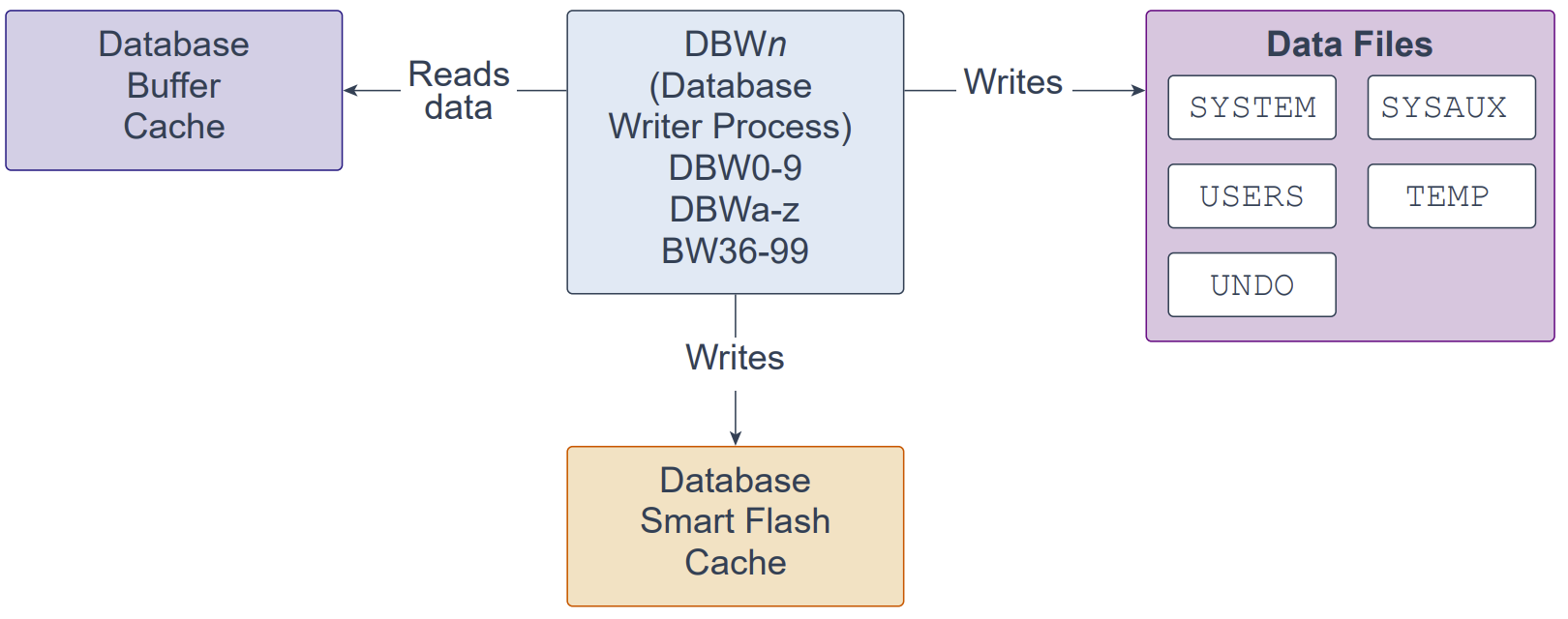
数据库写进程(Database Writer Process,DBWn)是一个后台进程,主要负责将数据块写入磁盘。它还处理检查点(checkpoint)、文件打开同步以及Block Written 记录的日志记录。若已配置数据库智能闪存缓存(Database Smart Flash Cache,Flash Cache),DBWn 也会向 Flash Cache 写入数据。
在许多情况下,DBWn 需要写入的块在磁盘上是分散的;因此,与日志写入进程(Log Writer Process,LGWR)执行的顺序写相比,这类写入往往更慢。为提高效率,DBWn 会在可能时执行多块写入(multi-block writes);一次多块写入所包含的块数因操作系统而异。
初始化参数 DB_WRITER_PROCESSES 用于指定数据库写进程的数量,可设置为 1 到 100。前 36 个数据库写进程的名称为 DBW0–DBW9 与 DBWa–DBWz;第 37 到第 100 个的名称为 BW36–BW99。数据库会根据 CPU 数量与处理器组为 DB_WRITER_PROCESSES 选择合适的默认值,或对用户指定的设置进行调整。
完整的后台进程列表,参见 Background Processes(后台进程)。
Checkpoint Process (CKPT)
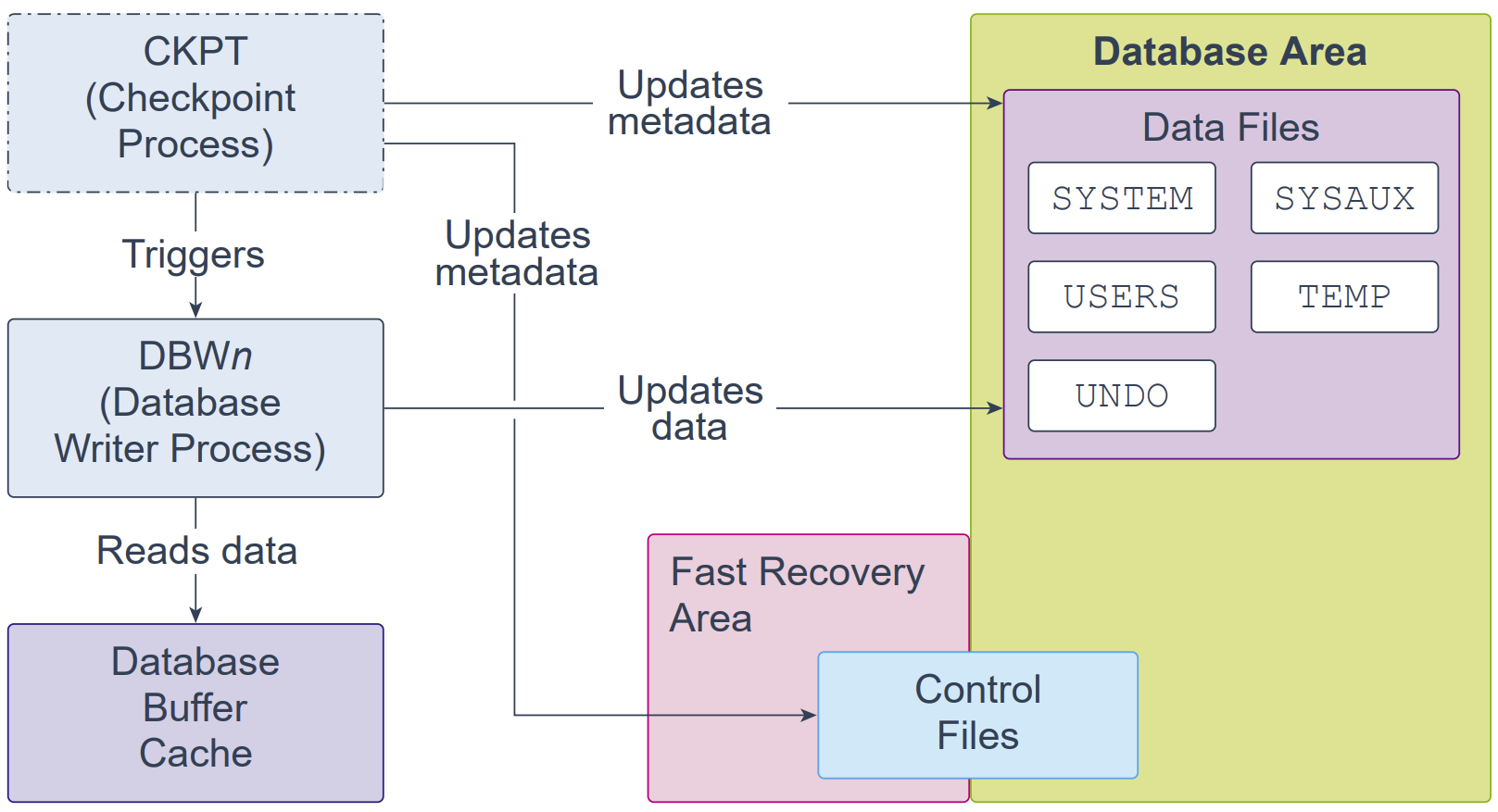
检查点进程(Checkpoint Process,CKPT)是一个后台进程,会在特定时刻通过向数据库写进程(DBWn)发送消息来发起检查点请求,以开始写出脏缓冲区(dirty buffers)。当各个检查点请求完成后,CKPT 会更新数据文件头与控制文件,以记录最近一次检查点。
CKPT 每隔 3 秒检查一次内存使用量是否超过初始化参数 PGA_AGGREGATE_LIMIT 的取值;若超限,则采取相应措施。
CKPT 可以以线程或操作系统进程形式运行。除数据库实例外,CKPT 也运行于 Oracle 自动存储管理(ASM)实例。
完整的后台进程列表,参见 Background Processes(后台进程)。
Recoverer Process (RECO)

恢复进程(Recoverer Process,RECO)是一个后台进程,用于在分布式数据库中因网络或系统故障而处于未决状态的分布式事务进行解析与处理。
RECO 可以作为线程或操作系统进程运行。
完整的后台进程列表,参见 Background Processes(后台进程)。
Log Writer Process (LGWR)
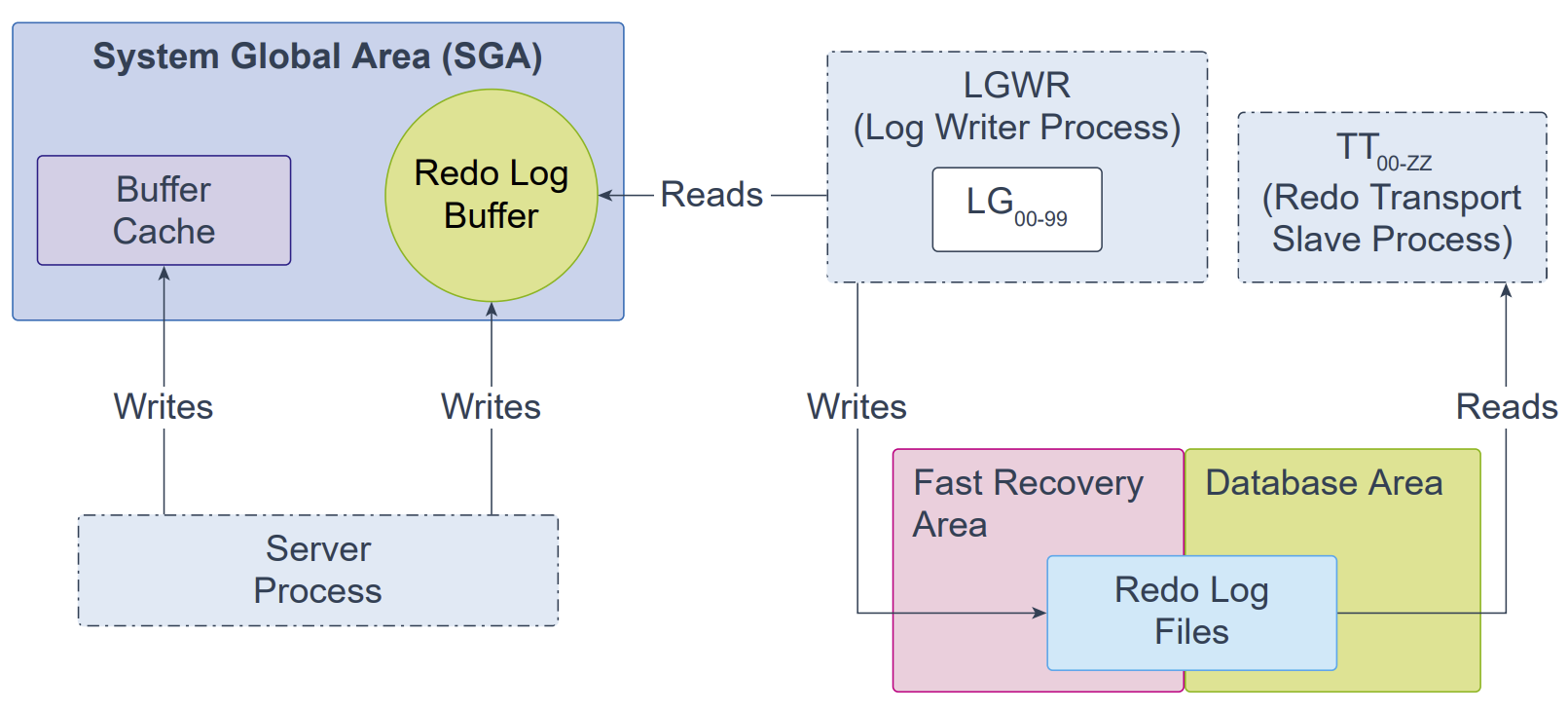
日志写入进程(Log Writer Process,LGWR)是一个后台进程,按顺序把重做日志条目写入重做日志文件。重做日志条目在系统全局区(SGA)的重做日志缓冲区中产生。若数据库配置了多路复用重做日志(multiplexed redo log),LGWR 会将相同的重做条目写入该重做日志文件组的所有成员。
LGWR 处理那些非常迅速或必须协同完成的操作,并将可从并发中获益的操作委派给日志写入工作辅助进程(Log Writer Worker helper processes,LGnn),主要包括:把日志缓冲区中的重做写入重做日志文件,以及在写入完成后通知正在等待的前台进程。
重做传输从属进程(Redo Transport Slave Process,TT00–zz)会把当前联机与备用重做日志中的重做以异步(ASYNC)方式传送到远程的备用目标。
LGWR 可以作为线程或操作系统进程运行。除数据库实例外,LGWR 也运行在 Oracle ASM 实例上。在 Oracle Real Application Clusters(RAC) 架构中,每个数据库实例都有自己的一组重做日志文件。
完整的后台进程列表,参见 Background Processes(后台进程)。
Archiver Process (ARCn)
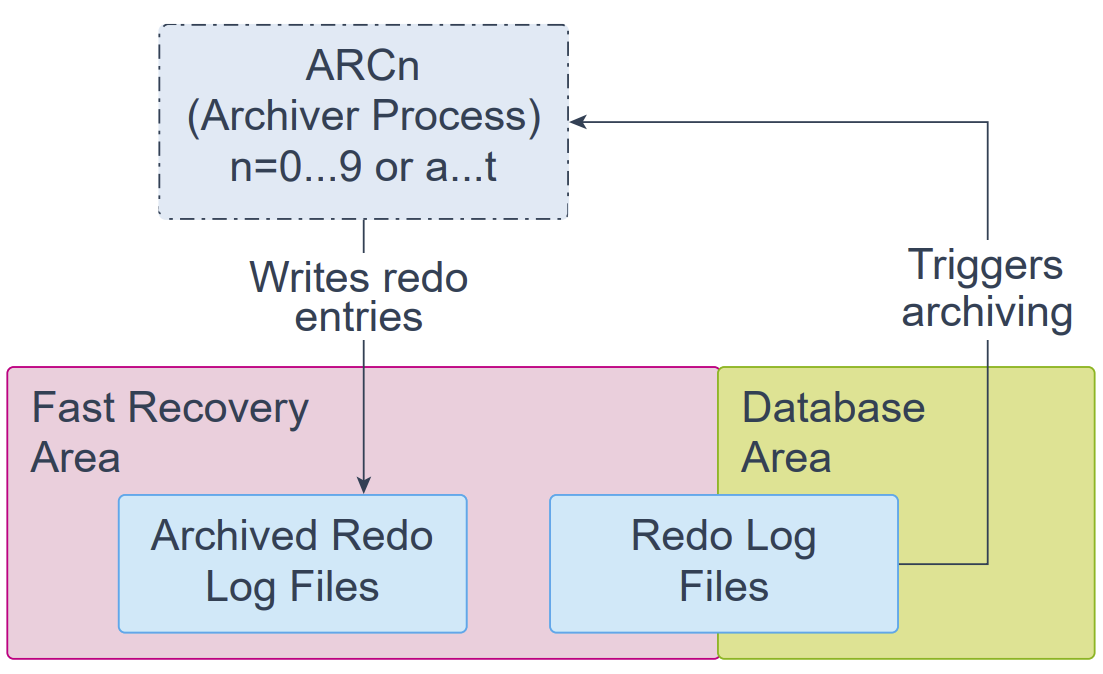
归档进程(Archiver Processes,ARCn)是后台进程,仅当数据库处于 ARCHIVELOG 模式并且启用了自动归档时才存在;在这种情况下,ARCn 会自动归档联机重做日志文件(online redo log files)。在某个联机重做日志组被归档之前,日志写入进程(LGWR)不能重用并覆盖该日志组。
数据库会视需要启动多个归档进程,以确保已写满的联机重做日志的归档工作不会滞后。可能的进程名包括 ARC0–ARC9 与 ARCa–ARCt(最多 31 个目的地)。
初始化参数 LOG_ARCHIVE_MAX_PROCESSES 指定数据库初始启动的 ARCn 进程数量。如果预计归档负载较大(例如进行批量数据装载时),可以增大归档进程的最大数量。归档日志也可以配置为多个目的地,并建议每个目的地至少配置一个归档进程。
ARCn 可以作为线程或操作系统进程运行。
完整的后台进程列表,参见 Background Processes(后台进程)。
Job Queue Coordinator Process (CJQ0)
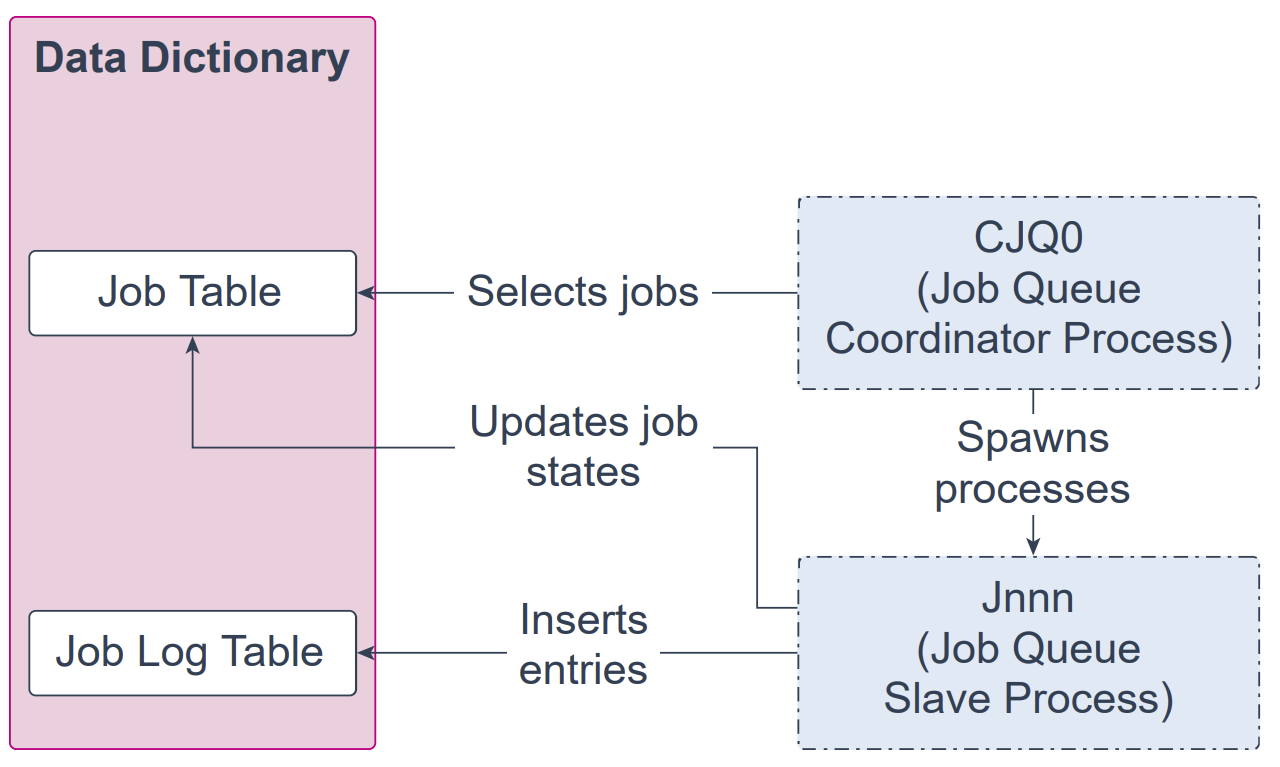
作业队列协调器进程(Job Queue Coordinator Process,CJQ0)是一个后台进程,它从数据字典中选取需要运行的作业,并派生作业队列从进程(Job Queue Slave Processes,Jnnn)来执行这些作业。CJQ0 会由 Oracle Scheduler 按需自动启动与停止。初始化参数 JOB_QUEUE_PROCESSES 指定可用于执行作业的最大进程数。CJQ0 仅会依据待运行作业的数量与可用资源启动所需数量的作业队列进程。
作业队列从进程(Jnnn)执行由协调器分配的作业。当某个作业被选中处理时,从进程会执行以下步骤:
收集运行该作业所需的全部元数据(例如程序参数与权限信息)。
以作业所有者身份启动一个数据库会话,开始一个事务,然后开始执行作业。
作业完成后,提交并结束事务。
关闭会话。
当作业完成后,从进程还会执行以下收尾工作:
如有需要,重新调度该作业;
更新作业表中的状态,以反映作业已完成或已计划再次运行;
向作业日志表插入一条记录;
更新运行次数,并在必要时更新失败次数与重试次数;
进行清理;
寻找新的待办作业(若无可做,则进入休眠)。
CJQ0 与 Jnnn 均可作为线程或操作系统进程运行。
完整的后台进程列表,参见Background Processes(后台进程)。
Recovery Writer Process (RVWR)

恢复写入进程(Recovery Writer Process,RVWR)是一个后台进程,用于对整个数据库执行闪回:在具备所需**闪回日志(flashback logs)**的前提下,它会将数据库从当前状态回退到过去的某个时间点(撤销相应事务)。
当启用闪回数据库(Flashback Database)或设置了保证还原点(guaranteed restore points)时,RVWR 会将闪回数据写入快速恢复区(Fast Recovery Area,FRA)中的闪回数据库日志(Flashback Database logs)。
RVWR 可以作为线程或操作系统进程运行。 完整的后台进程列表,参见 Background Processes(后台进程)。
Database Data Files
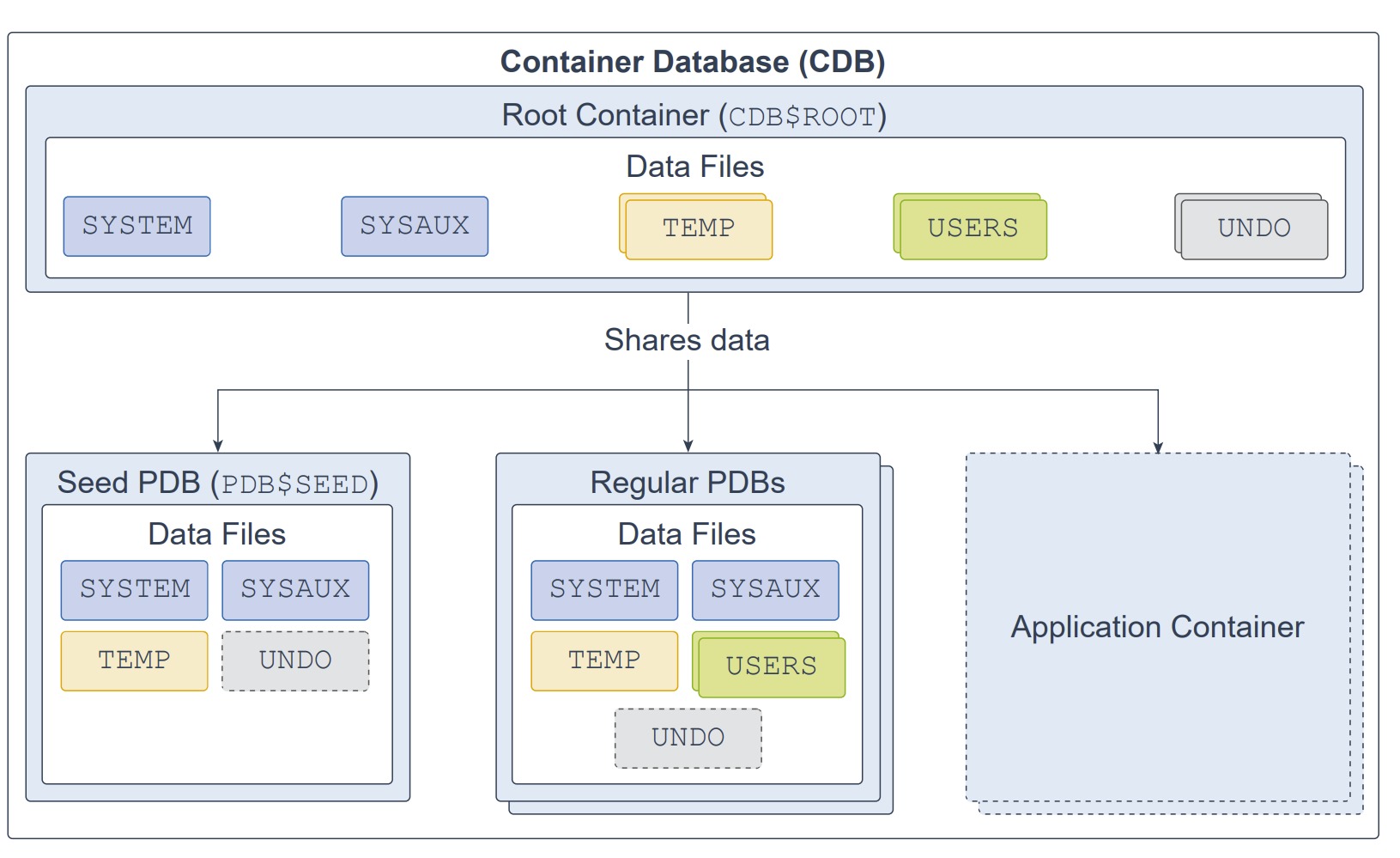
数据库(database)是一组用于存放用户数据与元数据(metadata)的物理文件。元数据由关于数据库服务器的结构、配置与控制信息构成。你可以将数据库设计为多租户容器数据库(CDB,Container Database)或非容器数据库(non-CDB)。
一个 CDB 由以下部分组成:一个 CDB 根容器(root,也称 the root)、且仅一个种子可插拔数据库(seed PDB)、零个或多个用户创建的可插拔数据库(PDB,Pluggable Database),以及零个或多个应用容器(application containers)。整个 CDB 被称为系统容器(system container)。对于用户或应用而言,PDB 在逻辑上表现为相互独立的数据库。
名为 CDB$ROOT 的根容器包含多个数据文件(data files)、控制文件(control files)、重做日志文件(redo log files)、闪回日志(flashback logs)以及归档重做日志(archived redo log files)。这些数据文件中存放 Oracle 提供的元数据以及公共用户(在每个容器中都已知的用户),并与所有 PDB 共享。
名为 PDB$SEED 的种子 PDB 是系统提供的 PDB 模板,包含多个数据文件,你可以据此快速创建新的 PDB。
常规 PDB 包含多个数据文件,保存支撑某个应用所需的数据与代码;例如,人力资源(Human Resources)应用。用户只与 PDB 交互,不会直接与种子 PDB 或根容器交互。你可以在一个 CDB 中创建多个 PDB。多租户架构的目标之一是每个 PDB 与一个应用一一对应。
应用容器是 CDB 内部的一种可选的 PDB 组合,用于存放某个应用的数据。创建应用容器的目的,是拥有单一的主应用定义(single master application definition)。一个 CDB 中可以存在多个应用容器。
数据库被划分为称为表空间(tablespaces)的逻辑存储单元,整体上存放数据库的全部数据。每个表空间对应一个或多个数据文件。根容器与常规 PDB 通常具备 SYSTEM、SYSAUX、USERS、TEMP 以及(在常规 PDB 中可选的)UNDO 表空间。种子 PDB 具有 SYSTEM、SYSAUX、TEMP,以及可选的 UNDO 表空间。
更多信息,参见《多租户架构简介》(Introduction to the Multitenant Architecture)。
Database System Files
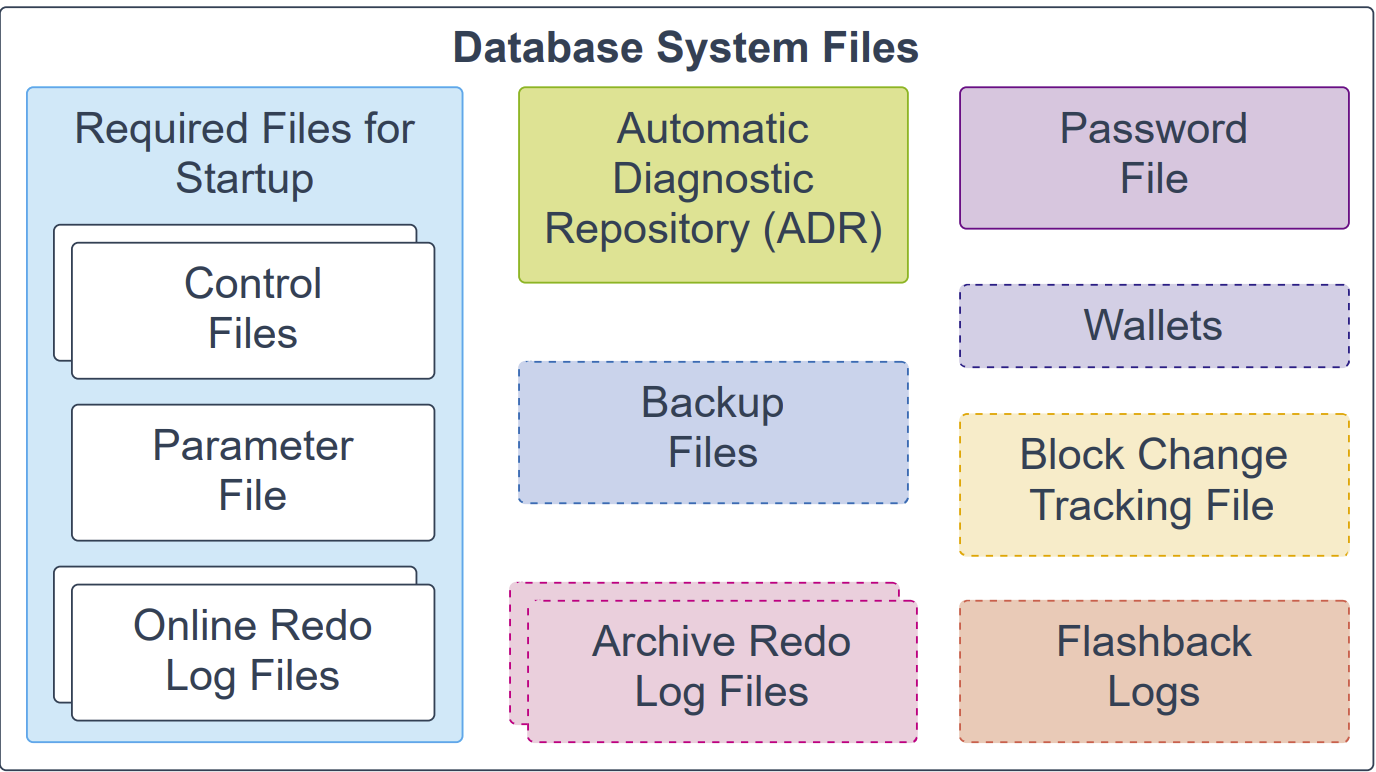
以下数据库系统文件在 Oracle 数据库运行期间使用,并存放于数据库服务器上。注意:数据文件(data files)属于数据库容器的物理文件,此处不作描述。
控制文件(Control files):必需文件,存放关于数据文件与联机重做日志文件的元数据(如名称与状态)。数据库实例在打开数据库时需要这些信息。控制文件还包含在数据库未打开时也必须可访问的元数据。强烈建议在数据库服务器上保存控制文件的多个副本,以提高可用性。
参数文件(Parameter file):必需文件,定义数据库实例启动时的配置。可为初始化参数文件(pfile)或服务器参数文件(spfile)。
联机重做日志文件(Online redo log files):必需文件,用于按发生顺序记录对数据库的更改,并用于数据恢复。
自动诊断仓库(ADR, Automatic Diagnostic Repository):基于文件的诊断数据存储库,保存跟踪(trace)、转储(dump)、警示日志(alert log)、健康监视器报告等。其目录结构在多实例、多产品间统一。数据库、Oracle ASM、监听器、Oracle Clusterware 以及其他 Oracle 产品/组件都会将诊断数据存放在 ADR 中;每个产品的每个实例都在 ADR 内其各自的 home 目录下保存诊断数据。
备份文件(Backup files):可选文件,用于数据库恢复。通常在介质故障或用户误操作导致原始文件损坏或删除时,从备份文件进行还原。
归档重做日志文件(Archived redo log files):可选文件,持续记录由数据库实例生成的数据更改历史。配合数据库备份,可用于恢复丢失的数据文件,即归档日志使被还原的数据文件得以进一步恢复。
口令文件(Password file):可选文件,使具有 SYSDBA、SYSOPER、SYSBACKUP, SYSDG, SYSKM, SYSRAC, SYSASM 角色的用户能够远程连接到数据库实例并执行管理任务。
钱包(Wallets):在大规模场景中,应用通过口令凭据连接数据库时,可将此类凭据存放在客户端的 Oracle Wallet 中。Oracle 钱包是用于存放认证与签名凭据的安全软件容器。常见钱包包括:用于用户凭据的 Oracle Wallet、用于透明数据加密(TDE)的 Encryption Wallet、以及用于数据库备份云模块的 Oracle Public Cloud (OPC) Wallet。钱包为可选,但推荐使用。
块更改跟踪文件(Block change tracking file):通过记录发生变化的数据块,加速增量备份。在增量备份期间,Oracle Recovery Manager(RMAN)无需扫描全部数据块即可识别需要备份的已变更块。该文件为可选。
闪回日志(Flashback logs):闪回数据库(Flashback Database)在效果上类似传统的时间点恢复,允许将数据库还原到最近过去的某个时刻。闪回数据库使用自身的日志机制,在快速恢复区创建并存放闪回日志。仅当存在闪回日志时,才能使用闪回数据库功能;要利用该特性,必须事先配置数据库生成闪回日志。闪回日志为可选。
控制文件、联机重做日志文件与归档重做日志文件均可进行多路复用(multiplexing),即在不同位置自动维护两个或更多相同的副本。
数据库启动所需的必备文件为:控制文件、参数文件与联机重做日志文件。 更多信息,参见《物理存储结构(Physical Storage Structures)》。
Application Containers
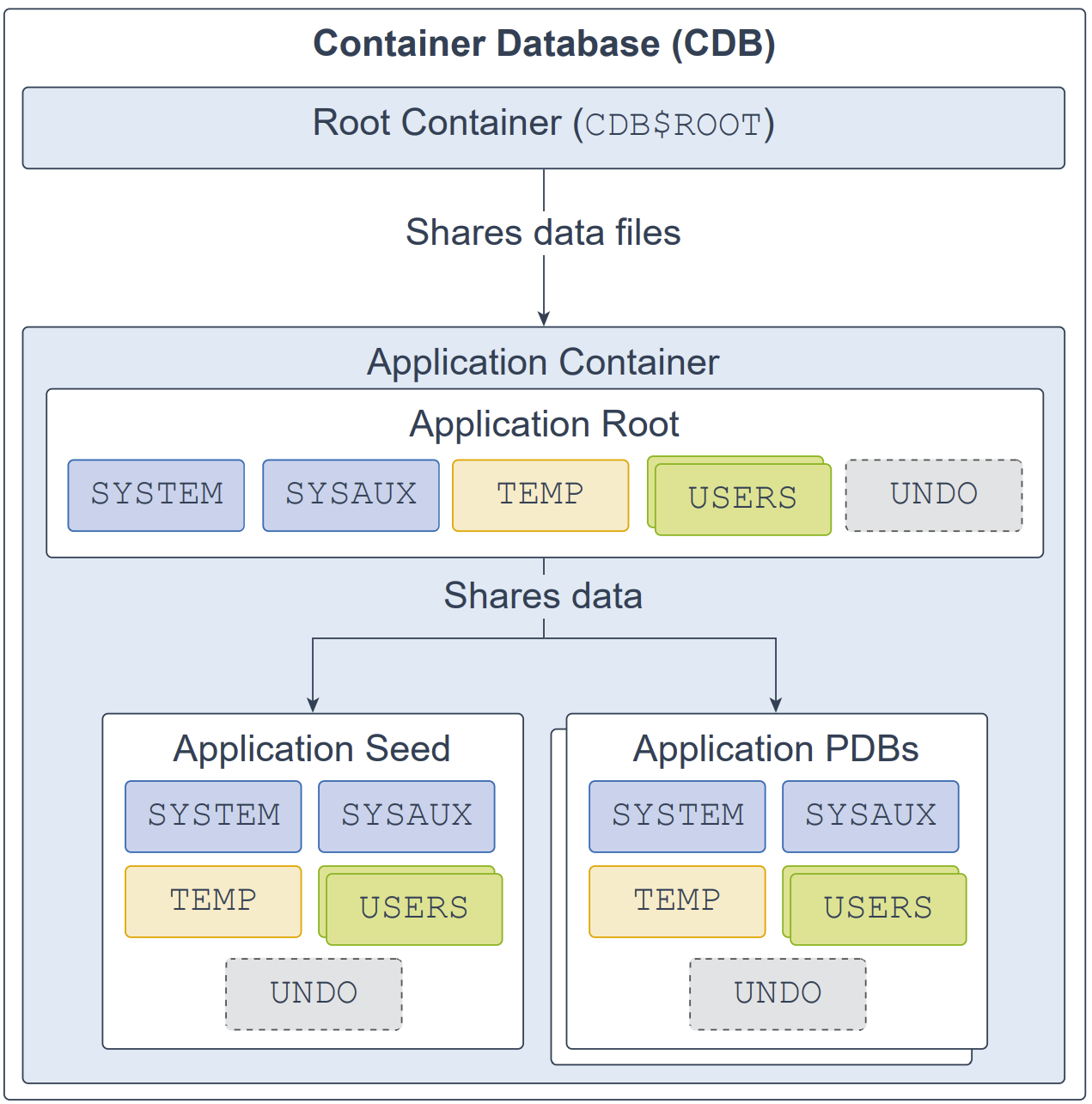
应用容器(application container)是一个可选的、由用户创建的 CDB 组件,用于为应用 PDB(application PDBs)存放数据与元数据。一个 CDB 可以包含零个或多个应用容器。一个应用容器恰好由一个应用根(application root)以及一个或多个应用 PDB构成,并插接(plug in)到 CDB 根(CDB root)。应用根隶属于 CDB 根且不属于任何其他容器,用于保存公共元数据与数据。
典型的应用会安装应用公共用户(application common users)、元数据链接公共对象(metadata-linked common objects)以及数据链接公共对象(data-linked common objects)。例如,你可以在同一个应用容器中创建多个与销售相关的 PDB,这些 PDB 共享由一组公共表及表定义构成的应用后端。
应用根(application root)、应用种子(application seed)与应用 PDB各自都包含 SYSTEM、SYSAUX、TEMP、USERS 以及可选的 UNDO 表空间。每个表空间对应一个或多个数据文件。
更多信息,参见 About Application Containers(关于应用容器)。
Automatic Diagnostic Repository (ADR)

自动诊断仓库(ADR, Automatic Diagnostic Repository)是一个系统范围的跟踪与日志集中式仓库,用于存放数据库诊断数据。其内容包括:
后台跟踪文件(Background trace files):每个数据库后台进程都可写入其关联的跟踪文件。当进程检测到内部错误时,会将错误信息转储(dump)到该文件。部分信息供数据库管理员查看,部分信息供 Oracle 支持服务使用。后台进程跟踪文件名通常包含 Oracle 系统标识符(SID)、后台进程名与操作系统进程号。例如 RECO 进程的一个跟踪文件:
mytest_reco_10355.trc。前台跟踪文件(Foreground trace files):每个服务器进程都可写入其关联的跟踪文件。当进程检测到内部错误时,会将错误信息转储到该文件。服务器进程跟踪文件名通常包含 Oracle SID、字符串
ora与操作系统进程号。例如:mytest_ora_10304.trc。转储文件(Dump files):诊断转储文件是一类特殊的跟踪文件,包含关于某一时刻的状态或结构的详细信息。转储文件通常是对某个事件的一次性诊断数据输出,而跟踪文件往往是持续输出的诊断数据。
健康监视器报告(Health monitor reports):Oracle 数据库包含名为 Health Monitor 的框架,用于对数据库执行诊断检查。健康检查可检测文件损坏、物理与逻辑块损坏、撤销与重做损坏、数据字典损坏等。检查完成后会生成发现结果报告,并在许多情况下给出解决问题的建议。
事件包(Incident packages):若需以定制方式向 Oracle 支持上传诊断数据,需先将数据收集到名为**事件包(package)**的中间逻辑结构中。事件包是在 ADR 中存放的一组元数据,指向 ADR 内外的诊断数据文件及其他文件。创建事件包时,你可选择一个或多个“问题(problem)”加入包中;随后 Support Workbench 会自动把所选问题相关的问题信息、事件(incident)信息及诊断数据(如跟踪与转储文件)加入该包。
事件转储(Incident dumps):当事件发生时,数据库会在为该事件创建的事件目录下写入一个或多个转储文件。事件转储文件名中也包含事件编号。
告警日志文件(Alert log file):数据库的告警日志是按时间顺序记录消息与错误的日志。Oracle 建议定期审阅告警日志。
更多信息,参见 Automatic Diagnostic Repository(自动诊断仓库)。
Backup Files
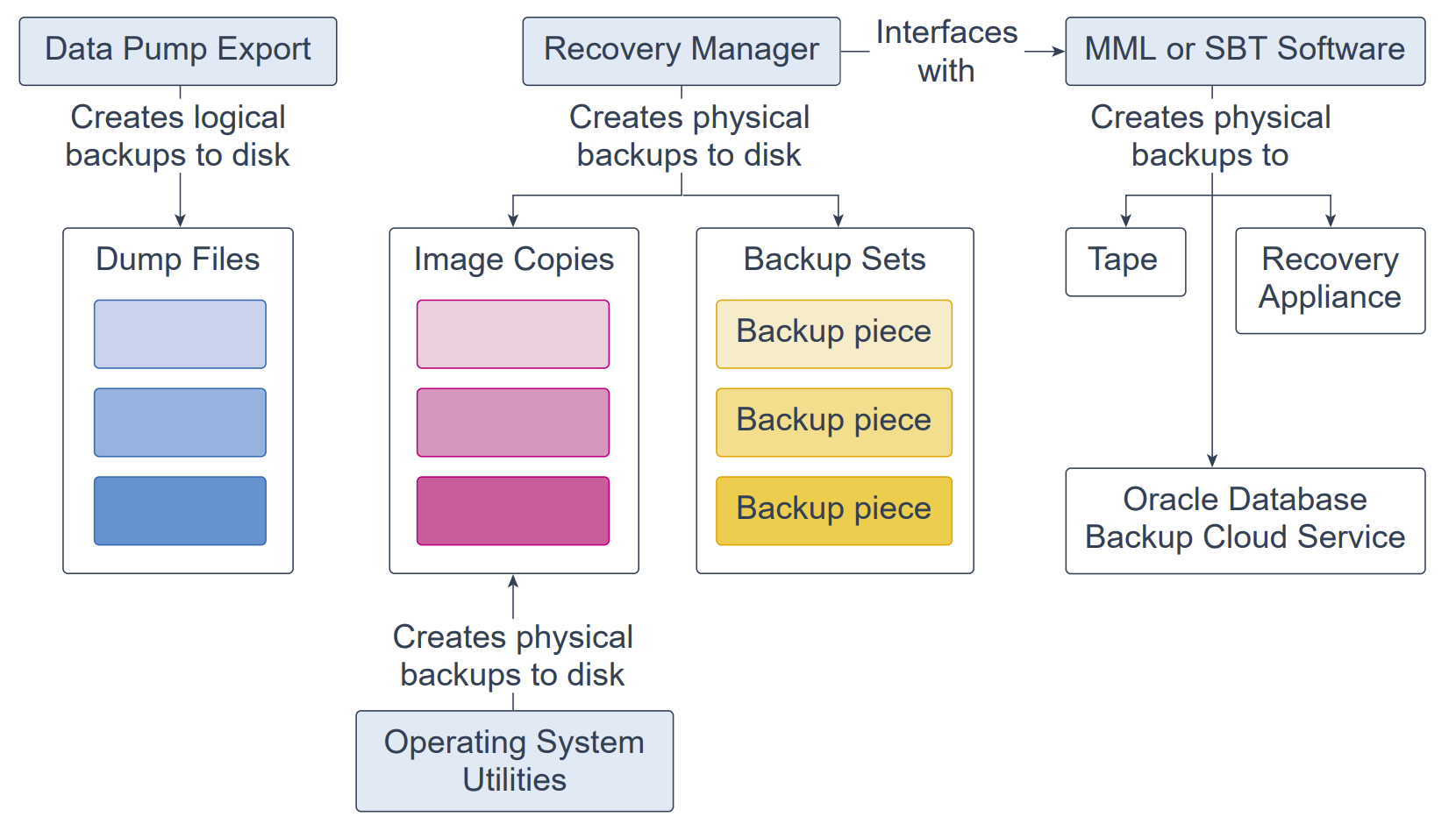
数据库备份可分为物理备份与逻辑备份。
物理备份(Physical backups):物理数据库文件的副本。可使用 Recovery Manager(RMAN)或操作系统工具制作。
逻辑备份(Logical backups):包含表、存储过程以及其他逻辑数据。可使用 Oracle 数据库工具(如 Data Pump Export)抽取逻辑数据并以二进制文件形式存储。逻辑备份可作为对物理备份的补充。
RMAN 创建的数据库备份以镜像副本或备份集两种形式保存。
镜像副本(Image copy):数据文件、控制文件或归档重做日志文件的按位(bit-for-bit)磁盘副本。既可用操作系统工具,也可用 RMAN 创建,并可用任一工具进行还原。镜像副本适合存放在磁盘上,因为它们可以增量更新并就地恢复(recover in place)。
备份集(Backup set):由 RMAN 创建的专有格式,可包含一个或多个数据文件、归档重做日志文件、控制文件或服务器参数文件(spfile)中的数据。备份集的最小单元为二进制文件,称为备份片(backup piece)。将备份写入顺序设备(如磁带机)时,RMAN 只能以备份集的形式写出。备份集的一项优势是 RMAN 采用未用块压缩(unused block compression)以节省数据文件备份空间——仅将数据文件中实际被使用的块纳入备份。此外,备份集还可压缩、加密、写入磁带,并可使用高级未使用空间压缩(数据文件副本不支持)。
RMAN 可与媒体管理库(MML, Media Management Library或 SBT(System Backup to Tape)软件对接,从而将备份写入磁带、Oracle Database Backup Cloud Service,或 Zero Data Loss Recovery Appliance(通常称为 Recovery Appliance)。
更多信息,参见: